不均衡样本集的重采样
Posted ottll
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了不均衡样本集的重采样相关的知识,希望对你有一定的参考价值。
在训练二分类模型时,例如医疗诊断、网络入侵检测、信用卡反诈骗等,经常会遇到正负样本不均衡的问题。是的,正样本很少,负样本一大堆。
对于很多分类算法,如果直接采用不均衡的样本集来进行训练学习,会存在一些问题。例如,如果正负样本比例达到1∶99,则分类器简单地将所有样本都判为负样本就能达到99%的正确率,显然这并不是我们想要的,我们想让分类器在正样本和负样本上都有足够的准确率和召回率。
采样,数据扩充
对于二分类问题,当训练集中正负样本非常不均衡时,如何处理数据以更好地训练分类模型?
为什么很多分类模型在训练数据不均衡时会出现问题?
本质原因是模型在训练时优化的目标函数和人们在测试时使用的评价标准不一致。是的。:
- 这种“不一致”可能是由于训练数据的样本分布与测试时期望的样本分布不一致,例如,在训练时优化的是整个训练集(正负样本比例可能是1∶99)的正确率,而测试时可能想要模型在正样本和负样本上的平均正确率尽可能大(实际上是期望正负样本比例为1∶1);
- 也可能是由于训练阶段不同类别的权重(重要性)与测试阶段不一致,例如训练时认为所有样本的贡献是相等的,而测试时假阳性样本(False Positive)和伪阴性样本(False Negative)有着不同的代价。是的,不同的代价
根据上述分析,一般可以从两个角度来处理样本不均衡问题[17]。
基于数据的方法
对数据进行重采样,使原本不均衡的样本变得均衡。首先,记样本数大的类别为Cmaj,样本数小的类别Cmin,它们对应的样本集分别为Smaj和Smin。根据题设,有 ∣Smaj∣>>|Smin|。
最简单的处理不均衡样本集的方法是随机采样。
采样一般分为过采样(Over-sampling)和欠采样(Under-sampling)。
- 随机过采样是从少数类样本集 SminSmin 中随机重复抽取样本(有放回)以得到更多样本;
- 随机欠采样则相反,从多数类样本集 S maj S maj 中随机选取较少的样本(有放回或无放回)。
感觉过采样和欠采样都有些问题吧。嗯,下面说了。
直接的随机采样虽然可以使样本集变得均衡,但会带来一些问题,比如:
- 过采样对少数类样本进行了多次复制,扩大了数据规模,增加了模型训练的复杂度,同时也容易造成过拟合;
- 欠采样会丢弃一些样本,可能会损失部分有用信息,造成模型只学到了整体模式的一部分。
是呀。
为了解决上述问题,通常在过采样时并不是简单地复制样本,而是采用一些方法生成新的样本。例如,SMOTE 算法对少数类样本集 Smin中每个样本 xx,从它在 Smin中的 K 近邻中随机选一个样本 y,然后在 x,y 连线上随机选取一点作为新合成的样本(根据需要的过采样倍率重复上述过程若干次),如图8.14所示。嗯,感觉有些厉害,但是这种合成要怎么合成?两个样本怎么合成成一个样本?
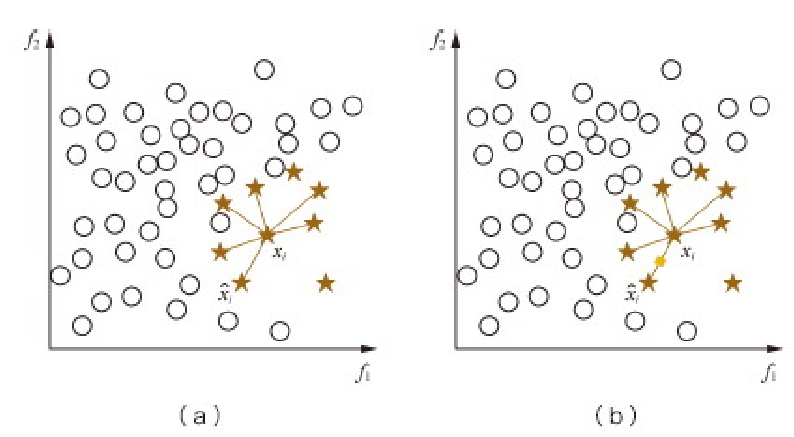
mark
这种合成新样本的过采样方法可以降低过拟合的风险。
SMOTE 算法为每个少数类样本合成相同数量的新样本,这可能会增大类间重叠度,并且会生成一些不能提供有益信息的样本。是呀。
为此出现 Borderline-SMOTE、ADASYN 等改进算法。
- Borderline-SMOTE 只给那些处在分类边界上的少数类样本合成新样本,
- 而 ADASYN 则给不同的少数类样本合成不同个数的新样本。
此外,还可以采用一些数据清理方法(如基于Tomek Links)来进一步降低合成样本带来的类间重叠,以得到更加良定义(well-defined)的类簇,从而更好地训练分类器。哇塞,这么厉害!简直了,各种手段,厉害!都要总结进来。
同样地,对于欠采样,可以采用 Informed Undersampling 来解决由于随机欠采样带来的数据丢失问题。常见的 Informed Undersampling 算法有:
- Easy Ensemble 算法。每次从多数类 Smaj 中上随机抽取一个子集 E(|E|≈|Smin|),然后用 E+Smin训练一个分类器;重复上述过程若干次,得到多个分类器,最终的分类结果是这多个分类器结果的融合。嗯,感觉还是有道理的。
- Balance Cascade 算法。级联结构,在每一级中从多数类 Smaj 中随机抽取子集 EE ,用 E+Smin 训练该级的分类器;然后将Smaj中能够被当前分类器正确判别的样本剔除掉,继续下一级的操作,重复若干次得到级联结构;最终的输出结果也是各级分类器结果的融合。是的,这个感觉类似决策树。
- 其他诸如 NearMiss(利用K近邻信息挑选具有代表性的样本)、One-sided Selection(采用数据清理技术)等算法。这些也要总结下。
在实际应用中,具体的采样操作可能并不总是如上述几个算法一样,但基本思路很多时候还是一致的。例如:
- 基于聚类的采样方法,利用数据的类簇信息来指导过采样/欠采样操作;
- 经常用到的数据扩充方法也是一种过采样,对少数类样本进行一些噪声扰动或变换(如图像数据集中对图片进行裁剪、翻转、旋转、加光照等)以构造出新的样本;
- 而Hard Negative Mining则是一种欠采样,把比较难的样本抽出来用于迭代分类器。
基于算法的方法
在样本不均衡时,也可以通过改变模型训练时的目标函数(如代价敏感学习中不同类别有不同的权重)来矫正这种不平衡性;当样本数目极其不均衡时,也可以将问题转化为单类 学习(one-class learning)、异常检测(anomaly detection)。本节主要关注采样,不再赘述。哇塞!思路清奇呀!竟然可以转化成单类检测和异常检测。嗯,还是要再补充下的。
总结与扩展
在实际面试时,这道题还有很多可扩展的知识点。例如:
- 模型在不均衡样本集上的评价标准
- 不同样本量(绝对数值)下如何选择合适的处理方法(考虑正负样本比例为1∶100和1000∶100000的区别)
- 代价敏感学习和采样方法的区别、联系以及效果对比等。嗯,这个也想知道。
这些都要总结,弄清楚。
原文及相关
- 《百面机器学习》
以上是关于不均衡样本集的重采样的主要内容,如果未能解决你的问题,请参考以下文章