Libra R-CNN论文阅读
Posted 仙女修炼史
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Libra R-CNN论文阅读相关的知识,希望对你有一定的参考价值。
一、论文提出的问题
- Sample level imbalance(采样不均衡):训练过程中,难例对于检测性能的提高至关重要,但是训练中的随机采样,使得难例淹没在简单的、已学习过的样本中。OHEM(难例挖掘)用来从所有的样本中,将难例挖掘出来,但是这种对噪声比较敏感,另外费时。Focal loss是用来缓解一阶检测器中的样本不平衡,但是这种方法对于R-CNN这类的二阶检测器,效果不佳,因为大量的容易的样本都是在第二阶段过滤的。
- Feature level imbalance(特征层的不平衡):高层特征包含更多的语义信息,低层特征更具有内容描述性。特征融合(例如FPN)取得了极大的效果,说明高层特征和低层特征对于目标检测是信息是互补的。实验表明,融合后的特征应该具有每个分辨率的平衡信息。之前提到的融合方式(FPN)使得融合后的特征更加关注相邻两个分辨率的特征,而忽视其他层的特征,非相邻层包含的语义信息,每次融合都会被稀释一次。
- Objective level imbalance(目标函数的不平衡):训练过程需要解决的是分类和定位两个任务,如果这两个任务没有适当的平衡,一个任务会被损害,导致整个任务不能达到最优性能。
二、针对问题提出的方案
论文设计了Libra R-CNN网络框架来解决提出的问题,该网络框架具有一下特点:
- IOU-balanced sampling
OHEM和Focal loss 是现有的解决样本不平衡的主要解决方案。常用的OHEM根据confidences来挖掘难例,OHEM的缺点是需要额外的计算,另外容易受到噪声标签的影响,所以并不适用于所有的情况。Focaloss主要是前景和背景之间的不平衡,主要在one-stage工作,two-stage不work。
该论文提出的IOU-balanced sampling可以增加难例的采样概率。假设,需要从M个候选样本中选择N个负样本,该论文根据IOU的值将M个候选样本划分为K个bin,在每个bin中均匀的选择样本。 - balanced feature pyramid
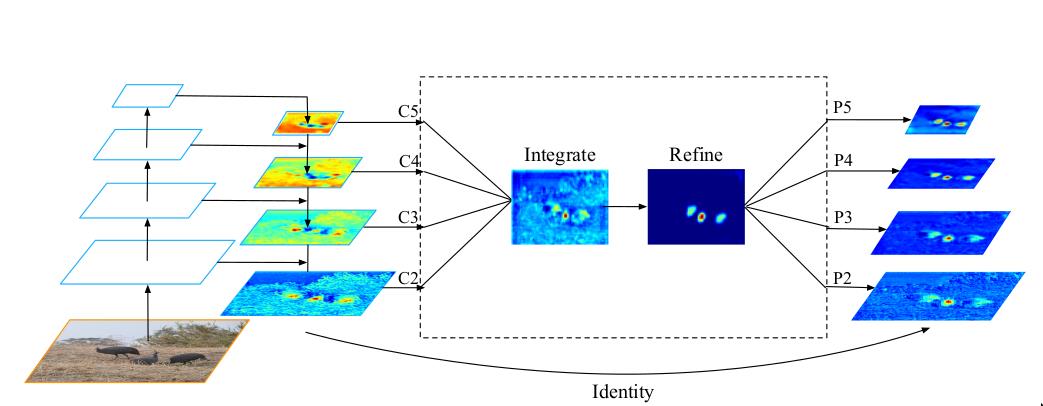
这个部分主要分为三个步骤:
1、obtaining balanced semantic features
图中的 C 1 C_1 C1、 C 2 C_2 C2、 C 3 C_3 C3、 C 4 C_4 C4、 C 5 C_5 C5是FPN的输出结果,显而易见,这一部分是附加在FPN的后面,会增加额外的计算。首先,选中中间一个层的尺寸,例如 C 4 C_4 C4,将剩下的 C 1 C_1 C1、 C 2 C_2 C2、 C 3 C_3 C3、和 C 5 C_5 C5都rescale到 C 4 C_4 C4的尺寸,大于 C 4 C_4 C4尺寸的使用插值操作,小于 C 4 C_4 C4尺寸的使用最大池化操作,然后将所有rescale过之后的,尺寸相同的特征层,加起来求平均值,这个就是得到的平衡的语义特征。
2、refining balanced semantic features
平衡的语义特征可以进一步细化以更具辨别力。直接使用卷积操作,或者非局部模块,都可以得到很好的细化结果。这里使用Non-local。
3、 scatter refined features to multi-levels
将细化之后的特征,原路返回到每个level尺寸,然后和该尺寸的特征层相加,得到强化后的特征,做后续的分类和回归。
以上是关于Libra R-CNN论文阅读的主要内容,如果未能解决你的问题,请参考以下文章
论文阅读(Chenyi Chen——ACCV2016R-CNN for Small Object Detection)