上采样/下采样
Posted 豆咂---
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了上采样/下采样相关的知识,希望对你有一定的参考价值。
上采样/下采样
样本不均衡时解决方式
在实际应用中经常出现样本类别不均衡的情况,此时可以采用上采样或者下采样方法
上采样upsampling
上采样就是以数据量多的一方的样本数量为标准,把样本数量较少的类的样本数量生成和样本数量多的一方相同,称为上采样。
下采样subsampled
下采样,对于一个不均衡的数据,让目标值(如0和1分类)中的样本数据量相同,且以数据量少的一方的样本数量为准。获取数据时一般是从分类样本多的数据中随机抽与少数量样本等数量的样本。
上采样SMOTE
SMOTE(Synthetic Minority Oversampling Technique)合成少数类过采样技术,SMOTE算法的基本思想是对少数类样本进行分析并根据少数类样本人工合成新样本添加到数据集中 。
算法流程如下:
1. 对于少数类中的每一个样本x,用欧式距离为标准计算它到少数类样本集中所有样本的距离,得到其k近邻
2. 确定采样倍率N,对于每一个少数类样本x,从其k近邻中随机选择若干个样本,假设选择的近邻为xi
3. 对于每一个随机选出的近邻xi,分别与原样本按照如下的公式构建新的样本
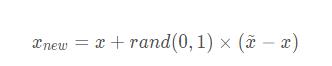
即x和xi之间的连线上随机选一点作为新构造的样本
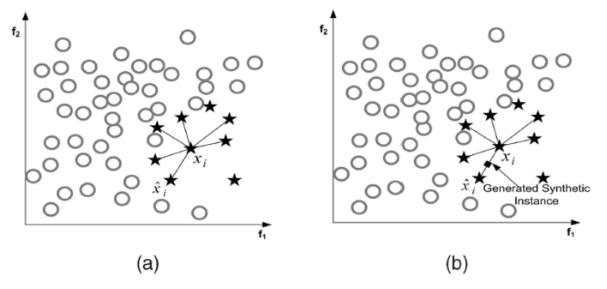
生成样本的数量和分类样本较多的数据量保持一致。
使用代码:
from imblearn.over_sampling import SMOTE sm = SMOTE(random_state = 42, n_jobs = -1) x, y = sm.fit_sample(x_val, y_val)
函数说明:
imblearn.over_sampling.SMOTE(
sampling_strategy = ‘auto’,
random_state = None, ## 随机器设定
k_neighbors = 5, ## 用相近的 5 个样本(中的一个)生成正样本
m_neighbors = 10, ## 当使用 kind={\'borderline1\', \'borderline2\', \'svm\'}
out_step = ‘0.5’, ## 当使用kind = \'svm\'
kind = \'regular\', ## 随机选取少数类的样本
– borderline1: 最近邻中的随机样本b与该少数类样本a来自于不同的类
– borderline2: 随机样本b可以是属于任何一个类的样本;
– svm:使用支持向量机分类器产生支持向量然后再生成新的少数类样本
svm_estimator = SVC(), ## svm 分类器的选取
n_jobs = 1, ## 使用的例程数,为-1时使用全部CPU
ratio=None )
参考文档:
https://blog.csdn.net/nextdoor6/article/details/82832593
https://blog.csdn.net/haoji007/article/details/106166305/
以上是关于上采样/下采样的主要内容,如果未能解决你的问题,请参考以下文章