K8s落地实践之旅 —— Pod(豌豆荚)
Posted Albert Edison
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了K8s落地实践之旅 —— Pod(豌豆荚)相关的知识,希望对你有一定的参考价值。
文章目录
✨ 前言
本章将学习 K8s 的架构及工作流程,重点介绍如何使用 Workload 管理业务应用的生命周期,实现服务不中断的滚动更新,通过服务发现和集群内负载均衡来实现集群内部的服务间访问,并通过 ingress 实现外部使用域名访问集群内部的服务。
学习过程中会逐步对 Django 项目做 k8s 改造,从零开始编写所需的资源文件。
通过本章的学习,能够会掌握高可用 k8s 集群的搭建,同时 Django demo 项目已经可以利用 k8s 的控制器、服务发现、负载均衡、配置管理等特性来实现生命周期的管理。
1. 认识k8s
纯容器模式的问题:
- 业务容器数量庞大,哪些容器部署在哪些节点,使用了哪些端口,如何记录、管理,需要登录到每台机器去管理?
- 跨主机通信,多个机器中的容器之间相互调用如何做,iptables 规则手动维护?
- 跨主机容器间互相调用,配置如何写?写死固定IP+端口?
- 如何实现业务高可用?多个容器对外提供服务如何实现负载均衡?
- 容器的业务中断了,如何可以感知到,感知到以后,如何自动启动新的容器?
- 如何实现滚动升级保证业务的连续性?
- …等等
🍑 容器调度管理平台
2017 年开始 Kubernetes 凭借强大的容器集群管理功能, 逐步占据市场,目前在容器编排领域一枝独秀
🍑 架构图
如何设计一个容器管理平台?
- 集群架构,管理节点分发容器到数据节点
- 如何部署业务容器到各数据节点
- N 个数据节点,业务容器如何选择部署在最合理的节点
- 容器如何实现多副本,如何满足每个机器部署一个容器的模型
- 多副本如何实现集群内负载均衡
分布式系统,两类角色:管理节点和工作节点

🍑 核心组件
-
ETCD:分布式高性能键值数据库,存储整个集群的所有元数据
-
ApiServer:API服务器,集群资源访问控制入口,提供 restAPI 及安全访问控制
-
Scheduler:调度器,负责把业务容器调度到最合适的 Node 节点
-
Controller Manager:控制器管理,确保集群资源按照期望的方式运行
- Replication Controller
- Node controller
- ResourceQuota Controller
- Namespace Controller
- ServiceAccount Controller
- Token Controller
- Service Controller
- Endpoints Controller
-
kubelet:运行在每个节点上的主要的 “节点代理”,脏活累活
- pod 管理:kubelet 定期从所监听的数据源获取节点上
pod/container的期望状态(运行什么容器、运行的副本数量、网络或者存储如何配置等等),并调用对应的容器平台接口达到这个状态。 - 容器健康检查:kubelet 创建了容器之后还要查看容器是否正常运行,如果容器运行出错,就要根据 pod 设置的重启策略进行处理.
- 容器监控:kubelet 会监控所在节点的资源使用情况,并定时向 master 报告,资源使用数据都是通过 cAdvisor 获取的。知道整个集群所有节点的资源情况,对于 pod 的调度和正常运行至关重要
- pod 管理:kubelet 定期从所监听的数据源获取节点上
-
kube-proxy:维护节点中的iptables或者ipvs规则
-
kubectl:命令行接口,用于对 Kubernetes 集群运行命令
静态 Pod 的方式:
## etcd、apiserver、controller-manager、kube-scheduler
$ kubectl -n kube-system get po
systemd 服务方式:
$ systemctl status kubelet
kubectl:二进制命令行工具
🍑 理解集群资源
组件是为了支撑 k8s 平台的运行,安装好的软件。
资源是如何去使用 k8s 的能力的定义。比如,k8s 可以使用 Pod 来管理业务应用,那么 Pod 就是 k8s 集群中的一类资源,集群中的所有资源可以提供如下方式查看:
$ kubectl api-resources
如何理解 namespace:
命名空间,集群内一个虚拟的概念,类似于资源池的概念,一个池子里可以有各种资源类型,绝大多数的资源都必须属于某一个 namespace。集群初始化安装好之后,会默认有如下几个 namespace:
$ kubectl get namespaces
NAME STATUS AGE
default Active 84m
kube-node-lease Active 84m
kube-public Active 84m
kube-system Active 84m
kubernetes-dashboard Active 71m
- 所有 NAMESPACED 的资源,在创建的时候都需要指定 namespace,若不指定,默认会在 default 命名空间下
- 相同 namespace 下的同类资源不可以重名,不同类型的资源可以重名
- 不同 namespace 下的同类资源可以重名
- 通常在项目使用的时候,我们会创建带有业务含义的 namespace 来做逻辑上的整合
🍑 kubectl的使用
类似于 docker,kubectl 是命令行工具,用于与 APIServer 交互,内置了丰富的子命令,功能极其强大。
$ kubectl -h
$ kubectl get -h
$ kubectl create -h
$ kubectl create namespace -h
2. 工作流程
流程图如下:
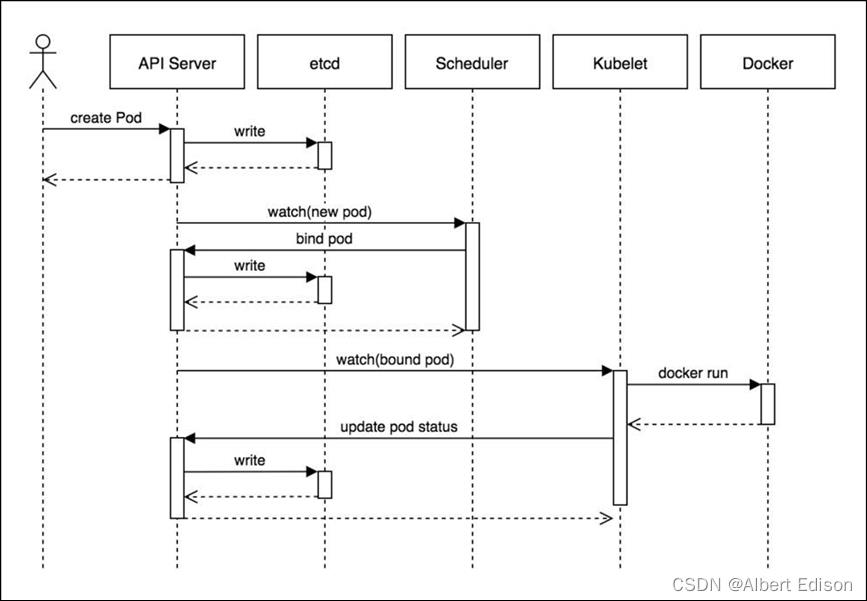
- 用户准备一个资源文件(记录了业务应用的名称、镜像地址等信息),通过调用 APIServer 执行创建 Pod
- APIServer 收到用户的 Pod 创建请求,将 Pod 信息写入到 etcd 中
- 调度器通过 list-watch 的方式,发现有新的 pod 数据,但是这个 pod 还没有绑定到某一个节点中
- 调度器通过调度算法,计算出最适合该 pod 运行的节点,并调用 APIServer,把信息更新到 etcd 中
- kubelet 同样通过 list-watch 方式,发现有新的 pod 调度到本机的节点了,因此调用容器运行时,去根据 pod 的描述信息,拉取镜像,启动容器,同时生成事件信息
- 同时,把容器的信息、事件及状态也通过 APIServer 写入到 etcd 中
🍑 架构设计的几点思考
- 系统各个组件分工明确(APIServer 是所有请求入口,CM 是控制中枢,Scheduler 主管调度,而 Kubelet 负责运行),配合流畅,整个运行机制一气呵成。
- 除了配置管理和持久化组件 ETCD,其他组件并不保存数据。意味
除ETCD外其他组件都是无状态的。因此从架构设计上对 kubernetes系统高可用部署提供了支撑。 - 同时因为组件无状态,组件的升级,重启,故障等并不影响集群最终状态,只要组件恢复后就可以从中断处继续运行。
- 各个组件和 kube-apiserver 之间的数据推送都是通过 list-watch 机制来实现。
🍑 实践集群安装
k8s 集群主流安装方式对比分析
- minikube
- 二进制安装
- kubeadm 等安装工具
具体安装方式可以参考这篇文章:
3. Pod定义
最小调度单元 Pod
docker 调度的是容器,在 k8s 集群中,最小的调度单元是 Pod(豆荚)
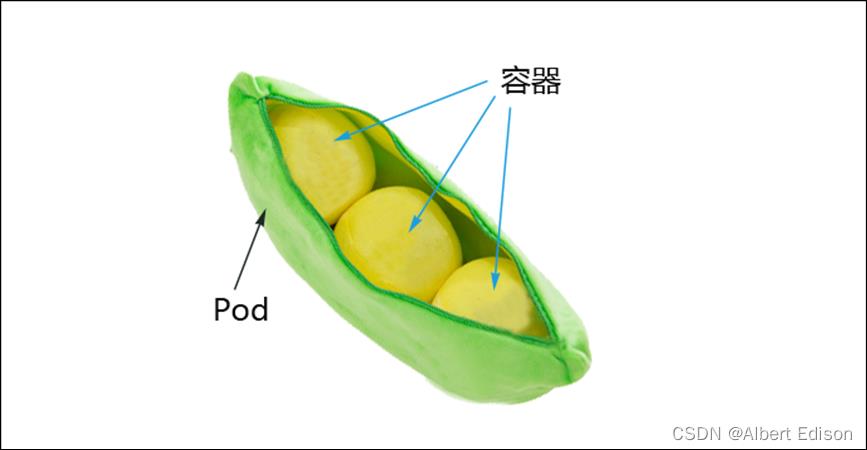
为什么引入 Pod?
-
与容器引擎解耦
Docker、Rkt。平台设计与引擎的具体的实现解耦
-
多容器共享网络 | 存储 | 进程 空间, 支持的业务场景更加灵活
🍑 使用yaml格式定义Pod
myblog/one-pod/pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: myblog
namespace: luffy
labels:
component: myblog
spec:
containers:
- name: myblog
image: 172.21.51.143:5000/myblog:v1
env:
- name: mysql_HOST # 指定root用户的用户名
value: "127.0.0.1"
- name: MYSQL_PASSWD
value: "123456"
ports:
- containerPort: 8002
- name: mysql
image: mysql:5.7
args:
- --character-set-server=utf8mb4
- --collation-server=utf8mb4_unicode_ci
ports:
- containerPort: 3306
env:
- name: MYSQL_ROOT_PASSWORD
value: "123456"
- name: MYSQL_DATABASE
value: "myblog"
yaml
"apiVersion": "v1",
"kind": "Pod",
"metadata":
"name": "myblog",
"namespace": "luffy",
"labels":
"component": "myblog"
,
"spec":
"containers": [
"name": "myblog",
"image": "172.21.51.143:5000/myblog:v1",
"env": [
"name": "MYSQL_HOST",
"value": "127.0.0.1"
]
,
...
]
含义如下:
| apiVersion | 含义 |
|---|---|
| alpha | 进入K8s功能的早期候选版本,可能包含Bug,最终不一定进入K8s |
| beta | 已经过测试的版本,最终会进入K8s,但功能、对象定义可能会发生变更。 |
| stable | 可安全使用的稳定版本 |
| v1 | stable 版本之后的首个版本,包含了更多的核心对象 |
| apps/v1 | 使用最广泛的版本,像Deployment、ReplicaSets都已进入该版本 |
资源类型与 apiVersion 对照表
| Kind | apiVersion |
|---|---|
| ClusterRoleBinding | rbac.authorization.k8s.io/v1 |
| ClusterRole | rbac.authorization.k8s.io/v1 |
| ConfigMap | v1 |
| CronJob | batch/v1beta1 |
| DaemonSet | extensions/v1beta1 |
| Node | v1 |
| Namespace | v1 |
| Secret | v1 |
| PersistentVolume | v1 |
| PersistentVolumeClaim | v1 |
| Pod | v1 |
| Deployment | v1、apps/v1、apps/v1beta1、apps/v1beta2 |
| Service | v1 |
| Ingress | extensions/v1beta1 |
| ReplicaSet | apps/v1、apps/v1beta2 |
| Job | batch/v1 |
| StatefulSet | apps/v1、apps/v1beta1、apps/v1beta2 |
快速获得资源和版本
$ kubectl explain pod
$ kubectl explain Pod.apiVersion
🍑 创建和访问Pod
## 创建namespace, namespace是逻辑上的资源池
$ kubectl create namespace luffy
## 使用指定文件创建Pod
$ kubectl create -f pod.yaml
## 查看pod,可以简写po
## 所有的操作都需要指定namespace,如果是在default命名空间下,则可以省略
$ kubectl -n luffy get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
myblog 2/2 Running 0 3m 10.244.1.146 k8s-slave1
## 回顾流程
## 使用Pod Ip访问服务,3306和8002
$ curl 10.244.1.146:8002/blog/index/
## 进入容器,执行初始化, 不必到对应的主机执行docker exec
$ kubectl -n luffy exec -ti myblog -c myblog bash
/ # env
/ # python3 manage.py migrate
$ kubectl -n luffy exec -ti myblog -c mysql bash
/ # mysql -p123456
## 再次访问服务,3306和8002
$ curl 10.244.1.146:8002/blog/index/
🍑 Infra容器
登录 k8s-slave1 节点
$ docker ps -a |grep myblog ## 发现有三个容器
## 其中包含mysql和myblog程序以及Infra容器
## 为了实现Pod内部的容器可以通过localhost通信,每个Pod都会启动Infra容器,然后Pod内部的其他容器的网络空间会共享该Infra容器的网络空间(Docker网络的container模式),Infra容器只需要hang住网络空间,不需要额外的功能,因此资源消耗极低。
## 登录master节点,查看pod内部的容器ip均相同,为pod ip
$ kubectl -n luffy exec -ti myblog -c myblog bash
/ # ifconfig
$ kubectl -n luffy exec -ti myblog -c mysql bash
/ # ifconfig
pod容器命名:k8s_<container_name>_<pod_name>_<namespace>_<random_string>
🍑 查看pod详细信息
## 查看pod调度节点及pod_ip
$ kubectl -n luffy get pods -o wide
## 查看完整的yaml
$ kubectl -n luffy get po myblog -o yaml
## 查看pod的明细信息及事件
$ kubectl -n luffy describe pod myblog
🍑 Troubleshooting and Debugging
#进入Pod内的容器
$ kubectl -n <namespace> exec <pod_name> -c <container_name> -ti /bin/sh
#查看Pod内容器日志,显示标准或者错误输出日志
$ kubectl -n <namespace> logs -f <pod_name> -c <container_name>
🍑 更新服务版本
$ kubectl apply -f demo-pod.yaml
🍑 删除Pod服务
#根据文件删除
$ kubectl delete -f demo-pod.yaml
#根据pod_name删除
$ kubectl -n <namespace> delete pod <pod_name>
4. Pod常用设置
若删除了 Pod,由于 mysql 的数据都在容器内部,会造成数据丢失,因此需要数据进行持久化。
🍑 Pod数据持久化
定点使用 hostpath 挂载,nodeSelector 定点
myblog/one-pod/pod-with-volume.yaml
apiVersion: v1
kind: Pod
metadata:
name: myblog
namespace: luffy
labels:
component: myblog
spec:
volumes:
- name: mysql-data
hostPath:
path: /opt/mysql/data
nodeSelector: # 使用节点选择器将Pod调度到指定label的节点
component: mysql
containers:
- name: myblog
image: 172.21.51.143:5000/myblog:v1
env:
- name: MYSQL_HOST # 指定root用户的用户名
value: "127.0.0.1"
- name: MYSQL_PASSWD
value: "123456"
ports:
- containerPort: 8002
- name: mysql
image: mysql:5.7
args:
- --character-set-server=utf8mb4
- --collation-server=utf8mb4_unicode_ci
ports:
- containerPort: 3306
env:
- name: MYSQL_ROOT_PASSWORD
value: "123456"
- name: MYSQL_DATABASE
value: "myblog"
volumeMounts:
- name: mysql-data
mountPath: /var/lib/mysql
保存文件为 pod-with-volume.yaml,执行创建
## 若存在旧的同名服务,先删除掉,后创建
$ kubectl -n luffy delete pod myblog
## 创建
$ kubectl create -f pod-with-volume.yaml
## 此时pod状态Pending
$ kubectl -n luffy get po
NAME READY STATUS RESTARTS AGE
myblog 0/2 Pending 0 32s
## 查看原因,提示调度失败,因为节点不满足node selector
$ kubectl -n luffy describe po myblog
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 12s (x2 over 12s) default-scheduler 0/3 nodes are available: 3 node(s) didn't match node selector.
## 为节点打标签
$ kubectl label node k8s-slave1 component=mysql
## 再次查看,已经运行成功
$ kubectl -n luffy get po
NAME READY STATUS RESTARTS AGE IP NODE
myblog 2/2 Running 0 3m54s 10.244.1.150 k8s-slave1
## 到k8s-slave1节点,查看/opt/mysql/data
$ ll /opt/mysql/data/
total 188484
-rw-r----- 1 polkitd input 56 Mar 29 09:20 auto.cnf
-rw------- 1 polkitd input 1676 Mar 29 09:20 ca-key.pem
-rw-r--r-- 1 polkitd input 1112 Mar 29 09:20 ca.pem
drwxr-x--- 2 polkitd input 8192 Mar 29 09:20 sys
...
## 执行migrate,创建数据库表,然后删掉pod,再次创建后验证数据是否存在
$ kubectl -n luffy exec -ti myblog python3 manage.py migrate
## 访问服务,正常
$ curl 10.244.1.150:8002/blog/index/
## 删除pod
$ kubectl delete -f pod-with-volume.yaml
## 再次创建Pod
$ kubectl create -f pod-with-volume.yaml
## 查看pod ip并访问服务
$ kubectl -n luffy get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE
myblog 2/2 Running 0 7s 10.244.1.151 k8s-slave1
## 未重新做migrate,服务正常
$ curl 10.244.1.151:8002/blog/index/
使用 PV+PVC 连接分布式存储解决方案:
- ceph
- glusterfs
- nfs
🍑 服务健康检查
检测容器服务是否健康的手段,若不健康,会根据设置的重启策略(restartPolicy)进行操作,两种检测机制可以分别单独设置,若不设置,默认认为 Pod 是健康的。
两种机制:
- LivenessProbe 探针
存活性探测:用于判断容器是否存活,即 Pod 是否为 running 状态,如果 LivenessProbe 探针探测到容器不健康,则 kubelet 将 kill 掉容器,并根据容器的重启策略是否重启,如果一个容器不包含 LivenessProbe 探针,则 Kubelet 认为容器的 LivenessProbe 探针的返回值永远成功。
...
containers:
- name: myblog
image: 172.21.51.143:5000/myblog:v1
livenessProbe:
httpGet:
path: /blog/index/
port: 8002
scheme: HTTP
initialDelaySeconds: 10 # 容器启动后第一次执行探测是需要等待多少秒
periodSeconds: 10 # 执行探测的频率
timeoutSeconds: 2 # 探测超时时间
...
- ReadinessProbe探针 可用性探测:用于判断容器是否正常提供服务,即容器的 Ready 是否为 True,是否可以接收请求,如果 ReadinessProbe 探测失败,则容器的 Ready 将为 False, Endpoint Controller 控制器将此 Pod 的 Endpoint 从对应的 service 的 Endpoint 列表中移除,不再将任何请求调度此 Pod 上,直到下次探测成功。(剔除此 pod 不参与接收请求不会将流量转发给此 Pod)。
...
containers:
- name: myblog
image: 172.21.51.143:5000/myblog:v1
readinessProbe:
httpGet:
path: /blog/index/
port: 8002
scheme: HTTP
initialDelaySeconds: 10
timeoutSeconds: 2
periodSeconds: 10
...
动图如下:

三种类型:
- exec:通过执行命令来检查服务是否正常,返回值为 0 则表示容器健康
...
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
...
-
httpGet 方式:通过发送 http 请求检查服务是否正常,返回 200-399 状态码则表明容器健康
-
tcpSocket:通过容器的 IP 和 Port 执行 TCP 检查,如果能够建立 TCP 连接,则表明容器健康
示例:完整文件路径 myblog/one-pod/pod-with-healthcheck.yaml
containers:
- name: myblog
image: 172.21.51.143:5000/myblog:v1
env:
- name: MYSQL_HOST # 指定root用户的用户名
value: "127.0.0.1"
- name: MYSQL_PASSWD
value: "123456"
ports:
- containerPort: 8002
livenessProbe:
httpGet:
path: /blog/index/
port: 8002
scheme: HTTP
initialDelaySeconds: 10 # 容器启动后第一次执行探测是需要等待多少秒
periodSeconds: 10 # 执行探测的频率
timeoutSeconds: 2 # 探测超时时间
readinessProbe:
httpGet:
path: /blog/index/
port: 8002
scheme: HTTP
initialDelaySeconds: 10
timeoutSeconds: 2
periodSeconds: 10
- initialDelaySeconds:容器启动后第一次执行探测是需要等待多少秒。
- periodSeconds:执行探测的频率。默认是 10 秒,最小 1 秒。
- timeoutSeconds:探测超时时间。默认 1 秒,最小 1 秒。
- successThreshold:探测失败后,最少连续探测成功多少次才被认定为成功。默认是 1。
- failureThreshold:探测成功后,最少连续探测失败多少次 才被认定为失败。默认是 3,最小值是 1。
K8S 将在 Pod 开始启动10s(initialDelaySeconds)后利用 HTTP 访问 8002 端口的 /blog/index/,如果超过 2s 或者返回码不在 200~399 内,则健康检查失败。
🍑 重启策略
Pod 的重启策略(RestartPolicy)应用于 Pod 内的所有容器,并且仅在 Pod 所处的 Node 上由 kubelet 进行判断和重启操作。当某个容器异常退出或者健康检查失败时,kubelet 将根据 RestartPolicy 的设置来进行相应的操作。
Pod 的重启策略包括 Always、OnFailure 和 Never,默认值为 Always。
- Always:当容器进程退出后,由 kubelet 自动重启该容器;
- OnFailure:当容器终止运行且退出码不为 0 时,由 kubelet 自动重启该容器;
- Never:不论容器运行状态如何,kubelet 都不会重启该容器。
演示重启策略:
apiVersion: v1
kind: Pod
metadata:
name: test-restart-policy
spec:
restartPolicy: Always
containers:
- name: busybox
image: busybox
args:
- /bin/sh
- -c
- sleep 10
- 使用默认的重启策略,即
restartPolicy:Always,无论容器是否是正常退出,都会自动重启容器 - 使用 OnFailure 的策略时
- 如果把 exit 1,去掉,即让容器的进程正常退出的话,则不会重启
- 只有非正常退出状态才会重启
- 使用 Never 时,退出了就不再重启
可以看出,若容器正常退出,Pod 的状态会是 Completed,非正常退出,状态为 CrashLoopBackOff
🍑 镜像拉取策略
spec:
containers:
- name: myblog
image: 172.21.51.143:5000/myblog:v1
imagePullPolicy: IfNotPresent
设置镜像的拉取策略,默认为 IfNotPresent
- Always,总是拉取镜像,即使本地有镜像也从仓库拉取
- IfNotPresent ,本地有则使用本地镜像,本地没有则去仓库拉取
- Never,只使用本地镜像,本地没有则报错
🍑 Pod资源限制
为了保证充分利用集群资源,且确保重要容器在运行周期内能够分配到足够的资源稳定运行,因此平台需要具备
Pod 的资源限制的能力。 对于一个 pod 来说,资源最基础的 2 个的指标就是:CPU和内存。
Kubernetes 提供了个采用 requests 和 limits 两种类型参数对资源进行预分配和使用限制。
完整文件路径:myblog/one-pod/pod-with-resourcelimits.yaml
...
containers:
- name: myblog
image: 172.21.51.143:5000/myblog:v1
env:
- name: MYSQL_HOST # 指定root用户的用户名
value: "127.0.0.1"
- name: MYSQL_PASSWD
value: "123456"
ports:
- containerPort: 8002
resources:
requests:
memory: 100Mi
cpu: 50m
limits:
memory: 500Mi
cpu: 100m
...
requests:
- 容器使用的最小资源需求,作用于 schedule 阶段,作为容器调度时资源分配的判断依赖
- 只有当前节点上可分配的资源量 >= request 时才允许将容器调度到该节点
- request 参数不限制容器的最大可使用资源
- requests.cpu 被转成 docke r的
--cpu-shares参数,与 cgroup cpu.shares 功能相同 (无论宿主机有多少个 cpu 或者内核,--cpu-shares选项都会按照比例分配 cpu 资源) - requests.memory 没有对应的 docker 参数,仅作为 k8s 调度依据
limits:
- 容器能使用资源的最大值
- 设置为 0 表示对使用的资源不做限制, 可无限的使用
- 当 pod 内存超过 limit 时,会被 oom
- 当 cpu 超过 limit 时,不会被 kill,但是会限制不超过 limit 值
- limits.cpu 会被转换成 docker 的
–cpu-quota参数。与 cgroup cpu.cfs_quota_us 功能相同 - limits.memory 会被转换成 docker 的
–memory参数。用来限制容器使用的最大内存
对于 CPU,我们知道计算机里 CPU 的资源是按 “时间片” 的方式来进行分配的,系统里的每一个操作都需要 CPU 的处理,所以,哪个任务要是申请的 CPU 时间片越多,那么它得到的 CPU 资源就越多。
然后还需要了解下 CGroup 里面对于 CPU 资源的单位换算:
1 CPU = 1000 millicpu(1 Core = 1000m)
这里的 m 就是毫、毫核的意思,Kubernetes 集群中的每一个节点可以通过操作系统的命令来确认本节点的 CPU 内核数量,然后将这个数量乘以 1000,得到的就是节点总 CPU 总毫数。比如一个节点有四核,那么该节点的 CPU 总毫量为 4000m。
docker run 命令和 CPU 限制相关的所有选项如下:
| 选项 | 描述 |
|---|---|
--cpuset-cpus="" | 允许使用的 CPU 集,值可以为 0-3,0,1 |
-c,--cpu-shares=0 | CPU 共享权值(相对权重) |
cpu-period=0 | 限制 CPU CFS 的周期,范围从 100ms~1s,即[1000, 1000000] |
--cpu-quota=0 | 限制 CPU CFS 配额,必须不小于1ms,即 >= 1000,绝对限制 |
docker run -it --cpu-period=50000 --cpu-quota=25000 ubuntu:16.04 /bin/bash
将 CFS 调度的周期设为 50000,将容器在每个周期内的 CPU 配额设置为 25000,表示该容器每 50ms 可以得到 50% 的 CPU 运行时间。
注意:若内存使用超出限制,会引发系统的 OOM 机制,因 CPU 是可压缩资源,不会引发 Pod 退出或重建
以上是关于K8s落地实践之旅 —— Pod(豌豆荚)的主要内容,如果未能解决你的问题,请参考以下文章