Mask R-CNN
Posted edbean
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mask R-CNN相关的知识,希望对你有一定的参考价值。
论文信息
Kaiming He, Georgia Gkioxari, Piotr Dollár, Ross Girshick. Mask R-CNN. open source.
https://arxiv.org/abs/1703.06870
前言
本文有很多奇思妙想, 创意十足. 网上的普遍评价也都是"惊为天人", "百看不厌", 我在阅读时也确有此感!
Introduction
本文使用Faster R-CNN作为backbone, 熟悉Faster R-CNN的朋友肯定知道该模型的一大特点是classification与bbox regression并行, 本文也继承了其特点: classification, bbox regression, mask并行. 也正是其并行化的特点决定了其速度较快(与Faster R-CNN相近).
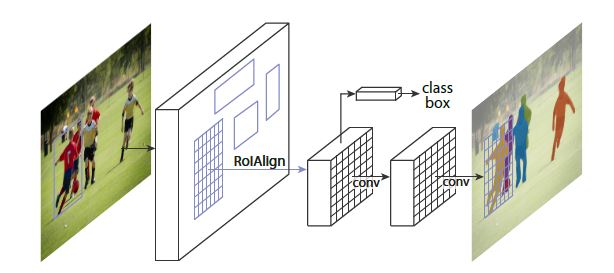
由于backbone是一个object detection模型而本文又是以semantic segmentation为出发点, 因此作者介绍了自己对二者的理解, 这个理解决定后来解决问题的方法:
object detection: The goal is to classify individual objects and localize each using a bounding box.
semantic segmentation: The goal is to classify each pixel into a fixed set of categories without differentiating object instances.
同时, 本文还提出了一种优化RoI空间特征失调问题的优化模型 - RoIAlign. 由于提升了空间特征的表现力, 其mask accuracy也得到了一定的提升, 特别的, 这种新模型也同样能够提升classification的mAP.
特别的, 作者还尝试将本文中的模型泛化到其他领域, 如, 人体姿态检测.
Related Work
Instance Segmentation
基于segment proposal, 通常是先识别目标后分割, 毫无疑问的会是低速的, 作者还认为其准确率低.
而在当时比较流行一种叫fully convolutional instance segmentation(FCIS for short)的方法, 这种方法主要是: 通过卷积的方法输出一系列预测的channel. 这些channel包含class, box and mask并行信息. 但这种方法存在的问题是对于交叠物体预测质量差, 我认为可能是因为卷积会模糊位置信息.
还有一种方法是segmentation-first的方法: 利用单个像素分类, 尝试将相同类别的像素拆成不同instance.
本文中的方法与第二种方法相反, 本文是一种instance-first的方法.
Mask R-CNN
segmentation和classification相比, 更加依赖于物体的空间结构.
Main Framework
本文主要利用每个RoI的输出, 产生binary mask, 这binary mask是本文的一个重要特色, 它与其他流行的依靠分类不同, 它只要求分出哪个是物体而不管是什么物体.
loss函数自然就是Faster R-CNN的class和box加上本文新提出的mask损失构成:
\[
L = L_cls + L_box + L_mask
\]
这里需要说明, 如果RoI输出的矩阵是\(m \times m\), 那么mask的输出是一个\(Km^2\)-d的矩阵, 其中\(K\)是指物体的class数量. 可能这里引起疑惑:
? 上文明明说了本文的mask方法在明明不需要知道是什么物体, 但是为什么还要在维度有\(K\)?
? 这里又引入了本文的另一个特色: 如果分类结果是\(k\)th物体, 那么只取该物体的mask而不管其他物体的mask, 在计算loss时也同样不用管其他物体.
这样又可能引起疑惑:
? 这样是不是就要先进行分类了?
? 这里我们要说明, 由于本文是并行产生class和mask的, 因此我们模型只需要正常并行产生二者, 之后根据class信息取出我们需要的mask即可.
关于mask的loss, 本文采用per-pixel softmax和multinomial cross-entropy loss.
Mask Representation
因为此前的诸多方法使用fc会导致空间信息损失(这里我想解释一下fc实际就相当于向量与矩阵相乘), 本文的优越性就在于使用\(m \times m\)矩阵保持了空间信息.
RoIAlign
这是本文的另一个重要特色, 请提前上厕以免影响思路连续性.
对于传统的RoI方法, 我们知道传统RoI是将物体分成若干区域(如\(k \times k\)个)后pooling, 而如果长或宽的像素点数量不是\(k\)的整数倍的话, 那么分出来的结果将会导致每个区域像素点含量不同, 下面有一个可视化动图.
而这种不相等的像素点最终却被视作相同尺寸的输出, 那自然会导致位置信息模糊.
本文就提出了一种解决方案.
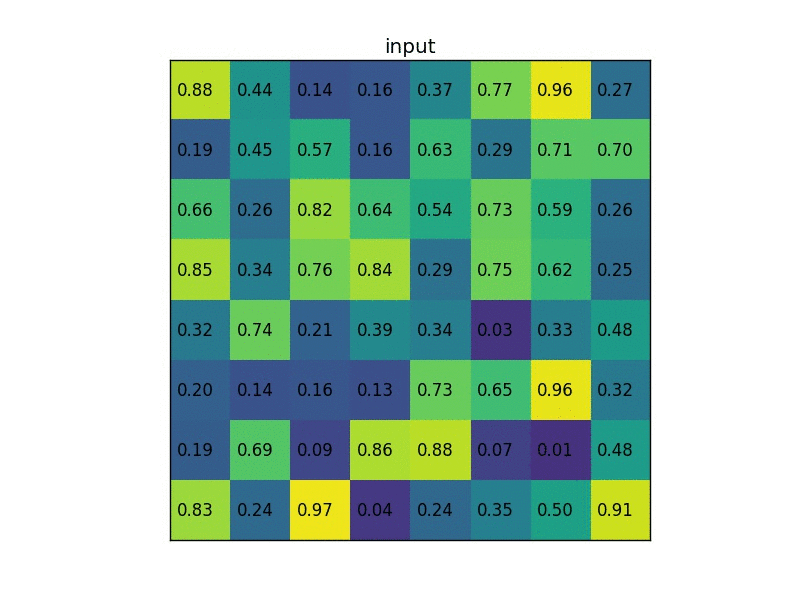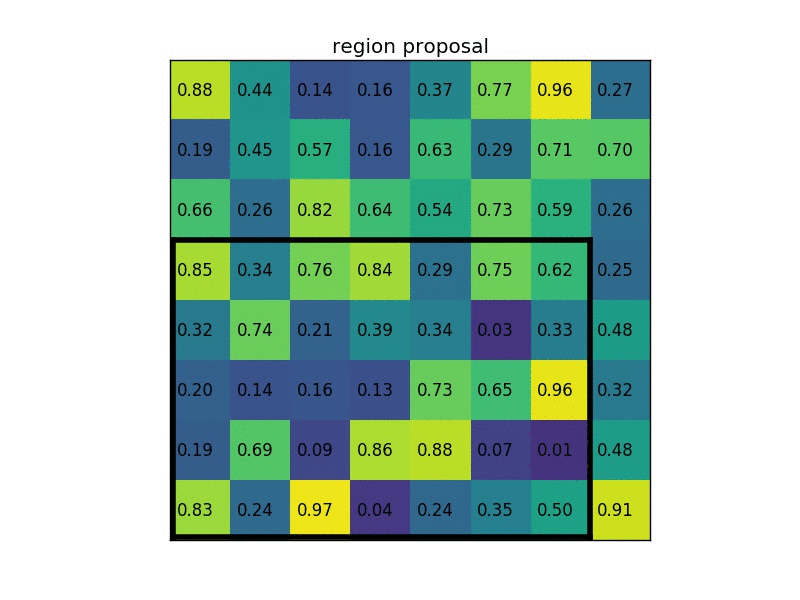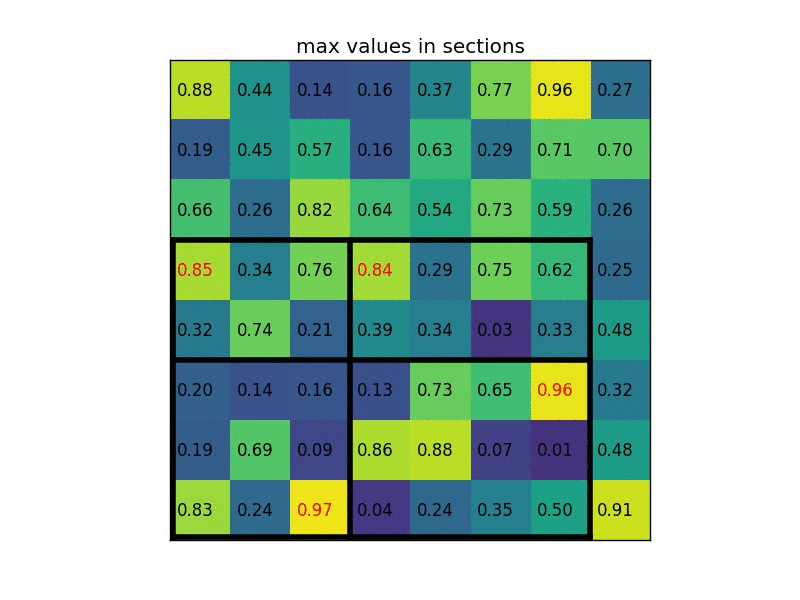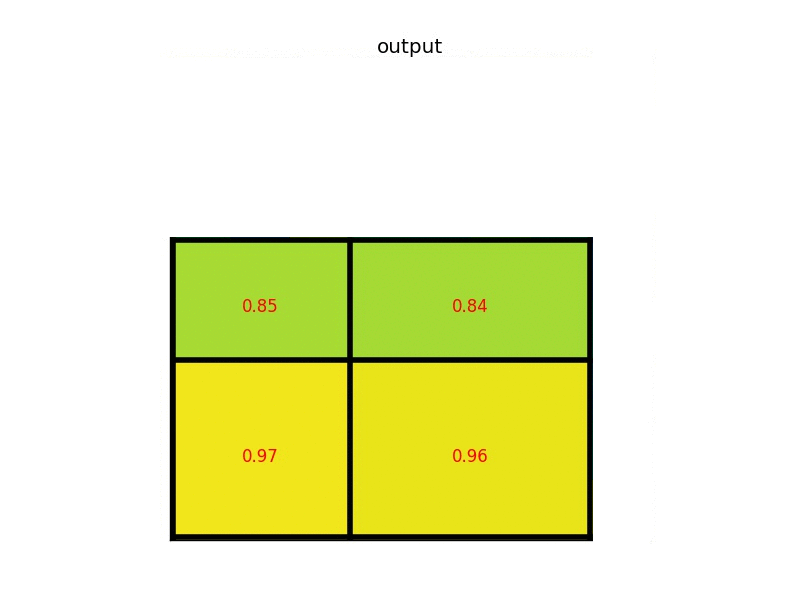
首先因为假设RoI的尺寸是\(m \times m\), RoI输出\(k \times k\), 那么传统方法是取像素\(\lfloor m/k \rfloor\)作为整数输出, 而本文直接取\(m/k\), 这样可能有的人会认为此方法很反人类: 像素点是离散int的, 直接相除会得到float结果, 从哪里去找这个float位置的值?
作者脑洞大开: 用插值啊!!! 更确切是双线性插值.
插值之后便有了float位置的数值:

这张图的意思是, 每个蓝色方块代表一个整数位置如(2, 2), 当我们取得RoI参数不合适时, 作者直接划分, 元素位置也变成float的(图中黑点), 再利用双线性插值法计算各float位置的值. 计算出该值之后进行pooling, 此时的输出结果就和传统RoIPooling相同了.
额外的, 作者还尝试过其他backbone, 如FPN, 取得了更好的指标结果.
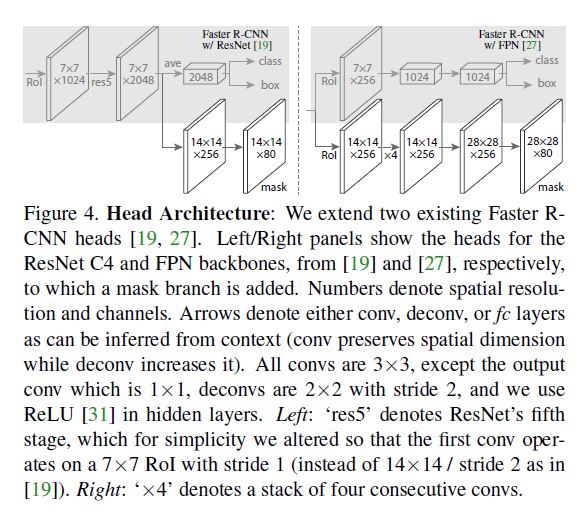
Network Head
作者提出了两种方法, 也非常直观, 便不再赘述. 值得一提的是这两种mask都是基于Conv而非fc.
Implementation Details
- 前文提过mask的loss只计算对应class的预测.
- positive与negative比例为1:3.
- mask是从最高score的100个box预测, 这种只使用部分box的方法同时提升了accuracy和speed.
Experiments
Ablation Experiments
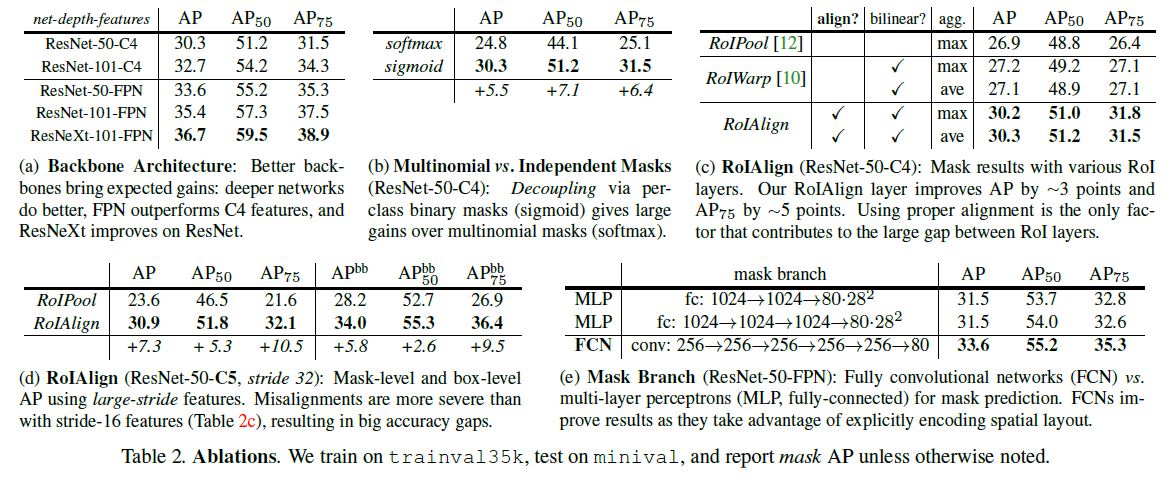
- 不是越深的backbone对accuracy提升越大.
- 比先预测class后mask的方法能取得更好的结果, 说明本文直接看成一个整体的方法更好.
- 使用FCN比使用MLP做head能取得更好的结果.
Bounding Box Detection Results
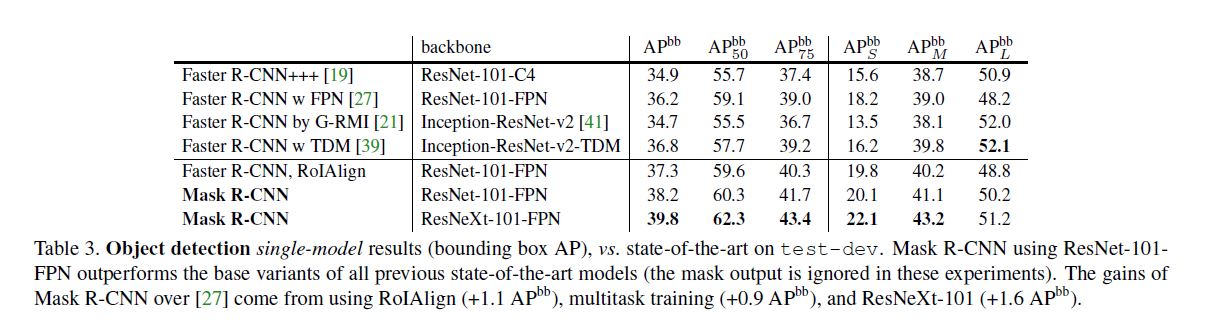
这里主要讨论了RoIAlign对于classification的帮助, 因为更完善的体现了空间信息, 那么在bbox取得更好结果进而在mAP取得更好结果也不足为奇.
Mask R-CNN for Human Pose Estimation
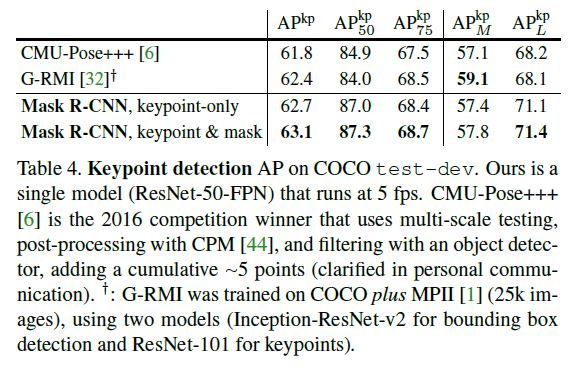
作者将人体各个keypoint(e.g. 左肩, 左手)作为mask的类别, 其余思想基本不变来进行预测.
由于本文的并行性, 且空间信息更好地表示, 因此取得了比当时的模型无论从速度还是准确度还是信息丰富度都更加优越的碾压性优势.
Conclusion
本文的贡献:
- mask采用整体思想, 看成一个整体, 利用分类信息选择而不是利用分类信息预测.
- 并行化提升速度.
- 提出一种新的RoI方法从而更好地表示空间信息.
以上是关于Mask R-CNN的主要内容,如果未能解决你的问题,请参考以下文章