一致性hash算法
Posted sten
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一致性hash算法相关的知识,希望对你有一定的参考价值。
在分布式场景中,后台提供的支撑服务是n个具体的主机,我们怎么能做到每台主机的负载均衡,伸缩性灵活呢?在分布式服务上,我们用一些hash策略就能实现均衡。添加一台服务器或者下线一台服务器,更新路由配置就ok了。但是在分布式缓存上,如果添加一台主机或者下线一台主机,也采用相同的策略,这意味着之前的全部缓存将失效,这种后果是大部分系统无法承受的。那怎么办呢?
这种情况,我们的一致性hash算法就能很好的用上了。我们取0到M值组成一个环,n个主机hash计算落在0到M之间。
如下图:
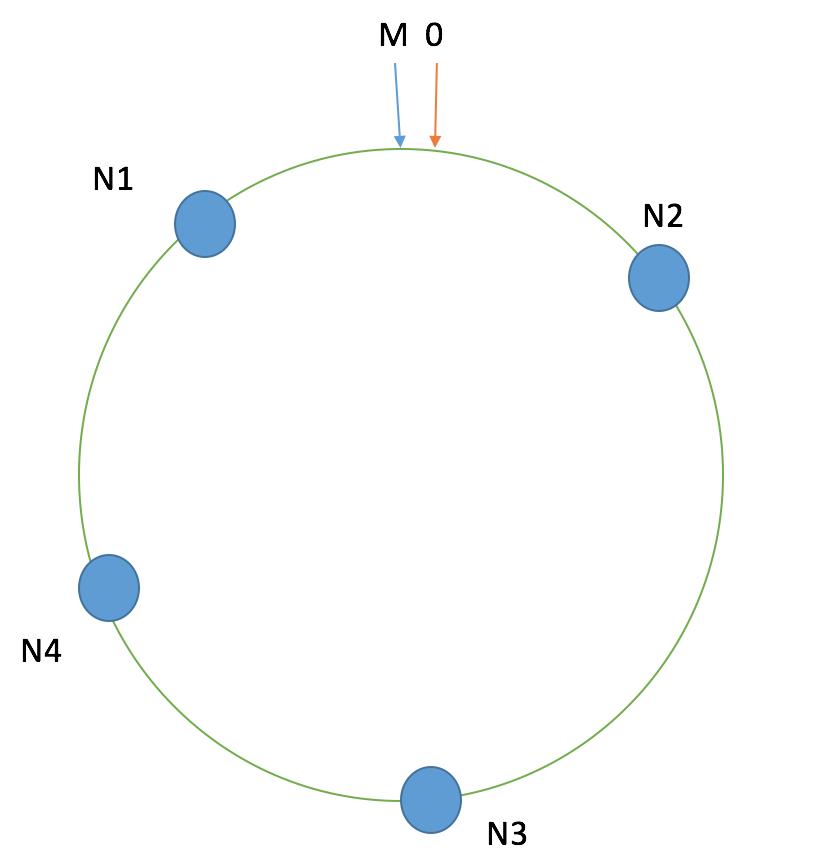
请求值hash计算后落在N2和N3之间的,路由到N3主机;落在N3和N4之间的,路由到N4主机;落在N4和N1之间的,路由到N1主机;落在N1和N2之间的,路由到N2主机。
如果N1主机下线,N4和N1之间的数据将路由到N2上,只有这一部分的数据有影响,其他的数据仍然有效。
如果添加一个数据N5,如下图:

则N2和N5之间的数据有改动,路由到N5主机上,其他的数据不受影响。
上面就把之前的那个问题给解决了,只有少部分数据受到影响。但是,不够完善,还有问题。N1下线之后,N4和N1之间的数据,全部落到N2上了,N2的压力增大很大,有风险,很容易产生雪崩效应;N5添加之后,只是缓解了N3一台主机的压力,没有资源最大化。这种问题我们怎么解决呢?
可以引人虚拟节点方案,一个节点虚拟成100个或者更多,N1到N4主机虚拟成很多虚拟节点落在0到M的环上。虚拟节点越多,他们交替分布的越均匀。
当其中的某台主机下线,这上面的数据将*乎*均的分摊到其他主机上;当添加某台新主机,它将*乎均等的分摊其他主机的压力。
以上是关于一致性hash算法的主要内容,如果未能解决你的问题,请参考以下文章