[1] 样本不均衡问题及其解决办法
Posted 猿上加猿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[1] 样本不均衡问题及其解决办法相关的知识,希望对你有一定的参考价值。
样本不均衡问题及其解决办法
1 样本不均衡的问题
对分类的影响:分类模型中,模型更偏向对多数类的预测概率,从而导致少数类的预测精度大幅度下降,虽然整体来看精度很好,但这与实际工作不符。
通过make_classification方法创建随机的n类分类数据集
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=5000, #样本总数
n_features=2, #特征数(包含信息特征数、冗余特征数)
n_informative=2, #信息特征数
n_redundant=0, #冗余特征数
n_repeated=0, #从信息特征数和冗余特征数中重复抽取的数目
n_classes=3, #类别数
n_clusters_per_class=1, #每个类的聚类数
weights=[0.05, 0.1, 0.85], #每个类的概率
class_sep=0.8, #值越大,类与类之间分的越开
random_state=0) #随机种子
该数据集分布情况如下:
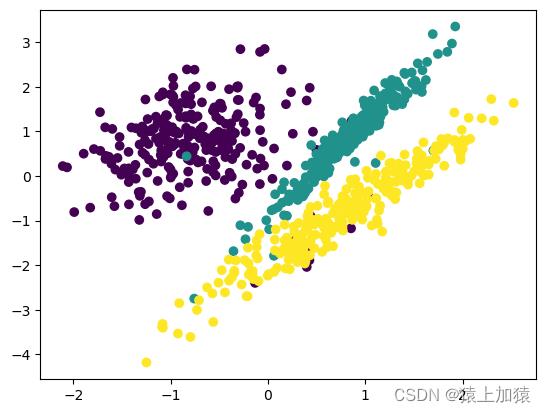
此时不同类的数据分布相对紧密,易于分类。
2 imbalanced-learn库
安装代码:
conda install -c conda-forge imbalanced-learn
环境依赖:

注意一定要检查环境依赖,之前在深度学习的环境里安装的时候因为某几个库的版本过高,导致最后没安装成功。
网址:
https://imbalanced-learn.org/stable/references/index.html
imbalanced库中提供:
- 过采样算法
- 欠采样算法
- 不平衡的数据集
- 解决数据不平衡问题的集成算法
- 工具
- 数据不平衡的解决案例
但是我们需要谨慎使用这些算法,因为它们往往会改变数据的原始分布。
3 重采样
3.1 欠采样
目的:减少多数类的数量。
3.1.1 随机欠采样
原理:从多数类中随机选择一些样样本组成样本集。
代码:
under_random = RandomUnderSampler(random_state = 1, sampling_strategy='auto')

3.1.2 NearMiss算法
原理:
- NearMiss-1:在多数样本中选择出与少数样本最近的K个样本的平均距离最小的样本。
- NearMiss-2:在多数样本中选择出与少数样本最远的K个样本的平均距离最小的样本。
- NearMiss-3:对于每个少数类别样本,选择离它近的K个多数类别样本。
代码:
under_nm1 = NearMiss(version = 1, n_neighbors = 3)
under_nm2 = NearMiss(version = 2, n_neighbors = 3)
under_nm3 = NearMiss(version = 3, n_neighbors = 3)



3.1.3 ENN
原理:遍历多数类的样本,如果他的大部分k近邻样本都跟他自己本身的类别不一样,我们就将他删除。
代码:
under_enn1 = EditedNearestNeighbours(kind_sel="all") #default
under_enn2 = EditedNearestNeighbours(kind_sel="mode")
参数kind_sel:
- ‘all’:所有k个近邻点都不属于多数类
- ‘mode’:超过半数的近邻点不属于多数类


3.1.4 RENN
原理:重复以上ENN的过程直到没有样本可以被删除。
代码:
under_renn = RepeatedEditedNearestNeighbours()

3.1.5 Tomek Link Removal
原理:将组成Tomek link的两个样本,如果有一个属于多数类样本,就将该多数类样本删除掉。
![[Pasted image 20230308131428.png|300]]
代码:
under_tlr = TomekLinks()

3.2 欠采样
目的:为少数类别增加新样本
3.2.1 随机过采样
原理:在少数类中选择部分样本进行复制,从而扩大少数累的样本量
代码:
over_random = RandomOverSampler(random_state = 1, sampling_strategy='auto')

3.2.2 SMOTE
原理:对随机过采样方法的一个改进算法,通过对少数类样本进行插值来产生更多的少数类样本。
缺点:
- 生成的样本可能重叠
- SMOTE算法对于每个原少数类样本产生相同数量的合成数据样本,而没有考虑其邻近样本的分布特点
代码:
over_somte = SMOTE(sampling_strategy='auto', random_state = 1, k_neighbors = 3)

3.2.3 BorderlineSMOTE
原理:将样本分为safe、danger、noise,仅对danger的样本进行smote采样
- Noise: 所有的k近邻个样本都属于多数类;
- Danger : 超过一半的k近邻样本属于多数类;
- Safe: 超过一半的k近邻样本属于少数类。
代码:
over_blsmote = BorderlineSMOTE(sampling_strategy='auto', random_state = 1, k_neighbors = 3)

3.2.4 ADASYN
原理:就是对不同的样本赋予不同的权重,从而通过smote算法生成不同数量的样本,往往样本k近邻上的多数类样本越多,该样本生成的样本也越多
代码:
over_adasyn = ADASYN(sampling_strategy='auto', random_state = 1, n_neighbors = 3)

以及部分数据增强的方法
3.3 过采样和欠采样结合
原理:由于在过采样的过程中,会出现重复样本,因此需要欠采样中的数据清洗方法对重复样本进行剔除。先进行过采样,再通过欠采样中的算法对重复样本进行剔除
代码:
steps1 = [('o',over_somte),('u',under_tlr)]
pipeline1 = Pipeline(steps = steps1)
4 数据增强
4.1 图像领域数据增强方法
4.1.1 几何变换
翻转,旋转,裁剪(Cutout),变形,缩放
4.1.2 像素变换
噪声、模糊、颜色变换、擦除、填充
4.1.3 经典数据增强模型
- SamplePairing
- Random Erasing Data Augmentation(随机擦除数据增强)
- RandAugment(随机增强)
- cutout、mixup、cutmix
- Mosaic Data Augmentation(马赛克数据增强)
4.1.4 经典生成模型
- GAN(生成对抗网络)
- VAE(变分自编码器模型)
4.1.5 学习增强策略
- Autoaugmentation(Google提出的自动选择最优数据增强方案)
4.2 文本数据增强模型
- Easy Data Augmentation(EDA):EDA是一种简单但非常有效的方法,具体包括随机替换,随机插入,随机交换,随机删除等。
- An Easier Data Augmentation(AEDA):在句子中间添加标点符号以此来增强数据。
- Back translation:对本文进行翻译,再翻译回来。
- Masked Language Model:掩码语言模型,利用预训练好的BERT, Roberta等模型,对原句子进行部分掩码,然后让模型预测掩码部分,从而得到新的句子。
- Random Noise Injection:在文本中注入噪声,来生成新的文本,最后使得训练的模型对扰动具有鲁棒性。
- Instance Crossover Augmentation:两个相同情绪类别(正/负)的 tweets 各自交换一半的内容。
- Syntax-tree Manipulation:解析并生成原始句子的依赖树,使用规则对其进行转换来对原句子做复述生成。
- MixUp for Text:worldMixup、sentMixup
- Conditional Pre-trained Language Models:通过文本生成的方法来增加样本,属于生成模型。
以上是关于[1] 样本不均衡问题及其解决办法的主要内容,如果未能解决你的问题,请参考以下文章
机器学习sklearn----支持向量机SVC中的样本不均衡问题
机器学习sklearn----支持向量机SVC中的样本不均衡问题
机器学习sklearn----支持向量机SVC中的样本不均衡问题