k8s实践:Pod资源管理
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了k8s实践:Pod资源管理相关的知识,希望对你有一定的参考价值。
环境说明:| 主机名 | 操作系统版本 | ip | docker version | kubelet version | 配置 | 备注 |
|---|---|---|---|---|---|---|
| master | Centos 7.6.1810 | 172.27.9.131 | Docker 18.09.6 | V1.14.2 | 2C2G | 备注 |
| node01 | Centos 7.6.1810 | 172.27.9.135 | Docker 18.09.6 | V1.14.2 | 2C2G | 备注 |
| node02 | Centos 7.6.1810 | 172.27.9.136 | Docker 18.09.6 | V1.14.2 | 2C2G | 备注 |
?
k8s集群部署详见:Centos7.6部署k8s(v1.14.2)集群
k8s学习资料详见:基本概念、kubectl命令和资料分享
?
一、计算资源管理(Compute Resources)
1. 概念
??在配置Pod时,我们可以为其中的每个容器指定需要使用的计算资源(CPU和内存)。计算资源的配置项分为两种:Requests和Limits。Requests表示容器希望被分配到的、可完全保证的资源量(资源请求量);Limits是容器最多能使用的资源量的上限(资源限制量)。
??资源请求量能够保证Pod有足够的资源来运行,资源限制量则是防止某个Pod无限制地使用资源,导致其他Pod崩溃。
??我们创建一个pod时,可以指定容器对CPU和内存的资源请求量及资源限制量,它们并不在pod里定义,而是针对每个容器单独指定。pod对资源的请求量和限制量是它所包含的所有容器的请求量和限制量之和。
?
CPU和内存的Requests和Limits有如下特点:
- Requests和Limits都是可选的。在Pod创建和更新时,如果未设置Requests和Limits,则使用系统提供的默认值,该默认值取决于集群配置。
- 如果Requests没有配置,默认被设置等于Limits。
- 任何情况下Limits都应该设置为大于或等于Requests。
2. 查看节点资源总量
2.1 命令方式
[root@master ~]# kubectl describe nodes 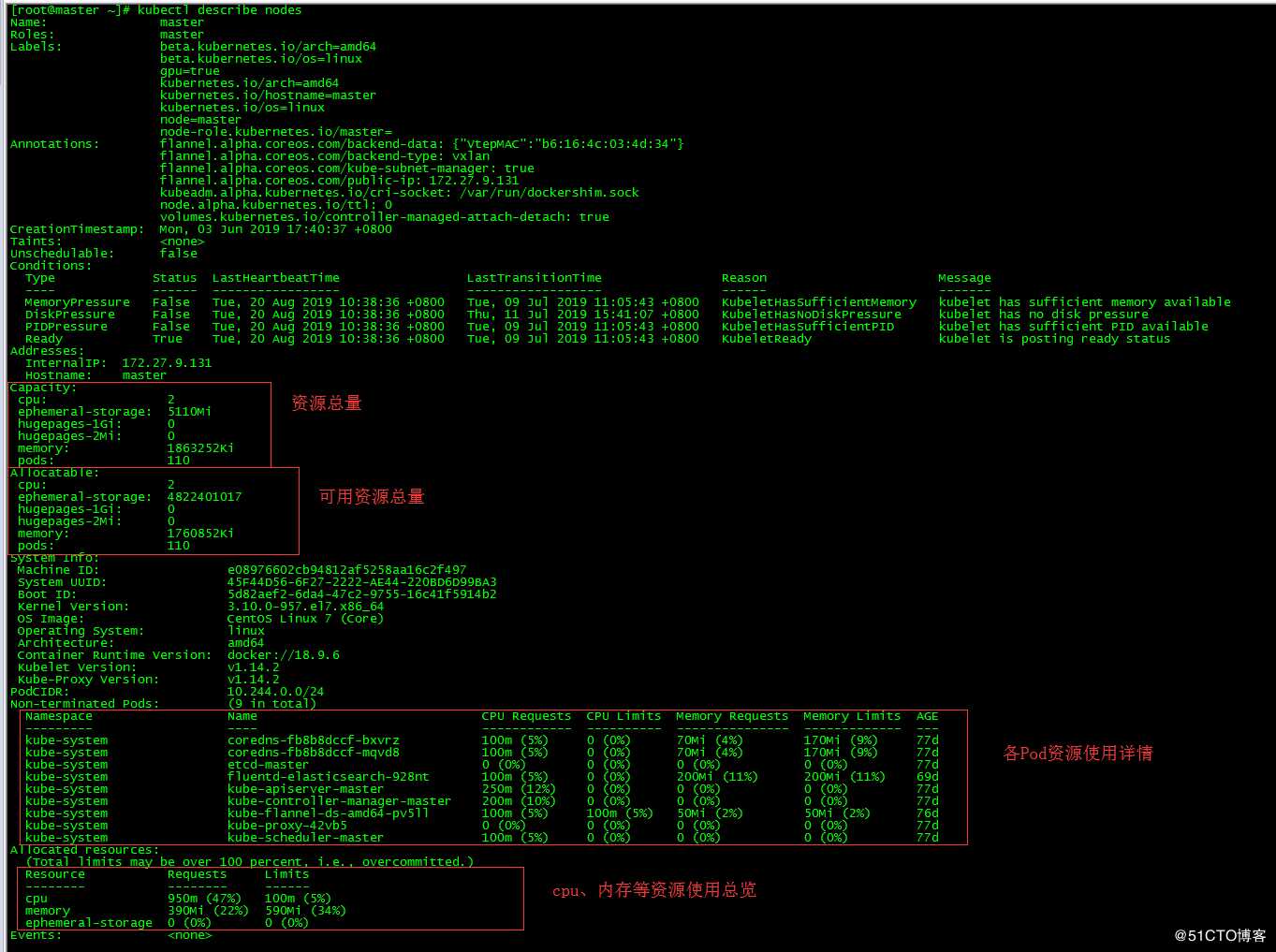
2.2 Dashboard方式
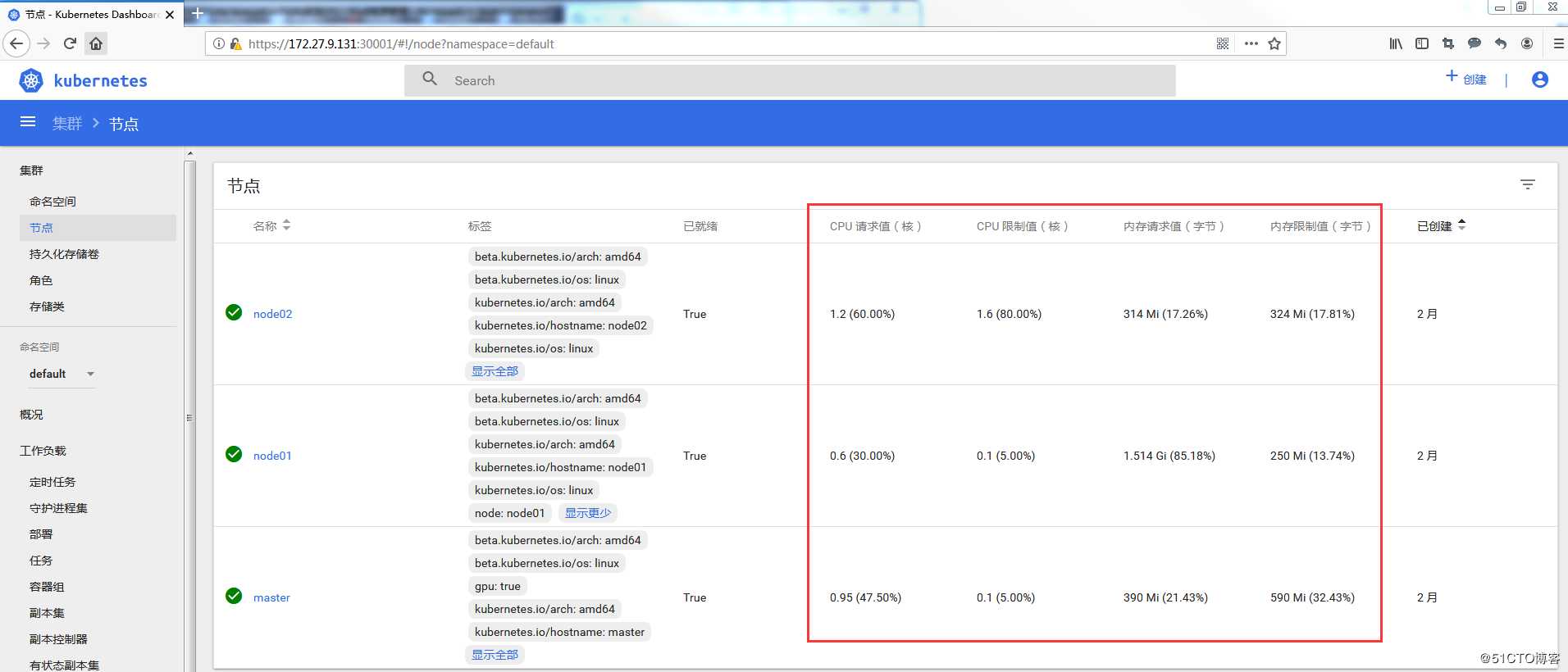
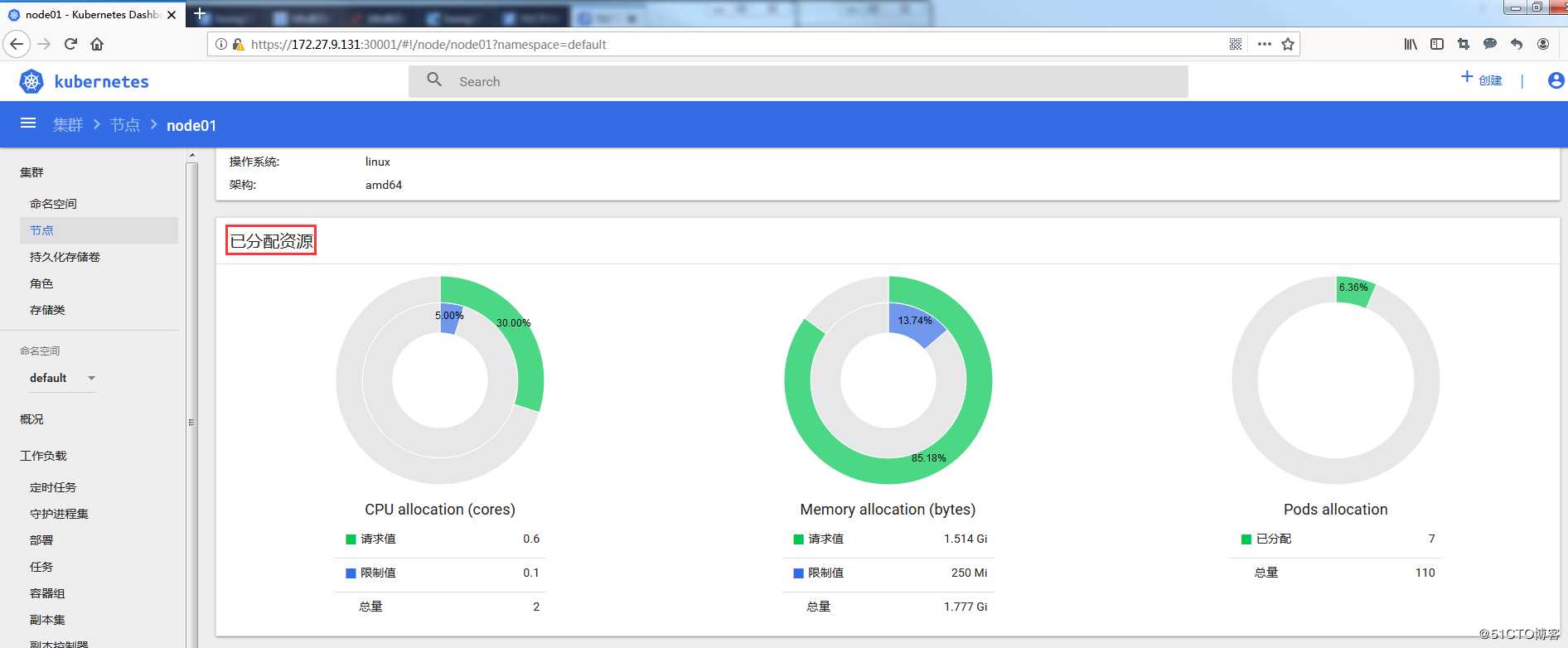
3. requests
3.1 创建包含资源requests的pod
[root@master ~]# more requests-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: requests-pod
spec:
containers:
- image: busybox
name: busybox
args:
- /bin/sh
- -c
- sleep 60000
resources:
requests: #资源申请
cpu: 500m #容器申请500毫核(一个CPU核心时间的1/2)
memory: 500Mi #容器申请500M内存
nodeName: node01
[root@master ~]# kubectl apply -f requests-pod.yaml
pod/requests-pod created在Kubernetes系统上,l个单位的CPU相当于虚拟机上的l颗虚拟CPU(vCPU)或物理机上的一个超线程(Hyperthread,或称为一个逻辑CPU),它支持分数计量方式,一个核心(1core)相当于1000个微核心(millicores),因此500m相当于是0.5个核心,即二分之一个核心。内存的计量方式与日常使用方式相同,默认单位是字节,也可以使用E,P、T、G、M和K作为单位后缀,或Ei、Pi、Ti、Gi、Mi和Ki形式的单位后缀。
3.2 查看pod
[root@master ~]# kubectl get po -o wide
[root@master ~]# kubectl describe po requests-pod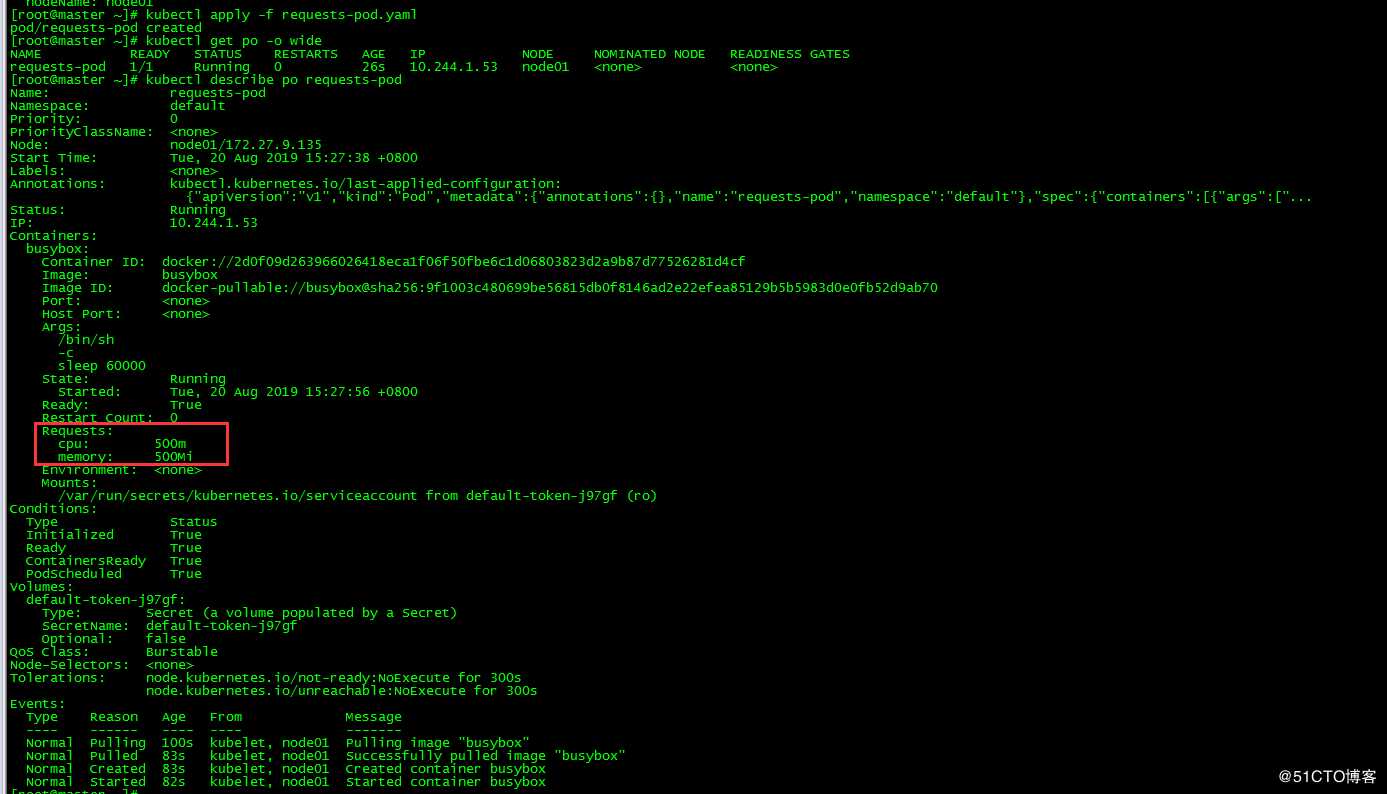
3.3 基于requests的pod调度机制
3.3.1 不指定requests
[root@master ~]# kubectl delete all --all
[root@master ~]# more deploy-busybox.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: busybox
spec:
selector:
matchLabels:
env: prod
replicas: 10
template:
metadata:
labels:
env: prod
spec:
containers:
- name: busybox
image: busybox
args:
- /bin/sh
- -c
- sleep 60000
nodeSelector:
node: node01
[root@master ~]# kubectl apply -f deploy-busybox.yaml
deployment.apps/busybox created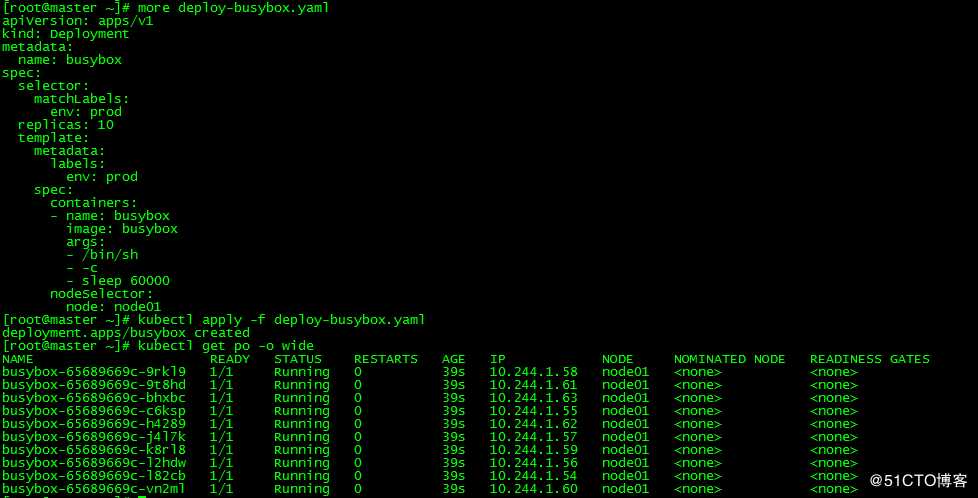
若不指定资源请求量,节点node01上可成功运行10个pod
3.3.2 OutOfmemory
[root@master ~]# more requests-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: requests-pod
spec:
containers:
- image: busybox
name: busybox
args:
- /bin/sh
- -c
- sleep 60000
resources:
requests: #资源申请
cpu: 500m #容器申请500毫核(一个CPU核心时间的1/2)
memory: 800Mi #容器申请800M内存
nodeName: node01
[root@master ~]# more requests-pod-2.yaml
apiVersion: v1
kind: Pod
metadata:
name: requests-pod-2
spec:
containers:
- image: busybox
name: busybox
args:
- /bin/sh
- -c
- sleep 60000
resources:
requests:
cpu: 500m
memory: 800Mi
nodeName: node01
[root@master ~]# kubectl apply -f requests-pod.yaml
pod/requests-pod created
[root@master ~]# kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
requests-pod 1/1 Running 0 4s 10.244.1.67 node01 <none> <none>
[root@master ~]# kubectl apply -f requests-pod-2.yaml
pod/requests-pod-2 created
[root@master ~]# kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
requests-pod 1/1 Running 0 14s 10.244.1.67 node01 <none> <none>
requests-pod-2 0/1 OutOfmemory 0 2s <none> node01 <none> <none>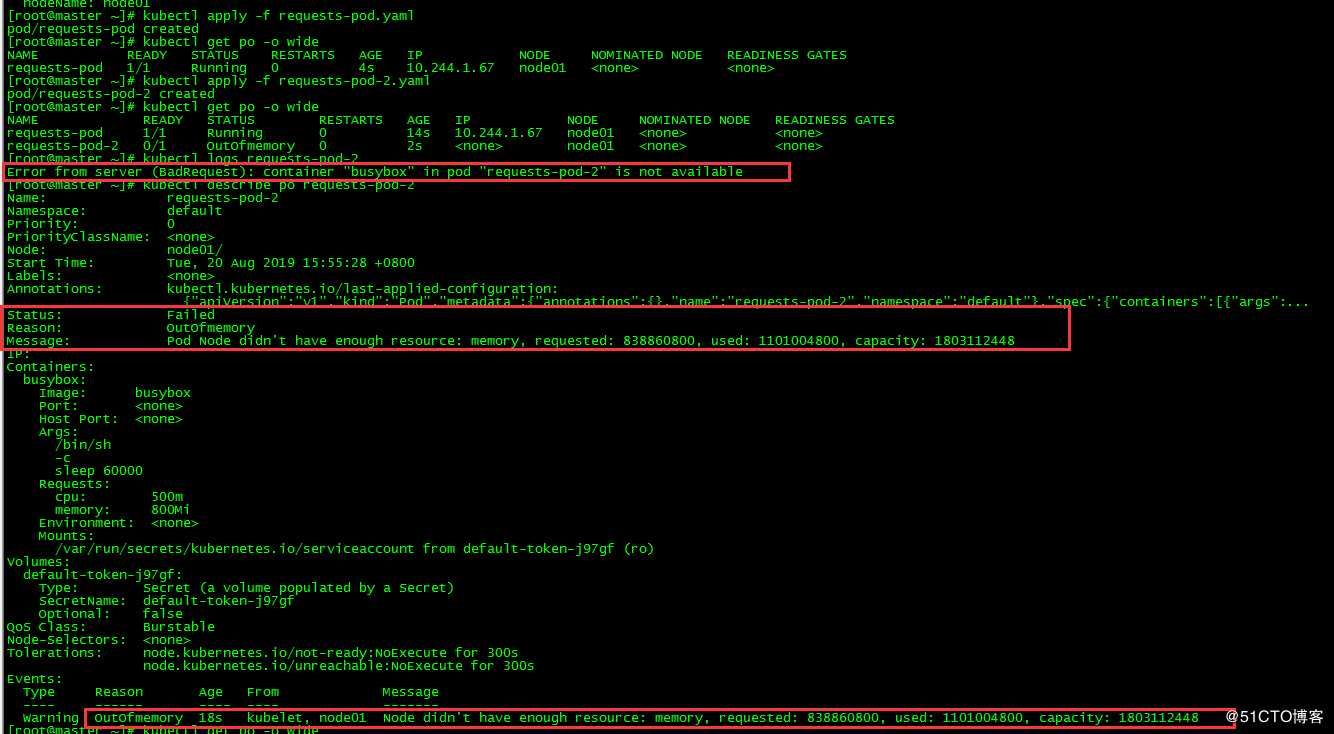
报节点node01 内存资源不足,pod requests-pod-2调度失败
3.3.3 OutOfcpu
[root@master ~]# kubectl delete all --all
[root@master ~]# more requests-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: requests-pod
spec:
containers:
- image: busybox
name: busybox
args:
- /bin/sh
- -c
- sleep 60000
resources:
requests: #资源申请
cpu: 1 #容器申请一个CPU核心时间
memory: 80Mi #容器申请80M内存
nodeName: node01
[root@master ~]# more requests-pod-2.yaml
apiVersion: v1
kind: Pod
metadata:
name: requests-pod-2
spec:
containers:
- image: busybox
name: busybox
args:
- /bin/sh
- -c
- sleep 60000
resources:
requests:
cpu: 1
memory: 80Mi
nodeName: node01
[root@master ~]# kubectl apply -f requests-pod.yaml
pod/requests-pod created
[root@master ~]# kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
requests-pod 1/1 Running 0 4s 10.244.1.68 node01 <none> <none>
[root@master ~]# kubectl apply -f requests-pod-2.yaml
pod/requests-pod-2 created
[root@master ~]# kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
requests-pod 1/1 Running 0 13s 10.244.1.68 node01 <none> <none>
requests-pod-2 0/1 OutOfcpu 0 2s <none> node01 <none> <none>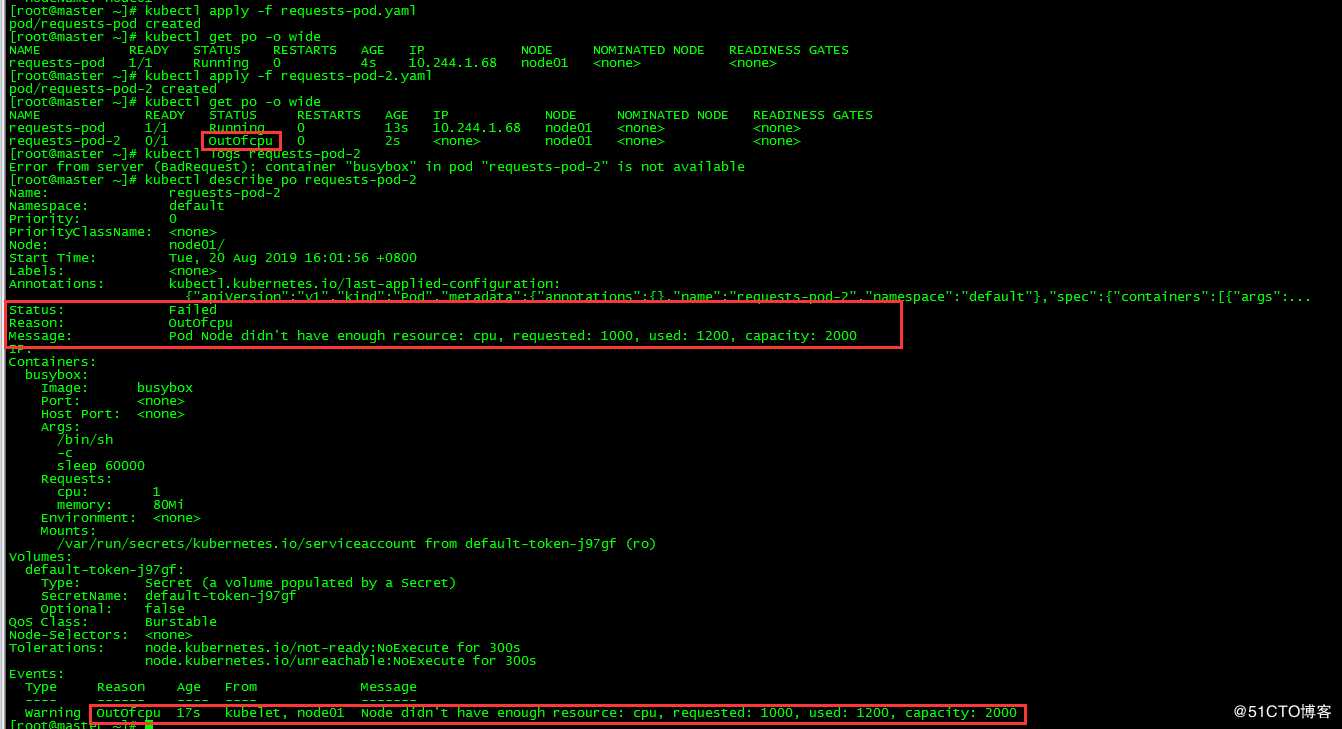
报节点node01 cpu资源不足,pod requests-pod-2调度失败
3.3.4 结论
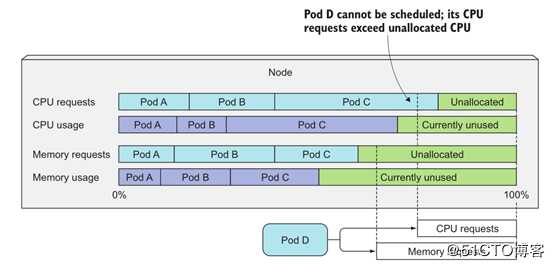
- 调度器在调度时并不关注各类资源在当前时刻的实际使用量(node01可以同时运行10个busybox pod)
- 调度器只关心节点上部署的所有pod的资源申请量之和(超出时就会报OutOfmemory或OutOfcpu)
- 尽管现有pods的资源实际使用量可能小于它的申请量,但如果使用基于实际资源消耗量的调度算法将打破系统为这些已部署成功的pods提供足够资源的保证
?
4. limits
4.1 创建包含资源limits的pod
[root@master ~]# more limited-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: limited-pod
spec:
containers:
- image: busybox
command: ["sleep","600000"]
name: busybox
resources:
requests: #资源申请
cpu: 200m #容器申请200毫核(一个CPU核心时间的1/5)
memory: 80Mi #容器申请80M内存
limits: #资源限制
cpu: 2 #容器最大允许使用2核CPU
memory: 2Gi #容器最大允许使用2GB内存
nodeName: node01
[root@master ~]# kubectl apply -f limited-pod.yaml
pod/limited-pod created
[root@master ~]# kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
limited-pod 1/1 Running 0 12s 10.244.1.75 node01 <none> <none>创建pod limited-pod,资源限制为cpu 2核,内存2G
4.2 limits overcommitted
4.2.1 创建pod
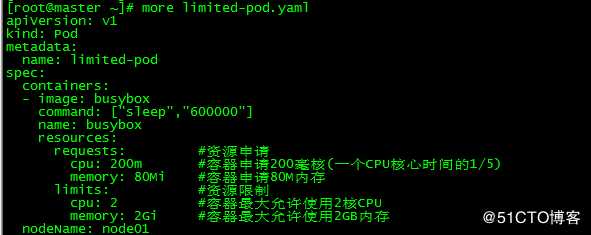
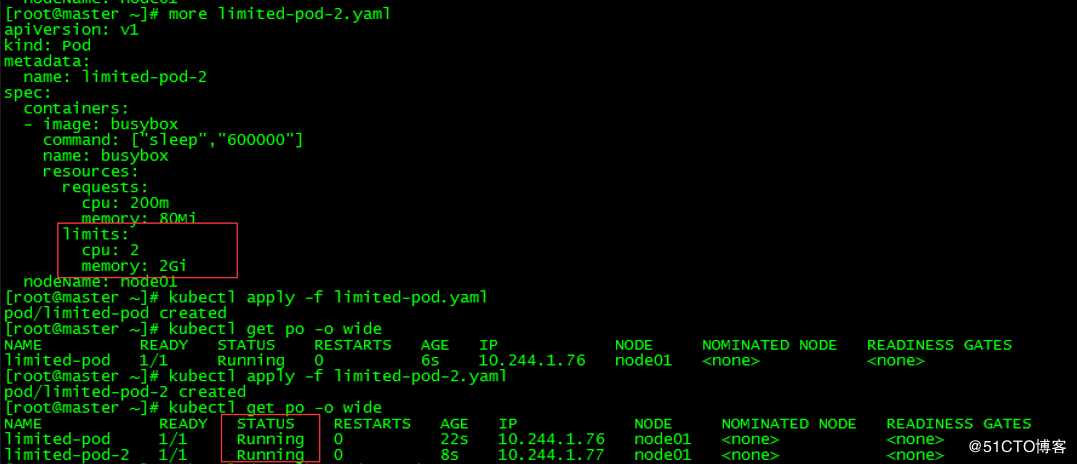
创建limited-pod和limited-pod-2,cpu为2核,内存2G,pod运行正常。
4.2.2 查看node01资源使用
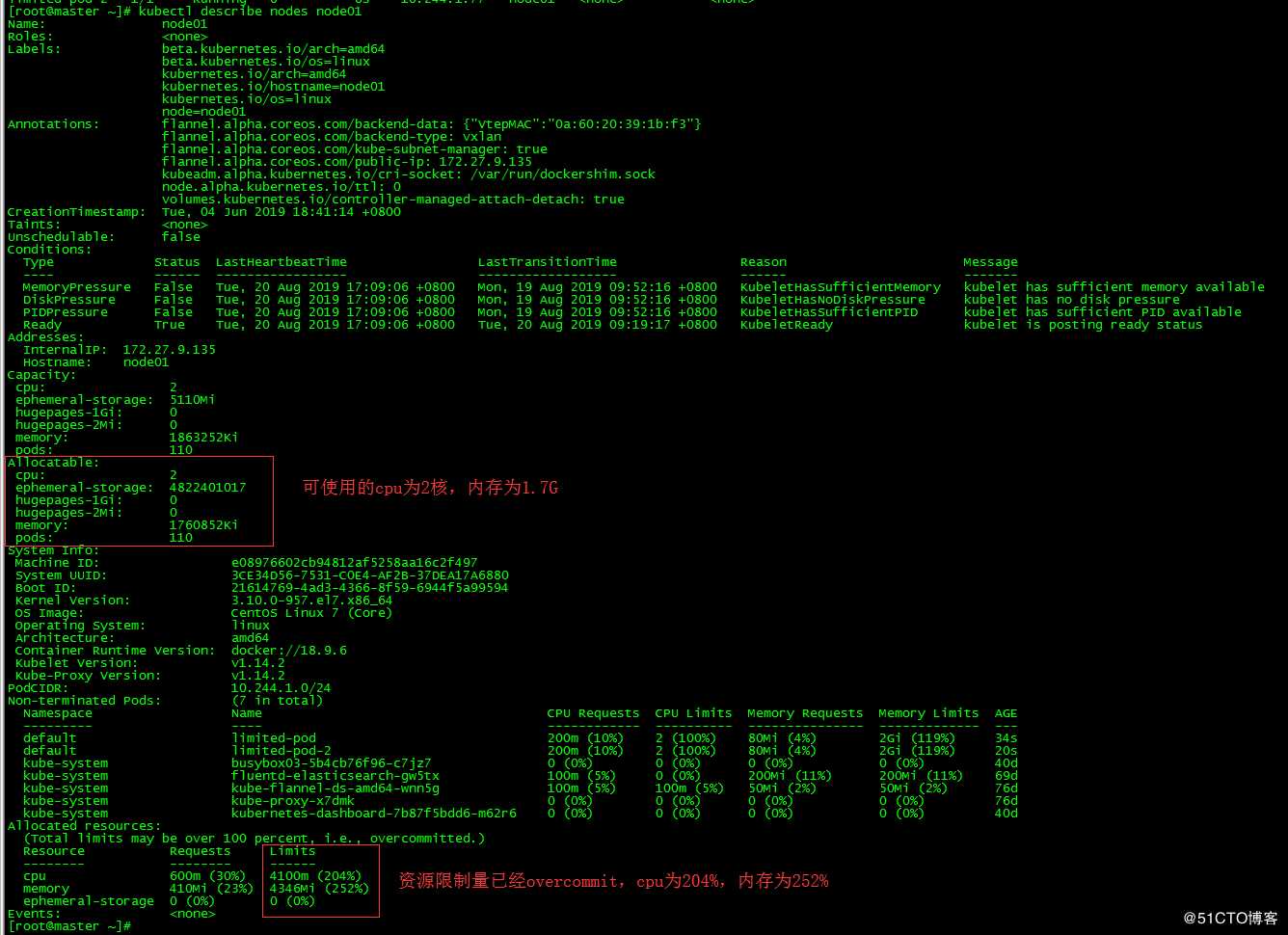
4.2.3 结论
- 节点上所有pod的资源limits之和可以超过节点资源总量的100%
- requests不同的是,limits并不会影响pod的调度结果

二、服务质量管理(QoS)
1. 概念
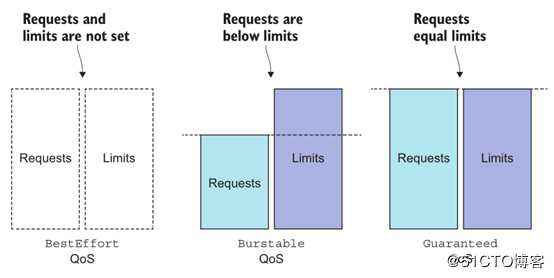
??前面曾提到过,Kubernetes允许节点资源对Limits的过载使用,这意味着节点无法同时满足其上的所有Pod对象以资源满载的方式运行。于是,在内存资源紧缺时,应该以何种次序先后终止哪些Pod对象?Kubernetes无法自行对此做出决策,它需要借助于Pod对象的优先级完成判定。根据Pod对象的requests和limits属性,Kubernetes将Pod象归类到BestEffort、Burstable和Guaranteed三个服务质量(Quality of Service,QoS)类别下,具体说明如下。
Guaranteed:每个容器都为CPU资源设置了具有相同值的requests和limits属性,以及每个容器都为内存资源设置了具有相同值的requests和limits属性的Pod资源会自动归属于此类别,这类Pod资源具有最高优先级。
Burstable:至少有一个容器设置了CPU或内存资源requests属性,但不满足Guaranteed类别要求的Pod资源将自动归属于此类别,它们具有中等优先级。
- BestEffort:未为任何一个容器设置requests或limits属性的Pod资源将自动归属于此类别,它们的优先级为最低级别。
在一个overcommitted的系统,QoS等级决定着哪个容器第一个被杀掉,这样释放出的资源可以提供给高优先级的pod使用。BestEffort等级的pod首先被杀掉,其次是Burstable pod, 最后是Guaranteed pod。Guaranteed pod只有在系统进程需要内存时才会被杀掉。
2. 定义QoS
资源的requests、limits和QoS等级
3. 相同等级QoS容器处理
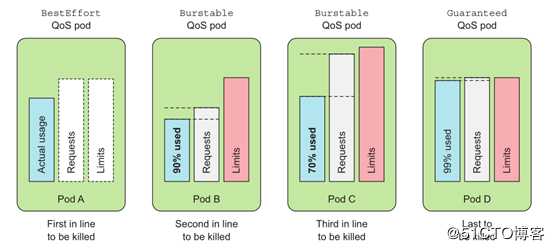
每个行状态容器都有其OOM得分,得分越高越会被优先杀死。OOM得分主要根据两个纬度进行计算:由QoS类别继承而来的默认分值和容器的可用内存资源比例。同等类别的Pod资源的默认分值相同,同等级别优先级的Pod资源在OOM时,与自身的requests属性相比,其内存占用比例最大的Pod对象将被首先杀死。
三、资源配置范围管理(LimitRange)
1. 概念
??默认情况下,Kubernetes中所有容器都没有任何CPU和内存限制。LimitRange用来给Namespace增加一个资源限制,包括最小、最大和默认资源。
2. 为什么需要LimitRange
??为单个容器设置资源requests和limits很有必要性:1.提升QoS等级,防止在OOM时被首先kill;2.默认情况下Pod会以无限制的CPU和内存运行,很有可能因故吞掉所在工作节点上的所有可用计算资源。
??通过配置Pod的计算资源Requests和Limits,我们可以限制Pod的资源使用,但对于Kubemetes集群管理员而言,配置每一个Pod的Requests和Limits是烦琐且限制性过强的。更多时,我们需要的是对集群内Requests和Limits的配置做一个全局的统一的限制。
3 创建LimitRange
[root@master ~]# more limits.yaml
apiVersion: v1
kind: LimitRange
metadata:
name: limitrange
spec:
limits:
- type: Pod #指定整个pod的资源limits
min: #pod中所有容器的Requests值的总和的下限
cpu: 50m
memory: 5Mi
max: #pod中所有容器的Limits值的总和的上限
cpu: 1
memory: 1Gi
- type: Container #指定容器的资源限制
defaultRequest: #容器Requests默认值
cpu: 100m
memory: 10Mi
default: #容器Limits默认值
cpu: 200m
memory: 100Mi
min: #pod中所有容器的Requests值的下限
cpu: 50m
memory: 5Mi
max: #pod中所有容器的Limits值的上限
cpu: 1
memory: 1Gi
maxLimitRequestRatio: #每种资源Requests与Limits的最大比值
cpu: 4
memory: 10
- type: PersistentVolumeClaim #指定请求PVC存储容量的最小值和最大值
min:
storage: 1Gi
max:
storage: 10Gi
[root@master ~]# kubectl apply -f limits.yaml
limitrange/limitrange createdLimitRange资源支持限制Container、Pod和PersistentVolumeClaim三种资源对象的系统资源用量
4. 查看LimitRange
[root@master ~]# kubectl describe limitranges limitrange 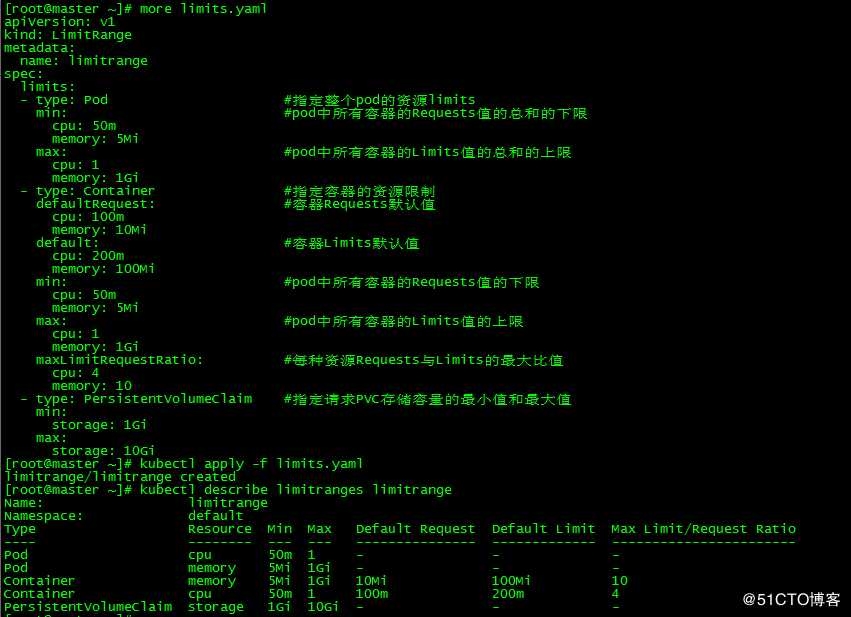
5. LimitRange测试
5.1 requests和limits默认值
新建pod
[root@master ~]# more default.yaml
apiVersion: v1
kind: Pod
metadata:
name: default-pod
spec:
containers:
- image: busybox
name: busybox
args:
- /bin/sh
- -c
- sleep 60000
[root@master ~]# kubectl apply -f default.yaml
pod/default-pod created
[root@master ~]# kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
default-pod 1/1 Running 0 8s 10.244.2.43 node02 <none> <none>
limited-pod 1/1 Running 1 22h 10.244.1.81 node01 <none> <none>
limited-pod-2 1/1 Running 1 22h 10.244.1.82 node01 <none> <none>新建pod default-pod,yaml中未指定requests和limits
查看pod
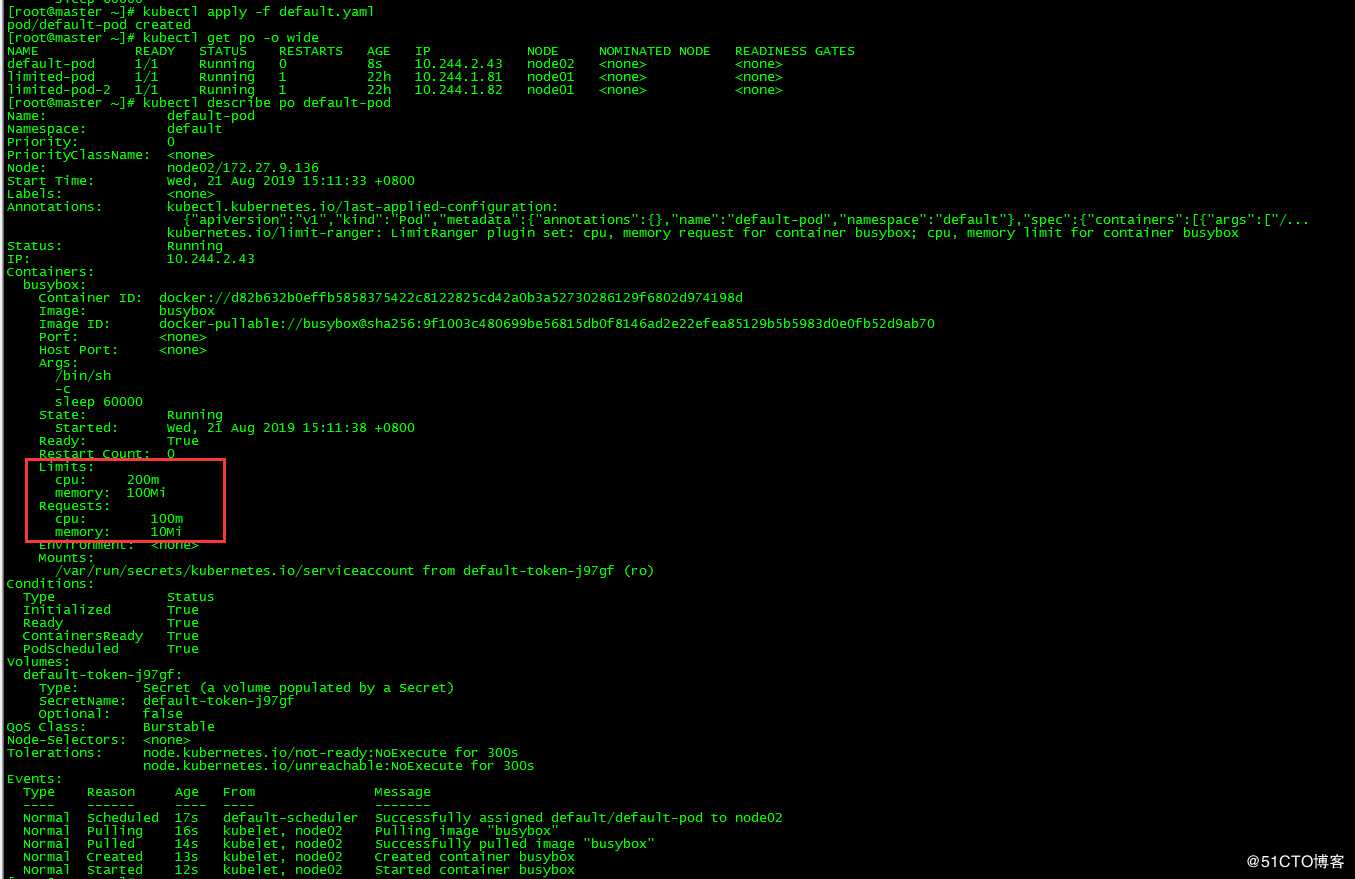
容器的requests和limits与我们在LimitRange对象中设置的一致。
5.2 强制限制
5.2.1 cpu超限制
[root@master ~]# kubectl run cpu-over --image=busybox --restart=Never --requests=‘cpu=1200m,memory=30Mi‘ sleep 6000
The Pod "cpu-over" is invalid: spec.containers[0].resources.requests: Invalid value: "1200m": must be less than or equal to cpu limit5.2.2 内存超限制
[root@master ~]# kubectl run cpu-over --image=busybox --restart=Never --requests=‘cpu=200m,memory=300Mi‘ sleep 6000
The Pod "cpu-over" is invalid: spec.containers[0].resources.requests: Invalid value: "300Mi": must be less than or equal to memory limit
四、资源配额管理(ResourceQuota)
1. 概念
??Kubemetes可以通过存活探针(liveness probe)检查容器是否还在运行。可以为pod中的每个容器单独指定存活探针。如果探测失败,Kubemetes将定期执行探针并重新启动容器。
??资源配额(Resource Quotas)是用来限制用户资源用量的一种机制,限制Pod的请求不会超过配额,需要在namespace中创建一个ResourceQuota对象
资源配额类型:
- 计算资源。包括 cpu 和 memory
- 存储资源。包括存储资源的总量以及指定 storage class 的总量
- 对象数。即可创建的对象的个数
2. ResourceQuota作用
??尽管LimitRange资源能限制单个容器、Pod及PVC等相关计算资源或存储资源的用量,但用户依然可以创建数量众多的此类资源对象进而侵占所有的系统资源。于是,Kubernetes提供了ResourceQuota资源用于定义名称空间的对象数量或系统资源配额。
3. 为CPU和内存创建ResourceQuota
[root@master ~]# more quota-cpu-memory.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: cpu-and-mem
spec:
hard:
requests.cpu: 1
requests.memory: 1Gi
limits.cpu: 1500m
limits.memory: 1500Mi
[root@master ~]# kubectl apply -f quota-cpu-memory.yaml
resourcequota/cpu-and-mem created
LimitRange应用于单独的pod,ResourceQuota应用于命名空间中所有的pod
3.1 查看ResourceQuota
[root@master ~]# kubectl describe resourcequotas cpu-and-mem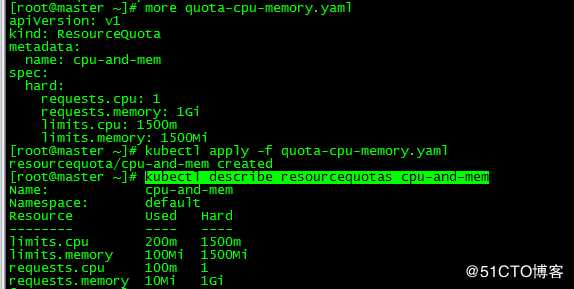
3.2 resourcequota测试
[root@master ~]# kubectl run quota-test --image=busybox --limits=‘cpu=200m,memory=90Mi‘ --replicas=10 sleep 6000
kubectl run --generator=deployment/apps.v1 is DEPRECATED and will be removed in a future version. Use kubectl run --generator=run-pod/v1 or kubectl create instead.
deployment.apps/quota-test created
[root@master ~]# kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
default-pod 1/1 Running 0 31m 10.244.2.52 node02 <none> <none>
quota-test-5d4f79c664-2tq66 1/1 Running 0 5m44s 10.244.1.90 node01 <none> <none>
quota-test-5d4f79c664-cvptj 1/1 Running 0 5m44s 10.244.0.68 master <none> <none>
quota-test-5d4f79c664-ph79j 1/1 Running 0 5m44s 10.244.2.64 node02 <none> <none>
quota-test-5d4f79c664-tvwpz 1/1 Running 0 5m44s 10.244.2.65 node02 <none> <none>发现只运行了4个pod,原因是requests的cpu为200(requests值未设置时与limits相同),resourcequotas中requests.cpu的限制值为1000m,系统之前使用了100m(default-pod),故只有900m可用,所以最多只能新建4个pod
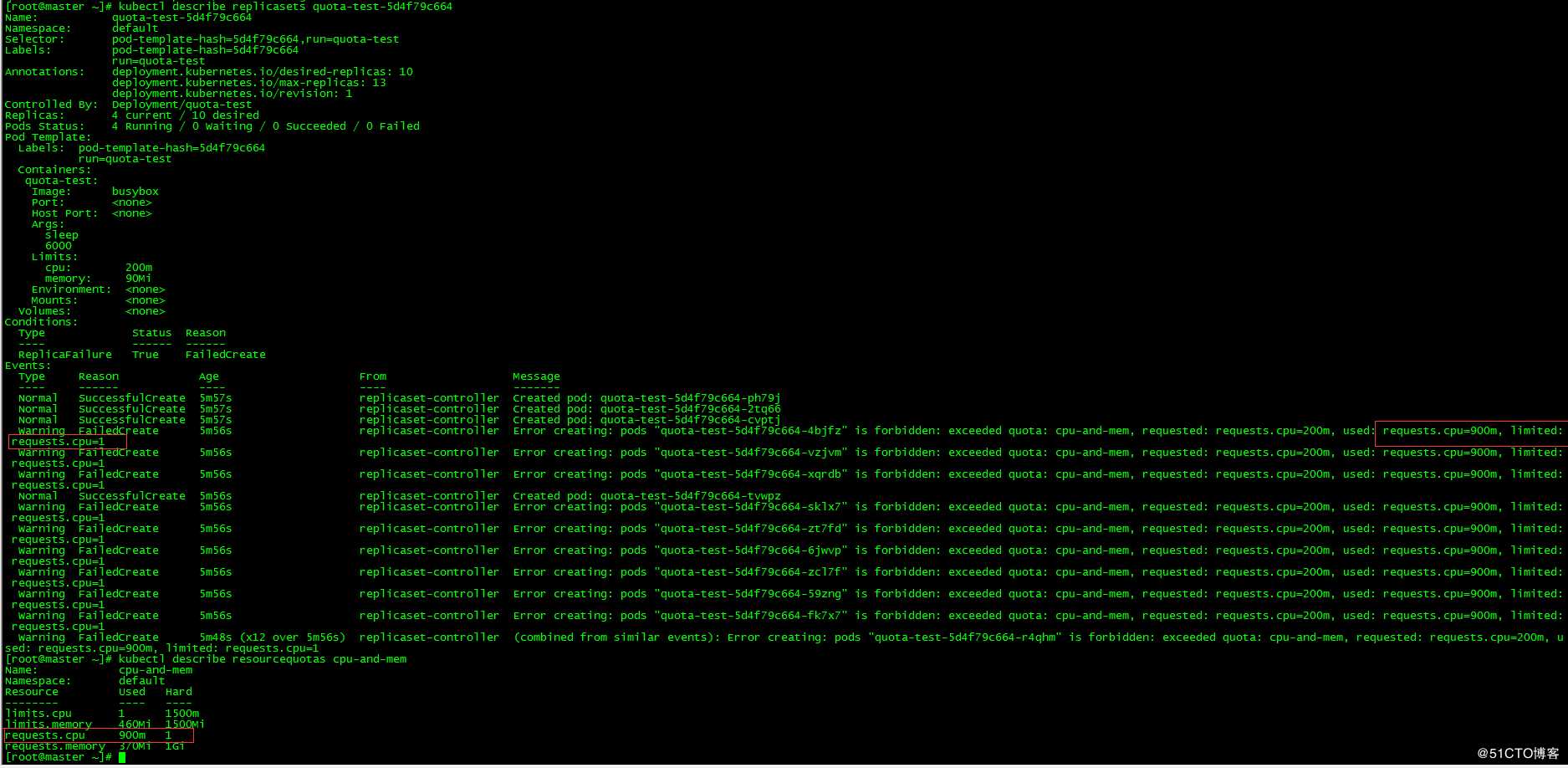
4. 限制可创建对象的个数
[root@master ~]# more quota-count.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: count-quota
spec:
hard:
pods: 10
replicationcontrollers: 5
secrets: 10
configmaps: 10
persistentvolumeclaims: 5
services: 5
services.loadbalancers: 1
services.nodeports: 2
ssd.storageclass.storage.k8s.io/persistentvolumeclaims: 2
[root@master ~]# kubectl apply -f quota-count.yaml
resourcequota/count-quota created该命名空间最多创建10个pod、5个Replication Controller、10个Secret、10个ConfigMap、4个PVC、5个Service、1个LoadBalancer、2个NodePort和2个StorageClass为ssd的PVC。
| pod | Replication Controller | Secret | ConfigMap | PVC | Service | LoadBalancer | NodePort | ssd PVC |
|---|---|---|---|---|---|---|---|---|
| 10 | 5 | 10 | 10 | 4 | 5 | 1 | 2 | 2 |
4.1 查看ResourceQuota
[root@master ~]# kubectl describe resourcequotas count-quota 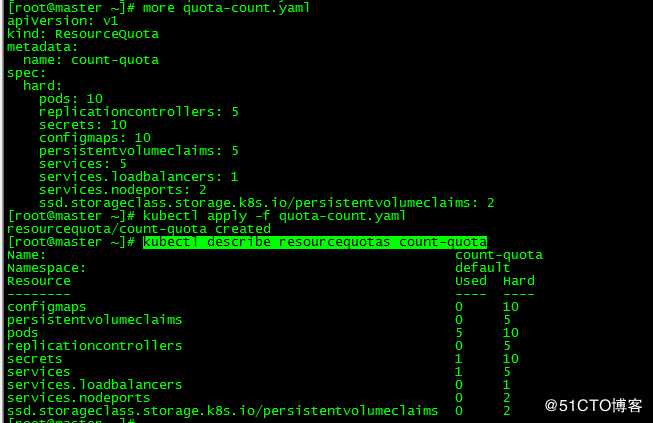
4.2 resourcequota测试
[root@master ~]# kubectl create service nodeport nodeport01 --tcp=5678:8080
service/nodeport01 created
[root@master ~]# kubectl create service nodeport nodeport02 --tcp=5678:8081
service/nodeport02 created
[root@master ~]# kubectl create service nodeport nodeport03 --tcp=5678:8082
Error from server (Forbidden): services "nodeport03" is forbidden: exceeded quota: count-quota, requested: services.nodeports=1, used: services.nodeports=2, limited: services.nodeports=2services.nodeports只能创建2个,当创建第三个时报错。

5. 特定的pod状态或者QoS等级指定配额
[root@master ~]# more quota-scoped.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: scoped-quota
spec:
scopes:
- BestEffort
- NotTerminating
hard:
pods: 4
[root@master ~]# kubectl apply -f quota-scoped.yaml
resourcequota/scoped-quota created这个quota只会应用于拥有BestEffort QoS以及没有设置有效期的pod上,这样的pod只允许存在4个。
5.1 查看ResourceQuota
[root@master ~]# kubectl describe resourcequotas scoped-quota 
resourcequota测试思路同cpu-and-mem和count-quota,这里不再赘述。
?
?
本文所有脚本和配置文件已上传github:https://github.com/loong576/k8s-Managing-pods-computational-resources.git
以上是关于k8s实践:Pod资源管理的主要内容,如果未能解决你的问题,请参考以下文章