机器学习sklearn----支持向量机SVC中的样本不均衡问题
Posted iostreamzl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习sklearn----支持向量机SVC中的样本不均衡问题相关的知识,希望对你有一定的参考价值。
文章目录
前言
在分类问题中永远存在一个问题:样本不均衡
比如我们的一个二分类数据集,其中1占比3%,0占比97%。这就是一个典型的样本不均衡数据集。但是我们的需求往往都是捕捉到这少数的样本,也就是将少数类尽量多的判断正确。
但是我们的模型默认时样本均衡的,这样就会带来一些问题
首先,模型分类时会更加的倾向于多数类,让多数类更加容易被判对,会牺牲掉少数类来保证多数类的判别效果。 但是这样的模型显然不是我们需要的
其次,模型的评估指标会失去意义,因为即使我们什么都不做,只是将所有的样本都判别为0,那样的准确率也是达到了97%,显然这样是没有意义的
本文中使用的第三方库
import numpy as np
from sklearn.datasets import make_blobs
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
%matplotlib inline
样本不均衡的解决办法
- 上采样或下采样:缺点增加大量的样本数量,这对SVC这种耗时的模型非常的不友好
- 采用模型自身的样本均衡参数:SVC实例化时的参数class_weight,或者模型训练fit时的参数sample_weight。
需要注意的时:class_weight是一个字典的形式 标签 : 权重。一般来说少数类占有较高的权重。sample_weight需要和标签有一样的shape。每一个标签对应一个权重。
实例
创建数据集,包含550个样本,0类500个,1类100个
# 创建一个样本不均衡的数据集
X, y = make_blobs(n_samples=[500, 50],
n_features=2,
cluster_std=3,
random_state=3)
plt.scatter(X[:, 0], X[:, 1], c=y)
plt.show()
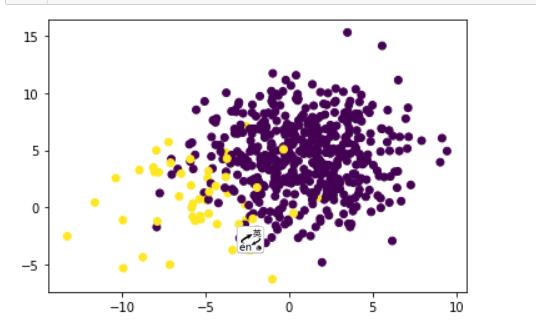
是否均衡样本的模型比较
# 不采用样本均衡SVC模型效果
svc_none_class_weight = SVC(kernel='linear').fit(X, y)
scores = svc_none_class_weight.score(X, y)
scores # 0.9490909090909091
# 采用样本均衡参数class_weight
svc_with_class_weight = SVC(kernel='linear', class_weight=1: 10).fit(X, y)
svc_with_class_weight.score(X, y) # 0.8836363636363637
可以看到不采用样本均衡的模型精确度较高(实际上没有意义),这是由于模型保证了多数类尽量多判断正确,而采用了样本均衡后,模型会将多数类判断为少数类
通过两个模型的决策边界比较
# 画出两个模型的决策边界,来比较模型的分类效果
plt.figure(figsize=(10, 5))
# 画出原始数据分布图
ax = plt.gca() # 获得当前子图对象,不存在则创建
ax.scatter(X[:, 0], X[:, 1], c=y, s=20)
# 画决策边界
# 1.网格坐标构建
xmin, xmax = X[:, 0].min(), X[:, 0].max()
ymin, ymax = X[:, 1].min(), X[:, 1].max()
xloc, yloc = np.meshgrid(np.linspace(xmin, xmax, 50),
np.linspace(ymin, ymax, 50))
coo = np.vstack([xloc.ravel(), yloc.ravel()]).T
# 2.计算样本点到决策边界的距离
dis_none_clsw = svc_none_class_weight.decision_function(coo).reshape(xloc.shape)
dis_with_clsw = svc_with_class_weight.decision_function(coo).reshape(xloc.shape)
# 3.画出高度值为0的等高线就是决策边界
none_line = ax.contour(xloc, yloc, dis_none_clsw, colors='black', levels=[0])
with_line = ax.contour(xloc, yloc, dis_with_clsw, colors='yellow', levels=[0])
# 显示图例
ax.legend(handles=[none_line.collections[0], with_line.collections[0]],
loc='best', labels=['none class weight', 'with class weight'])
plt.show()
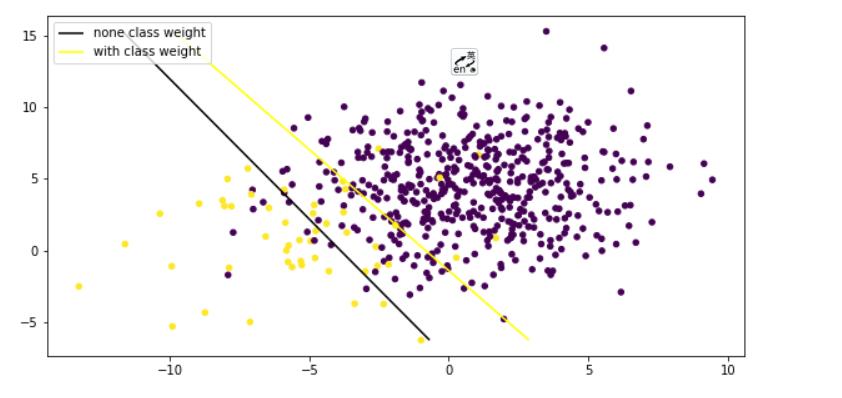
从图上可以看出没有采用样本均衡的模型有很大一部分少数类被舍弃掉被归为了多数类
而采用了样本均衡之后,少数类尽量多的被判断准确了,将部分多数类判别为了少数类
以上是关于机器学习sklearn----支持向量机SVC中的样本不均衡问题的主要内容,如果未能解决你的问题,请参考以下文章