LiteDB源码解析系列数据库页详解
Posted xiaozhangstudent
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LiteDB源码解析系列数据库页详解相关的知识,希望对你有一定的参考价值。
1.LiteDB页的技术工作原理
LiteDB虽然是单个文件类型的数据库,但是数据库有很多信息,例如索引,集合,文件等。为了管理这些信息,LiteDB实现了数据库页的概念。页是一个拥有4096 字节的 存储相同信息的地址块。页也是操作磁盘文件(读写)的最小单元。LiteDB有6中页类型,类图如下:
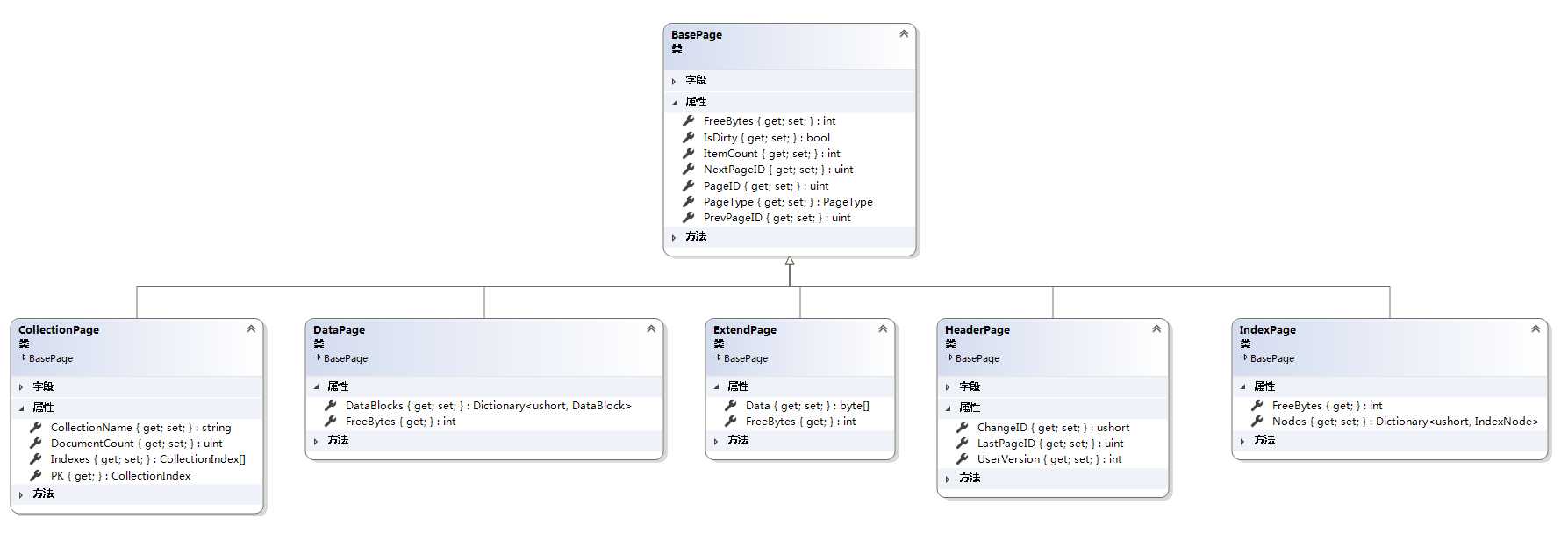
1.1 BasePage
BasePage是数据库页类型的父类,使用一个常量字段PAGE_SIZE定义了页的大小为4096个字节。
主要的属性说明如下:
PageID:一个uint类型的ID,在LiteDB数据库中,不管是哪种页类型,这个PageID都是不一样的。
PrevPageID:指向上一页的ID。如果指向一个uint的最大值(4294967295)即表示没有上一页。
NextPageID:指向下一页的ID。如果指向一个uint的最大值(4294967295)即表示没有页一页。从这里看页的结构有点像双向链表,但在实际存储中,页与页之间貌似并不是以链表形式存储(可能我这里也没太搞明白这两个ID的具体作用)。
PageType:一个页类型的枚举,根据这个枚举,可以将BasePage强制转换成相对应的页类型。
ItemCount:一个用于计算页中的特定数据大小的ItemCount,在DataPage和IndexPage中可以看到它的作用。
IsDirty:从名称我们可以大概猜出它的作用,在LiteDB中专门用来标记该页的数据是否完成Commit操作。
FreeBytes:这个属性需要各个子类重写,用于计算该页还有多少可用的字节。
1.2 CollectionPage
一个CollectionPage就代表一张表,比如数据库中有Customer和Order两张表,那么在数据库中就存在两个CollectionPage分别存储这两张表的信息。CollectionPage之间用 Prev/Next 连接。
CollectionPage中有一个CollectionName代表了该表的名称,比如Customer和Order两张表就有两个名称分别为“Customer“和“Order”。DocumentCount属性标志着该表有多少条记录,比如向Customer表插入100条数据,那么DocumentCount就为100。
CollectionPage里面最主要的一个属性Indexes,这是一个自定义结构体CollectionIndex的数组,它代表了该表中的所有索引名称。比如Customer表中有三个字段分别“ID”、“Name”、“Age”,(特别强调,这三个字段都要作为索引)那么Indexes数组就分别包含了这三个字段。同时可以看到这个页中有个叫PK的属性,根据名称我们大致就知道它肯定是主键,比如上面Customer表中的“ID”。
1.3 HeaderPage
HeaderPage存储了当前使用的LiteDB数据库的一些信息,包括头文件,数据库版本,可用的空余页ID,用户版本等。其中有个名为ChangeID的属性,这个是用于处理事务时,验证客户端中的ChangeID是否一致。
1.4 DataPage
DataPage就是数据页,它的结构最简单,除了父类之外只包含一个名为DataBlocks的字典,这个字典Key是一个ushort数字,Value是一个DataBlock类。后面我们通过分析DataBlock这个结构体就大致能知道DataPage的作用。同时在数据页中还可以看到它重写FreeBytes属性就是可用字节减去字典长度,ItemCount就等于字典长度。
1.5 ExtendPage
ExtendPage是数据扩展页,如果插入的数据过大时,就讲超过Page的数据块放入ExtendPage中的Data中,同样它重写FreeBytes属性就是可用字节减去Data的长度。
1.6 IndexPage
IndexPage就是索引页,它的结构和DataPage类似,只包含了一个名为Nodes的字典,这个字典中key是一个ushort数字,Value是一个IndexNode类,索引使用跳表的形式进行存储。
2. 数据可视化——掀开Page的面纱
可能看完上面说明,你可能对数据页仍然是一头雾水,我在看源码的时候也是如此。后来经过我各种努力,想出了 一个办法,就是将页的信息实时展示出来,也就是常说的数据可视化。后面我会专门介绍如何把数据页的信息展示出来,这里大家先跟着往下看。
首先我们先创建一个数据库:
LiteEngine db = new LiteEngine(Path);
下面我用winfrom做的界面,Header下面的列表就表示所有的HeaderPage信息,其他也类似。由于ExtendPage功能比较简单,所以没把ExtendPage的信息展示出来。在执行完这条命令后,界面中就可以看到有两个页被创建了:

我们可以看到HeaderPage和CollectionPage各创建一页,HeaderPage因为是要存放数据库的信息,所以在数据库一被创建就有且只有一页,后面再添加新的表,HeadPage也只有这一页。CollectionPage为什么会有一条呢,看它的表名称,你就知道了,master表,是不是很熟悉?没错,和Sqlserver数据库的系统数据库类似,只不过我确实看不出来LiteDB里面的这张master表作用。

然后我们在添加一张名为customer的表,字段分别是ID,Age,Name,Address。即执行下面一段话:
var col = db.GetCollection<Customer>("customer"); col.EnsureIndex("Age");//确定Age字段为索引 col.EnsureIndex("Name");//确定Name字段为索引
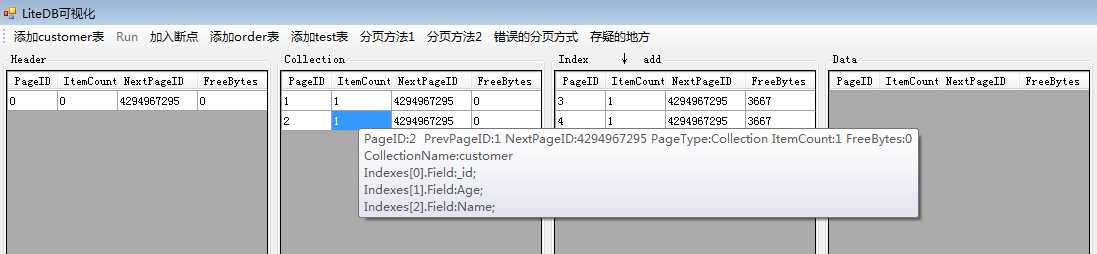
执行完之后,我们可以看见有CollectionPage中有一个新表被创建,它的表名为customer,这个page中有三个表索引,分别就是默认的ID主键,然后是Age和Name,注意字段Address并没有添加进去。
IndexPage增加了三页,每页对应一个索引,同时页里面只有一个索引节点(IndexNode)。
DataPage数据页目前还是空的。
我们再插入3条记录,执行语句如下:
for (int i = 0; i < 3; i++) var customer = new Customer Id = i, Name=i%2==1?"Jim1_"+i.ToString():"Jim2_"+i.ToString(), Age = i*10, Address = "Dump" col.Insert(customer);
然后我们就能够看到每个索引页多了三个索引节点,同时数据页也创建了一页。最后我们再添加两张表,一张Order表字段为ID,Ordersum。另一张Product表为Id,ProductName和ProductPrice。两张表的字段全都设成索引,数据页结构如下:
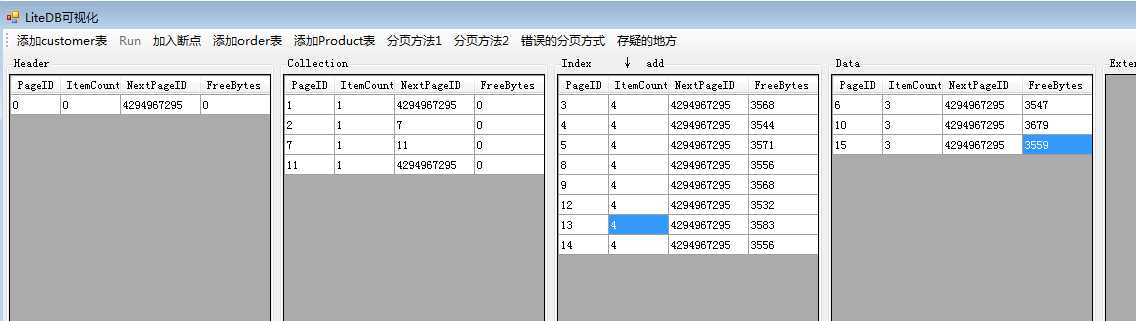
从上面的可以清楚看到,每添加一张表,就会创建一个CollectionPage页,向表里添加数据的同时,如果有索引添加,那么IndexPage页里相应内容也会添加。把上面图中数据再详细绘制出来就是下面这个结构:
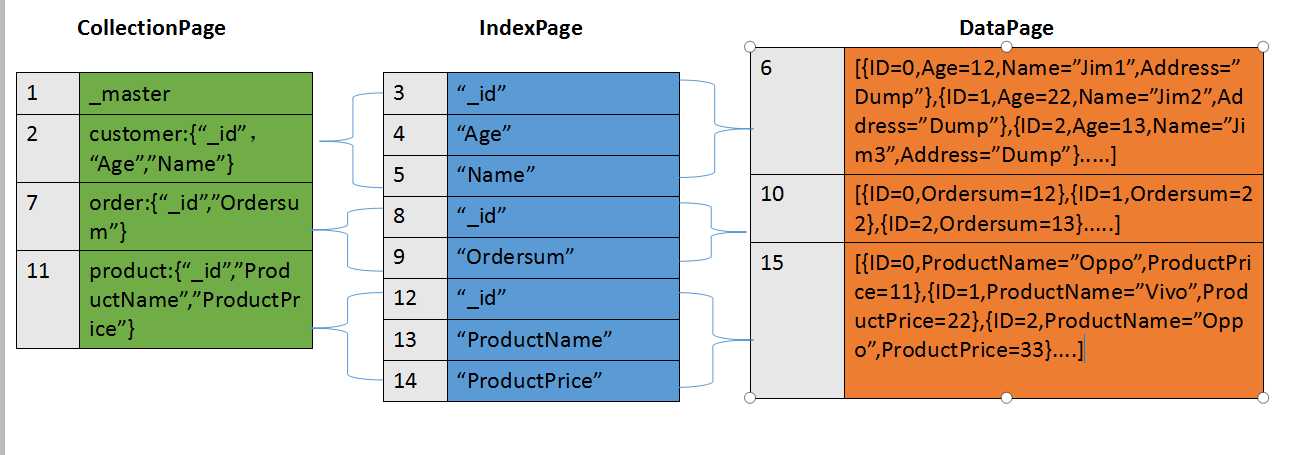
从这张图,大家应该很容易就看懂这几种页类型的作用。注意当前0.0.8版本的ID要指定为BsonID,在内部会改为"_id",这也是这个版本在某些地方出bug的原因。同时DataPage里面存的数据并不是图上面的json格式而是Byte数组。
3.后面的话
这章博客写完,我才知道想把一件事情说明白真是不容易,况且是比较复杂的源码。相信我会坚持更新,也希望能与看我博客的各位大神多多交流。
以上是关于LiteDB源码解析系列数据库页详解的主要内容,如果未能解决你的问题,请参考以下文章
对抗生成网络GAN系列——Spectral Normalization原理详解及源码解析