图解一致性hash算法和实现
Posted 全菜工程师小辉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图解一致性hash算法和实现相关的知识,希望对你有一定的参考价值。
一致性hash算法是什么?
一致性hash算法,是麻省理工学院1997年提出的一种算法,目前主要应用于分布式缓存当中。
一致性hash算法可以有效地解决分布式存储结构下动态增加和删除节点所带来的问题。
在Memcached、Key-Value Store、Bittorrent DHT、LVS中都采用了一致性hash算法,可以说一致性hash算法是分布式系统负载均衡的首选算法。
传统hash算法的弊端
常用的算法是对hash结果取余数 (hash() mod N):对机器编号从0到N-1,按照自定义的hash算法,对每个请求的hash值按N取模,得到余数i,然后将请求分发到编号为i的机器。但这样的算法方法存在致命问题,如果某一台机器宕机,那么应该落在该机器的请求就无法得到正确的处理,这时需要将宕掉的服务器使用算法去除,此时候会有(N-1)/N的服务器的缓存数据需要重新进行计算;如果新增一台机器,会有N /(N+1)的服务器的缓存数据需要进行重新计算。对于系统而言,这通常是不可接受的颠簸(因为这意味着大量缓存的失效或者数据需要转移)。
传统求余做负载均衡算法,缓存节点数由3个变成4个,缓存不命中率为75%。计算方法:穷举hash值为1-12的12个数字分别对3和4取模,然后比较发现只有前3个缓存节点对应结果和之前相同,所以有75%的节点缓存会失效,可能会引起缓存雪崩。
一致性hash算法
首先,我们将hash算法的值域映射成一个具有232 次方个桶的空间中,即0~(232)-1的数字空间。现在我们可以将这些数字头尾相连,组合成一个闭合的环形。
每一个缓存key都可以通过Hash算法转化为一个32位的二进制数,也就对应着环形空间的某一个缓存区。我们把所有的缓存key映射到环形空间的不同位置。
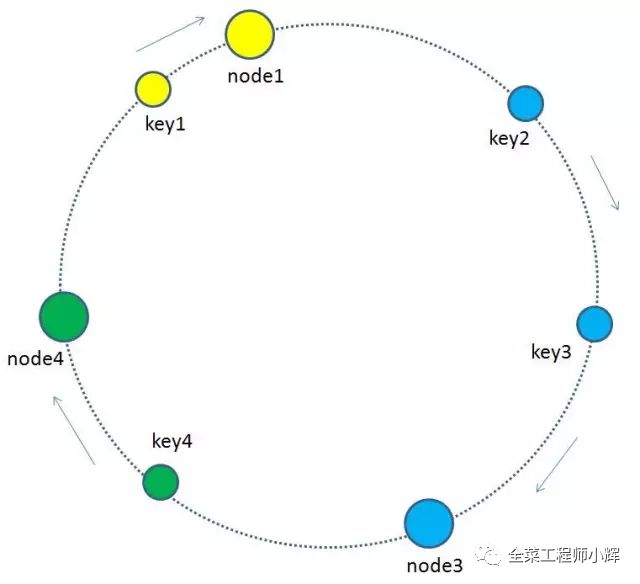
我们的每一个缓存节点也遵循同样的Hash算法,比如利用IP或者主机名做Hash,映射到环形空间当中,如下图
如何让key和缓存节点对应起来呢?很简单,每一个key的顺时针方向最近节点,就是key所归属的缓存节点。所以图中key1存储于node1,key2,key3存储于node2,key4存储于node3。
当缓存的节点有增加或删除的时候,一致性哈希的优势就显现出来了。让我们来看看实现的细节:
增加节点
当缓存集群的节点有所增加的时候,整个环形空间的映射仍然会保持一致性哈希的顺时针规则,所以有一小部分key的归属会受到影响。
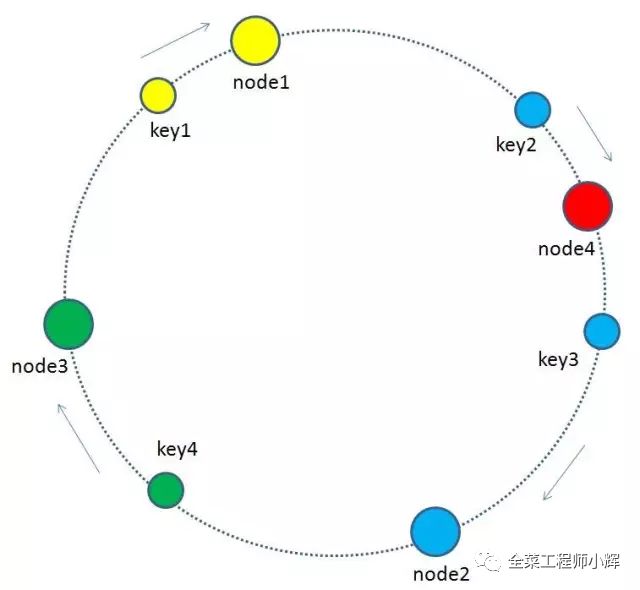
有哪些key会受到影响呢?图中加入了新节点node4,处于node1和node2之间,按照顺时针规则,从node1到node4之间的缓存不再归属于node2,而是归属于新节点node4。因此受影响的key只有key2。
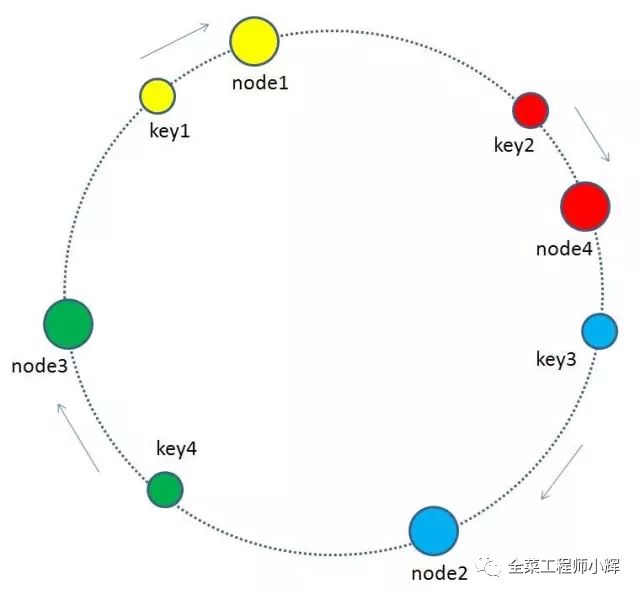
最终把key2的缓存数据从node2迁移到node4,就形成了新的符合一致性哈希规则的缓存结构。
删除节点 当缓存集群的节点需要删除的时候(比如节点挂掉),整个环形空间的映射同样会保持一致性哈希的顺时针规则,同样有一小部分key的归属会受到影响。
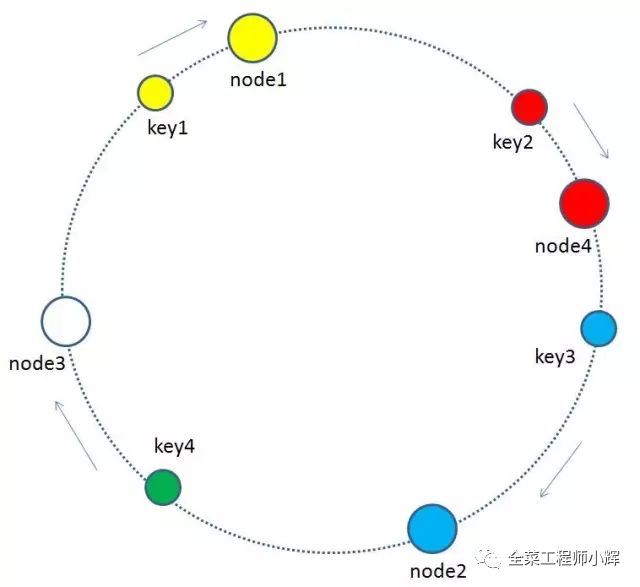
有哪些key会受到影响呢?图中删除了原节点node3,按照顺时针规则,原本node3所拥有的缓存数据就需要“托付”给node3的顺时针后继节点node1。因此受影响的key只有key4。
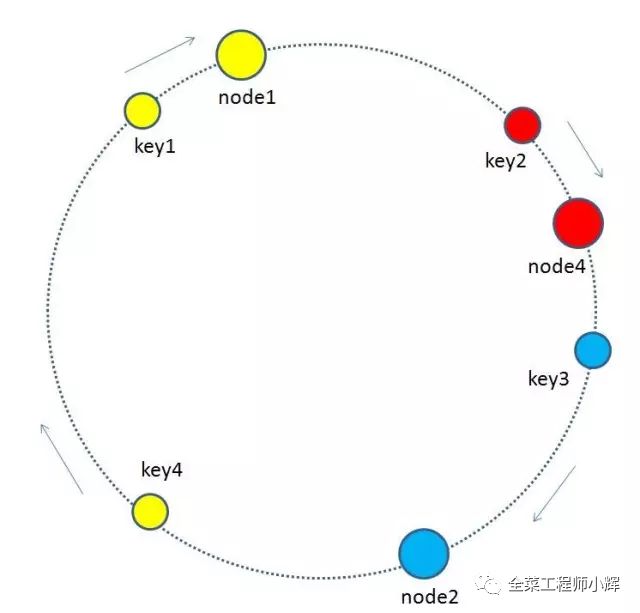
最终把key4的缓存数据从node3迁移到node1,就形成了新的符合一致性哈希规则的缓存结构。
说明:这里所说的迁移并不是直接的数据迁移,而是在查找时去找顺时针的后继节点,因缓存未命中而刷新缓存。
计算方法:假设节点hash散列均匀(由于hash是散列表,所以并不是很理想),采用一致性hash算法,缓存节点从3个增加到4个时,会有0-33%的缓存失效,此外新增节点不会环节所有原有节点的压力。
一致性hash算法的结果相比传统hash求余算法已经进步很多,但可不可以改进一下呢?或者如果出现分布不均匀的情况怎么办?比如下图这样,按顺时针规则,所有的key都归属于统一个节点。
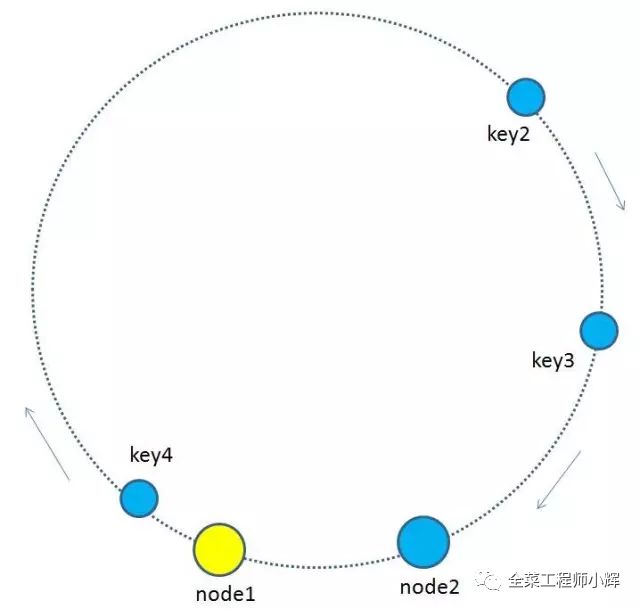
一致性hash算法+虚拟节点
为了优化这种节点太少而产生的不均衡情况。一致性哈希算法引入了虚拟节点的概念。
所谓虚拟节点,就是基于原来的物理节点映射出N个子节点,最后把所有的子节点映射到环形空间上。
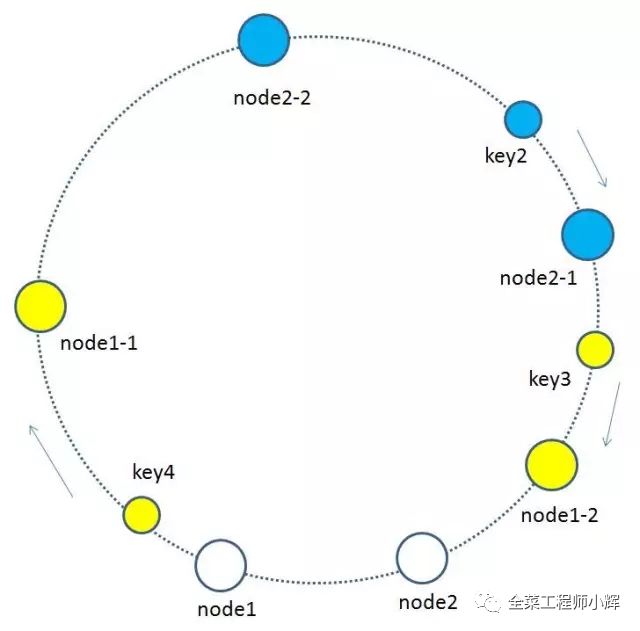
虚拟节点越多,分布越均匀。使用一致性hash算法+虚拟节点这种情况下,缓存节点从3个变成4个,缓存失效率为25%,而且每个节点都平均的承担了压力。
一致性hash算法+虚拟节点的实现
原理理解了,实现并不难,主要是一些细节:
hash算法的选择。Java代码不要使用hashcode函数,这个函数结果不够散列,而且会有负值需要处理。 这种计算Hash值的算法有很多,比如CRC32_HASH、FNV1_32_HASH、KETAMA_HASH等,其中KETAMA_HASH是默认的MemCache推荐的一致性Hash算法,用别的Hash算法也可以,比如FNV1_32_HASH算法的计算效率就会高一些。
数据结构的选择。根据算法原理,我们的算法有几个要求:
要能根据hash值排序存储
排序存储要被快速查找 (List不行)
排序查找还要能方便变更 (Array不行)
另外,由于二叉树可能极度不平衡。所以采用红黑树是最稳妥的实现方法。Java中直接使用TreeMap即可。
喜欢就点个“在看”呗^_^
以上是关于图解一致性hash算法和实现的主要内容,如果未能解决你的问题,请参考以下文章