Make R-CNN论文学习
Posted wanghui-garcia
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Make R-CNN论文学习相关的知识,希望对你有一定的参考价值。
在论文是在Faster R-CNN的基础上的改进 ,实现的效果有:
- 目标检测:能够在输入图像中绘制出目标的边界框,预测目标位置
- 目标分类:判别出该划定边界的目标的类别是什么,如人、车、猫和狗等类别
- 像素级目标分割:(这就是其比Faster R-CNN多出的一个功能)能够在像素层面上对目标进行区分,将目标和背景区分开来,并使用不同的颜色进行标记
如Faster R-CNN的检测结果为:
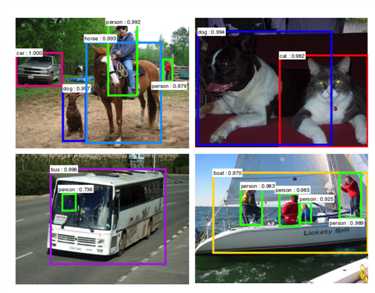
而mask R-CNN的检测结果为:

可见mask R-CNN还能够将框中具体的目标部分使用同种颜色标记出来
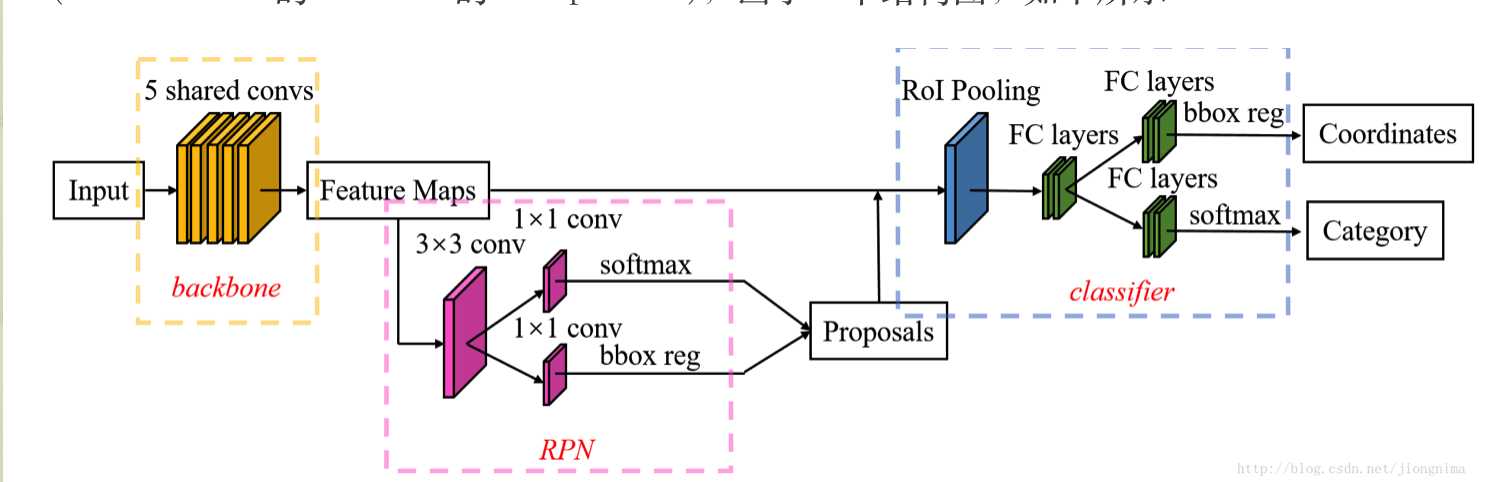
mask R-CNN在Faster R-CNN上面的更改可从下面的两幅网络结构图中看出来:
Faster R-CNN的结构图为:
mask R-CNN的结构图为:
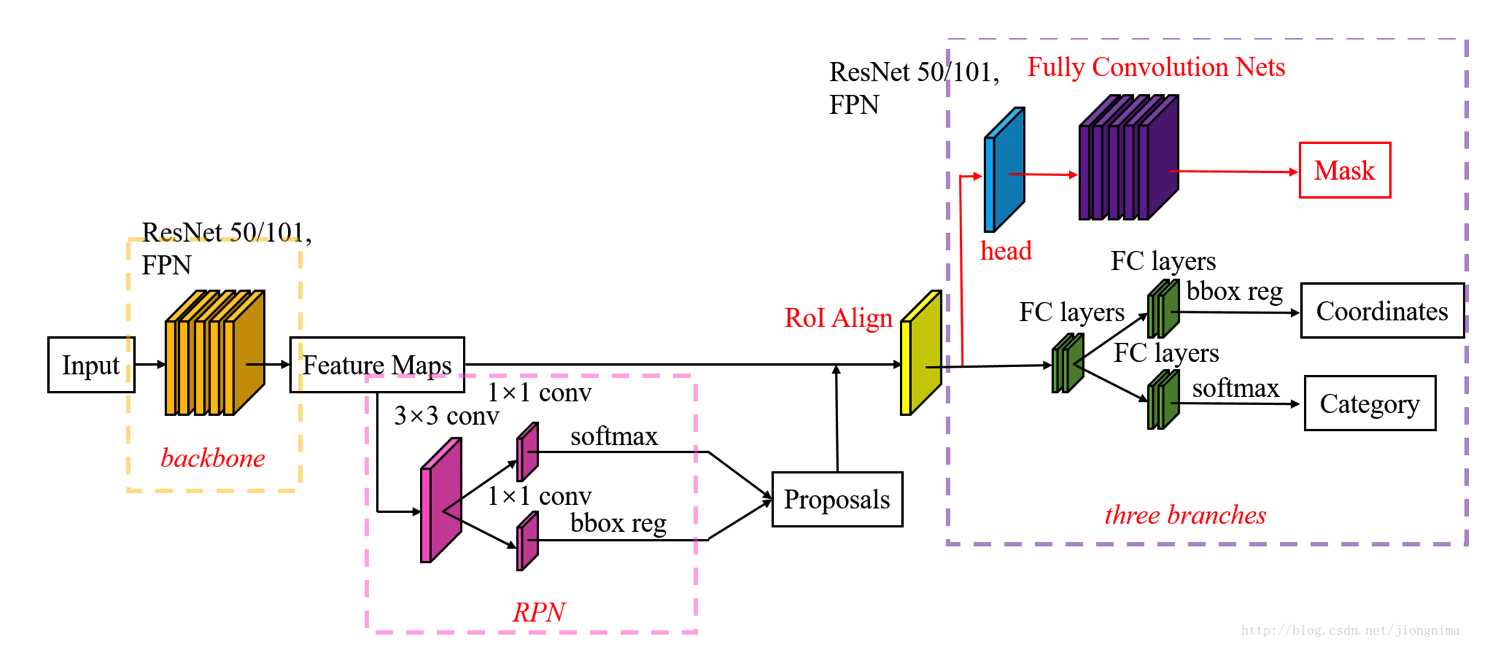
可见差别主要有两部分:
- 首先是RoI池化层改进成了RoI Align层
- 其次是在第二阶段中添加了一个掩模mask检测分支
Mask R-CNN能够很容易地用于其他任务中,比如能够在相同的框架下很容易地判断人类姿势。其在COCO系列挑战赛中的三种项目中都得到了最好的结果,如实例分割、边界框目标检测和人体关键点检测。
什么是实例分割?
实例分割就是不仅要正确检测出一张图片中所有的目标(即画出边界框),并且要精确地分割出每个实例(即上面图像中将边界框中准确的目标用同颜色标注,即对每个像素进行分类)
Mask R-CNN的目的就是为实例分割开发一个相对可用的框架。
首先mask分支是一个用在每个RoI上的小型FCN(全卷积网络),以像素到像素的方式预测分割掩模。掩模分支只增加了一个小的计算开销,使快速系统和快速实验成为可能
其次因为Faster R-CNN没有设计用于网络输入输出之间的像素对齐。这一点在RoIPool[13, 9]中最为明显,它实际上是用于处理实例的核心操作,对特征提取执行粗糙的空间量化。为了修正错位,我们提出了一个简单的,量化无关的层叫做RoIAlign,可以保留精确的空间位置。尽管看似一个很小的变化,RoIAlign起了很大的作用:它能将掩模准确率提高到10%至50%。而且我们发现它对于解耦掩模和类预测是至关重要的:在没有类间竞争的情况下,我们为每个类独立的预测二进制掩模。并且依赖于网络的RoI分类分支来预测类别。相比之下,FCNs通常实现每像素多类分类,分割和分类同时进行,基于我们的实验,发现它对实例分割效果不佳。
我们的模型在GPU上以200ms每帧的速度运行,使用一台有8个GPU的机器,在COCO上训练需要一到两天的时间
Mask R-CNN
Mask R-CNN采用了与Fast R-CNN相同的二阶段过程,第一阶段都使用相同的RPN网络。在第二个阶段中,在并行预测类和框偏置的同时还为每个RoI输出一个二进制掩模。这与最近大多数的系统(如[33,10,26])是相反的,最近的系统都依靠于掩模预测进行分类(而这里是将分类和掩模预测分开进行)。我们的方法遵循了Fast R-CNN并行应用边界框分类和回归的思想(大大简化了原始R-CNN的对阶段管道)。
通常,我们都会在每个采样RoI上定义一个多任务损失函数L=Lcls+Lbox+Lmask,分类损失函数Lcls和回归损失函数Lbox与Fast R-CNN中是相同的。掩模分支对每个RoI都有Km2维的输出,表示K个分辨率为m*m的二进制掩模,K表示类别数量(即对该RoI是否为K个类别中一个进行判定,且每个类别都会返回一个分辨率为m*m的二进制掩模)。为了实现它,我们对每个像素采用了sigmoid,并将Lmask定义为平均二进制交叉熵损失函数。对于某个与某真实类k相关联的RoI,Lmask仅被定义在第k个掩模上(这是因为其他的掩模输出对损失函数没有贡献)。??掩模损失函数Lmask仅在RoI的正样本上定义
我们对Lmask的定义允许网络对每个类在没有类间竞争的情况下生成掩模。我们依赖与专用的分类分支去预测用于收集输出掩模的类别标签。该操作解耦了掩模和类别预测。这与通常将FCNs[23]应用于像素级的softmax和多项式交叉熵损失的语义分割做法不同。在传统做法中,掩模将会跨类别竞争。而在我们的方法中,使用了像素级的sigmoid和二进制损失函数,掩模将不会跨类别竞争(即无类别竞争)。我们通过实验发现,这种方法是改善实例分割结果的关键。
Mask Representation掩模表示
掩模编码了输入目标的空间布局。因此与在全连接层中类别标签和框偏置不可避免地缩成短的输出向量不同,这里能够通过卷积所提供的像素到像素的对应关系,很自然地抽取掩模的空间结构。
具体来说,我们使用一个FCN全卷积网络预测来自每个RoI的一个m*m的掩模。这允许在掩模分支中的每一层保持具体的m*m目标空间布局,不需要将其收缩成一个缺乏空间维度的向量表示。不像之前为了掩模预测扭曲到fc层的方法[33,34,10],我们的全卷积表示需要更少的参数,并且如实验中说明有着更高的准确度。
该像素到像素的行为需要RoI特征,其本身就是小特征图,为了更好的对齐,以准确的保留显式的像素空间对应关系,我们开发出在掩模预测中发挥关键作用的RoIAlign层,将在接下来讲到
RoIAlign
RoIAlign是从每个RoI中抽取一个小的特征映射(如7*7)的一个标准的操作。RoIPool首先将一个浮点数RoI量化为特征图的离散粒度,然后将这个量化的RoI细分为各自量化的空间bin,最后将每个bin覆盖的特征值聚合(通常通过max pooling)。量化是可执行的。例如,对在连续坐标系上的x计算[x/16],其中16是特征图步幅(缩放的比例),[.]表示四舍五入。同样的,当将RoI分成bins时(例如7×7)也执行同样的量化计算。这些量化操作使RoI与提取的特征错位。虽然这可能不会影响分类,因为分类对小幅度的变换有一定的鲁棒性,但它对预测像素级精确度的掩模有很大的负面影响。
为了解决这个问题,我们提出了一个RoIAlign层,消除了对RoIPool的粗糙量化,并将提取的特征与输入精准的对齐。我们提出的改变很简单,我们避免对RoI边界或bins进行量化(例如,我们使用x/16代替[x/16],即不进行四舍五入)。我们使用双线性插值[22](详情可见最邻近插值算法和双线性插值算法——图像缩放)在每个RoI bins中的四个常规采样位置计算输入特征的的精确值,并将结果汇总(使用最大或平均池化),即从原图根据缩放比例对应得到相应的像素值后才进行池化。我们注意到结果对抽取的4个样本位置甚至是采样多少个点并不敏感,只要不进行量化即可
正如我们在4.2节(对照实验)中所示,RoIAlign的改进效果明显。我们还比较了[10]中提出的RoIWarp操作。与RoIAlign不同,RoIWarp忽略了对齐问题,并在[10]的实现中有像RoIPool那样量化RoI。即使RoIWarp也采用了[22]中的双线性重采样,如实验所展示的那样(更多细节见表2c),它与RoIPool的效果差不多。这表明对齐起到了关键的作用。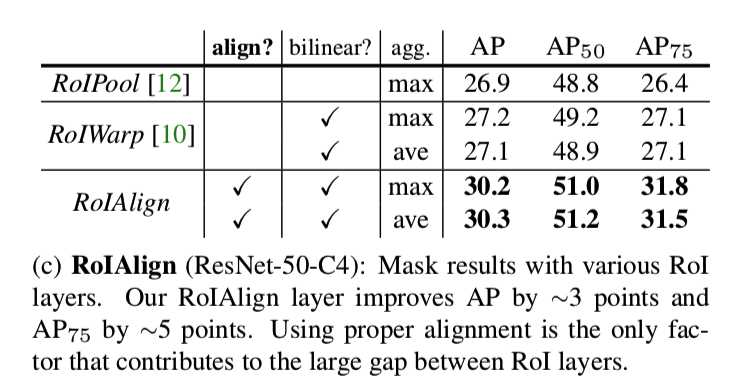
新的网络结构为:
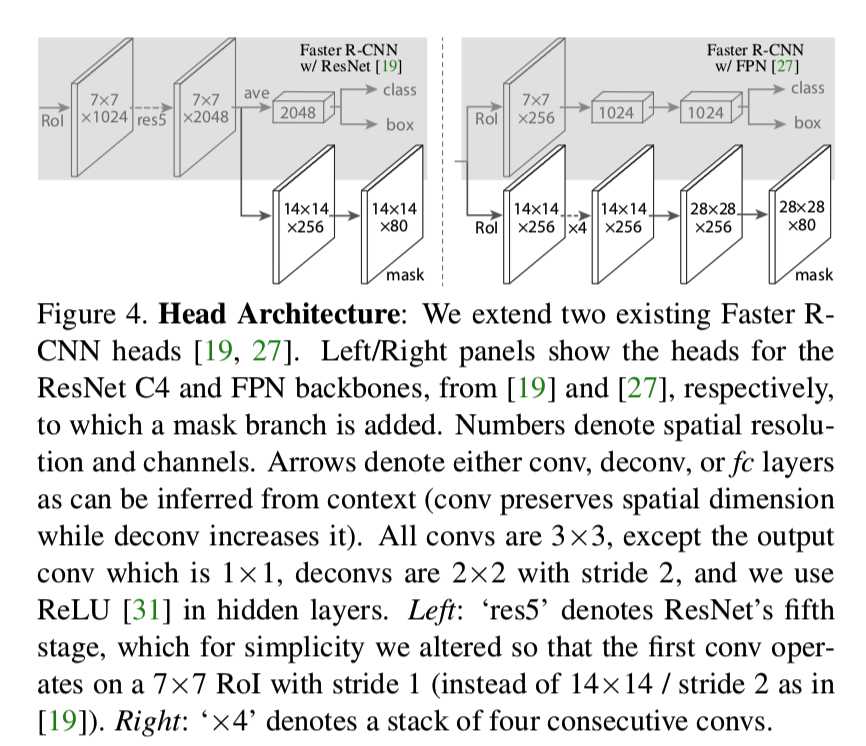
以上是关于Make R-CNN论文学习的主要内容,如果未能解决你的问题,请参考以下文章
深度学习论文翻译解析:Faster R-CNN: Down the rabbit hole of modern object detection