Flink 源码:Checkpoint 元数据详解
Posted zhisheng_blog
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink 源码:Checkpoint 元数据详解相关的知识,希望对你有一定的参考价值。
Flink 从入门到精通 系列文章
本文是 Flink 源码解析系列,通过阅读本文你能 get 到以下点:
Flink 任务从 Checkpoint 处恢复流程概述
Checkpoint 元数据详解
从源码层分析:JM 该如何合理地给每个 subtask 分配 State,让 TM 去恢复
❝声明:笔者的源码分析都是基于 flink-1.9.0 release 分支,其实阅读源码不用非常在意版本的问题,各版本的主要流程基本都是类似的。如果熟悉了某个版本的源码,之后新版本有变化,我们重点看一下变化之处即可。
笔者阅读源码中会加很多中文注释,对源码感兴趣且有需要的同学可以关注一下笔者的 github 仓库:https://github.com/1996fanrui/flink/tree/feature/source-code-read-1-9-0
注释都在 feature/source-code-read-1-9-0 分支,之后也会持续更新
❞
阅读本文之前,强烈建议阅读《从 KeyGroup 到 Rescale》,本文讲述 KeyedState 恢复时需要用到 KeyGroup 相关知识。
一、Job 从 Checkpoint 处恢复流程概述
Flink 任务从 Checkpoint 或 Savepoint 处恢复的整体流程简单概述,如下所示:
首先客户端提供 Checkpoint 或 Savepoint 的目录
JM 从给定的目录中找到 _metadata 文件(Checkpoint 的元数据文件)
JM 解析元数据文件,做一些校验,将信息写入到 zk 中,然后准备从这一次 Checkpoint 中恢复任务
JM 拿到所有算子对应的 State,给各个 subtask 分配 StateHandle(状态文件句柄)
TM 启动时,也就是 StreamTask 的初始化阶段会创建 KeyedStateBackend 和 OperatorStateBackend
创建过程中就会根据 JM 分配给自己的 StateHandle 从 dfs 上恢复 State
由上述流程可知,Flink 任务从 Checkpoint 恢复不只是说 TM 去 dfs 拉状态文件即可,需要 JM 先给各个 TM 分配 State,由于牵扯到修改并发,所以 JM 端给各个 subtask 分配 State 的流程也是比较复杂的。本系列源码分析会陆续分析上述所有列出的流程,东西比较多。
本文从 Checkpoint 的元数据入手开始分析,同时分析一下 JM 拿到 Checkpoint 元数据后该如何合理地给每个 subtask 分配 State,让 TM 去恢复。
二、 Checkpoint 元数据介绍
开始介绍 Checkpoint 元数据,这里是从元数据的设计角度来分析。后期在分析 Checkpoint 过程的源码时,会详细介绍这些元数据是如何一步步生成的。
Checkpoint 完整的元数据
CompletedCheckpoint 封装了一次 Checkpoint 完整的元数据信息,CompletedCheckpoint 类包含的属性如下所示:
public class CompletedCheckpoint implements Serializable
private final JobID job;
private final long checkpointID;
private final long timestamp;
private final long duration;
/** 本次 Checkpoint 中每个算子的 ID 及算子对应 State 信息 */
private final Map<OperatorID, OperatorState> operatorStates;
private final CheckpointProperties props;
private final Collection<MasterState> masterHookStates;
// Checkpoint 存储路径
private final CompletedCheckpointStorageLocation storageLocation;
// 元数据句柄
private final StreamStateHandle metadataHandle;
// Checkpoint 目录地址
private final String externalPointer;
private transient volatile CompletedCheckpointStats.DiscardCallback discardCallback;
CompletedCheckpoint 类的大部分属性都是见名之意的,重要的属性就是本次 Checkpoint 中每个算子的 OperatorID 及算子对应 State 信息。再次强调源码中的 OperatorState 这个类不是 Flink 中常说的 OperatorState,而是指代 Operator 算子对应的 State 信息。
算子级别的元数据
OperatorState 类的属性如下所示:
public class OperatorState implements CompositeStateHandle
private final OperatorID operatorID;
// checkpoint 时算子的并行度
private final int parallelism;
// checkpoint 时算子的 maxParallelism
private final int maxParallelism;
// 当前 Operator 算子内,每个 subtask 持有的 State 信息,
// 这里 map 对应的 key 为 subtaskId,value 为 subtask 对应的 State,
// OperatorState 表示一个 算子级别的,OperatorSubtaskState 是 subtask 级别的。
// 如果一个算子有 10 个并行度,那么 OperatorState 有 10 个 OperatorSubtaskState
private final Map<Integer, OperatorSubtaskState> operatorSubtaskStates;
OperatorState 中包含算子对应的 OperatorID,checkpoint 时算子的并行度和 maxParallelism。
❝注:这里专门强调是 Checkpoint 时的并行度和 maxParallelism,因为这个 OperatorState 本来就是从 Checkpoint 中恢复出来的,所以这些元数据都属于 Checkpoint 发生时 Job 的一些属性。
有可能新运行的 Job 调整了算子的并行度,当然如果新 Job 的 maxParallelism 发生变化而且是人为设定,任务是无法恢复的(至于为什么无法恢复,前面的源码已经分析过了)。
❞
OperatorState 中还使用一个 Map 保存当前 Operator 算子内每个 subtask 持有的 State 信息,这里 map 对应的 key 为 subtaskId,value 为 subtask 对应的 State。OperatorState 表示算子级别的 State 元数据信息,OperatorSubtaskState 表示 subtask 级别的 State 元数据信息。如果一个算子有 10 个并行度,那么 OperatorState 内就会包含 10 个 OperatorSubtaskState。
subtask 级别的元数据
OperatorSubtaskState 类的属性如下所示:
public class OperatorSubtaskState implements CompositeStateHandle
private final StateObjectCollection<OperatorStateHandle> managedOperatorState;
private final StateObjectCollection<OperatorStateHandle> rawOperatorState;
private final StateObjectCollection<KeyedStateHandle> managedKeyedState;
private final StateObjectCollection<KeyedStateHandle> rawKeyedState;
private final long stateSize;
OperatorSubtaskState 类的属性看起来非常明了,Managed 两种 Raw 两种,Raw 这里不关注,所以这里重点关注 Managed 下的两种 State,即:managedOperatorState 和 managedKeyedState。
❝因为没用过 Raw 所以看源码略过了,不过从源码实现来看无论是 Raw 还是 Managed,他们的 Checkpoint 的元数据管理都是类似的,区别主要在于使用上。
❞
managedOperatorState 元数据维护在 OperatorStateHandle 中,managedKeyedState 元数据存储维护在 KeyedStateHandle 中。所以下面重点关注 OperatorStateHandle 和 KeyedStateHandle,这两部分内容较多,所以另外开了大标题。
这里同时留一个小疑问:OperatorSubtaskState 中维护的所有状态句柄,都是一个 Collection 集合,为什么是集合呢?稍后回答。
三、 OperatorStateHandle 介绍
OperatorStateHandle 是个接口,它只有一种实现,即:OperatorStreamStateHandle。所以具体分析 OperatorStreamStateHandle。
OperatorStreamStateHandle 相关源码如下所示:
public class OperatorStreamStateHandle implements OperatorStateHandle
// map 中 key 是 StateName,value 是 StateMetaInfo
// StateMetaInfo 中封装的是当前 State 在状态文件所处的 offset 和 Mode
private final Map<String, StateMetaInfo> stateNameToPartitionOffsets;
// OperatorState 状态文件句柄,可以读出状态数据
private final StreamStateHandle delegateStateHandle;
// OperatorState 分布模式的枚举
enum Mode
// 对应 getListState API
SPLIT_DISTRIBUTE,
// 对应 getUnionListState API
UNION,
// 对应 BroadcastState
BROADCAST
class StateMetaInfo implements Serializable
// 当前 State 在状态文件所处的 offset 和 Mode
private final long[] offsets;
// OperatorState 的分布模式
private final Mode distributionMode;
OperatorStreamStateHandle 维护了 OperatorState 状态文件句柄,根据 StreamStateHandle 可以读出状态文件的数据,即当前 subtask 可以从这个文件中读取状态数据。OperatorStreamStateHandle 还维护了一个 map,map 中 key 是 StateName,value 是 StateMetaInfo。StateMetaInfo 中封装的是当前 State 在状态文件所处的 offset 和 Mode。这里有了文件和 offset,就可以读出所有 State 的状态数据了。
在介绍一些 Mode 这个枚举,Mode 表示 OperatorState 分布模式的枚举,有三种类型,其中前两种 SPLIT_DISTRIBUTE 和 UNION 都对应的是 ListState,只不过恢复模式不同。
SPLIT_DISTRIBUTE表示每个 subtask 只获取一部分状态数据,即:所有 subtask 的状态加起来是一份全量的。UNION表示每个 subtask 获取一份全量的状态数据。
Mode 还有一种类型是 BROADCAST,对应的是 Flink 中的 BroadcastState。
思考题
这里再抛出分析 OperatorSubtaskState 源码时留下的问题:OperatorSubtaskState 中维护的所有状态句柄,都是一个 Collection 集合,例如 managedOperatorState 的类型是 StateObjectCollection<OperatorStateHandle> ,为什么这里是集合而不直接是 OperatorStateHandle 呢?难道 OperatorStateHandle 不能把当前 subtask 的所有 managedOperatorState 封装起来吗?
答:OperatorStateHandle 内维护了一个 map,保存了 Checkpoint 时当前 Operator 当前 subtask 内所有 managedOperatorState 的元数据信息。其实这里可以不用集合,一个 OperatorStateHandle 就足以保存 managedOperatorState 的元数据信息了。OperatorSubtaskState 内封装的是 OperatorStateHandle 的集合,其实 Checkpoint 生成元信息构造 OperatorSubtaskState 时,给 OperatorSubtaskState 传递的也不是 OperatorStateHandle 的集合,传递的就是一个 OperatorStateHandle。只不过 OperatorSubtaskState 构造器内将 OperatorStateHandle 封装成了集合。
我们可以看一下 OperatorSubtaskState 构造器源码:
public class OperatorSubtaskState implements CompositeStateHandle
// 集合构造器
public OperatorSubtaskState(
@Nonnull StateObjectCollection<OperatorStateHandle> managedOperatorState,
@Nonnull StateObjectCollection<OperatorStateHandle> rawOperatorState,
@Nonnull StateObjectCollection<KeyedStateHandle> managedKeyedState,
@Nonnull StateObjectCollection<KeyedStateHandle> rawKeyedState)
this.managedOperatorState = Preconditions.checkNotNull(managedOperatorState);
this.rawOperatorState = Preconditions.checkNotNull(rawOperatorState);
this.managedKeyedState = Preconditions.checkNotNull(managedKeyedState);
this.rawKeyedState = Preconditions.checkNotNull(rawKeyedState);
// 非集合构造器
public OperatorSubtaskState(
@Nullable OperatorStateHandle managedOperatorState,
@Nullable OperatorStateHandle rawOperatorState,
@Nullable KeyedStateHandle managedKeyedState,
@Nullable KeyedStateHandle rawKeyedState)
this(
singletonOrEmptyOnNull(managedOperatorState),
singletonOrEmptyOnNull(rawOperatorState),
singletonOrEmptyOnNull(managedKeyedState),
singletonOrEmptyOnNull(rawKeyedState));
private static <T extends StateObject> StateObjectCollection<T> singletonOrEmptyOnNull(T element)
return element != null ? StateObjectCollection.singleton(element) :
StateObjectCollection.empty();
可以看到 OperatorSubtaskState 有集合构造器和非集合构造器,非集合的构造器会将单个的 StateHandle 封装成集合,再调用集合构造器。
重点:Checkpoint 封装元数据时调用的就是非集合构造器,即每个 Operator 的每个 subtask 对应一个 managedOperatorState 的 StateHandle。问题在于为什么 OperatorSubtaskState 必须把这些 StateHandle 又封装成集合呢?
这么做为了从 Checkpoint 处恢复状态。举个例子,假如一个 Flink 任务并行度是 2,现在要将其并行度调为 1,整个流程如下:
对并行度为 2 的 Flink Job 触发 Checkpoint,生成快照
并行度为 1 的 Flink Job 从 Checkpoint 处恢复即可
生成的快照是两个 subtask,会生成两个 managedOperatorState 的 StateHandle,而新的 Job 并行度为 1,即:一个 subtask 要恢复两个 managedOperatorState 的 StateHandle。基于此所以 OperatorSubtaskState 需要将 StateHandle 封装为集合。
讲到这里,读者应该对 Flink Checkpoint 的元数据有一丝感觉了,其实 JM 后续分配 State 的流程就是给每个 subtask 合理的分配上述这些 StateHandle。每个 subtask 接受到的 StateHandle 就是自己要读取的状态数据。
四、 KeyedStateHandle 介绍
KeyedStateHandle 的子类比较多,如下图所示是 KeyedStateHandle 及其子类:
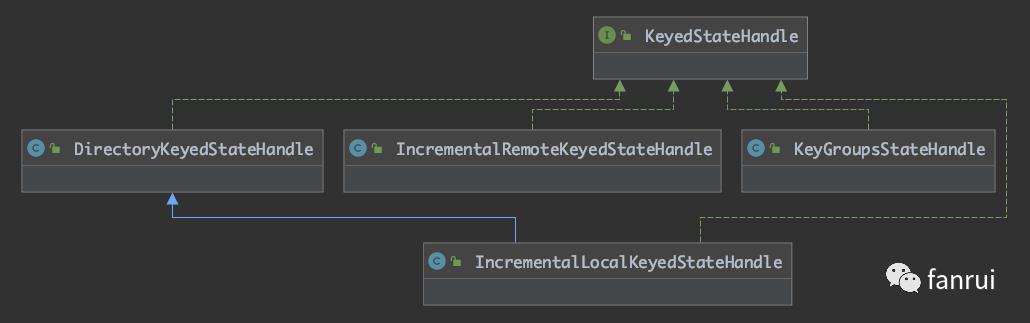
其中 KeyGroupsStateHandle 最为常用,应用于 Fs 或 RocksDB 的 Full 模式。
IncrementalRemoteKeyedStateHandle 应用于 RocksDB 的 Increment 模式。
IncrementalLocalKeyedStateHandle 和 DirectoryKeyedStateHandle 是对 RocksDB Increment 模式的优化。RocksDB 在 Increment 模式开启 local-recovery,可以在本地目录存放一份 State,当从 Checkpoint 处恢复时,不用去 dfs 去拉,而是直接从本地目录恢复 State。
❝附加小彩蛋:如果之前看过 TM 端基于 RocksDB Increment Remote 模式恢复任务时,就会发现第一步是先去 dfs 去拉状态文件,拉完文件后状态文件就到了本地目录,其实就变成了 Local 模式,第二步就复用 Local 模式的 Checkpoint 恢复逻辑。后续也会有 TM 端恢复 State 的源码分析。
❞
多种实现类,下面具体分析一下 KeyGroupsStateHandle 和 IncrementalRemoteKeyedStateHandle。Increment Local 模式本文就不分析了,Increment Local 模式与 Remote 模式比较类似,区别在于 Local 保存的文件句柄变成了本地的一个目录而已。
KeyGroupsStateHandle 介绍
KeyGroupsStateHandle 类相关源码如下所示:
public class KeyGroupsStateHandle implements StreamStateHandle, KeyedStateHandle
// KeyedState 状态文件句柄,可以读出状态数据
private final StreamStateHandle stateHandle;
// KeyGroupRangeOffsets 封装了当前负责的 KeyGroupRange
// 及 KeyGroupRange 中每个 KeyGroup 对应的 State 在 stateHandle 的 offset 位置
private final KeyGroupRangeOffsets groupRangeOffsets;
public class KeyGroupRangeOffsets implements Iterable<Tuple2<Integer, Long>>
, Serializable
// 当前 Operator 当前 subtask 负责的 KeyGroupRange
private final KeyGroupRange keyGroupRange;
// 数组保存了每个 KeyGroup 对应的 offset,
// 所以:数组的长度 == keyGroupRange 中 KeyGroup 的数量
private final long[] offsets;
KeyGroupsStateHandle 封装了 KeyedState 状态文件句柄,可以读出状态数据,同时还封装了 KeyGroupRangeOffsets。KeyGroupRangeOffsets 封装了当前负责的 KeyGroupRange 及 KeyGroupRange 中每个 KeyGroup 对应的 State 在 stateHandle 的 offset 位置。
也就是说 KeyGroupsStateHandle 可以读取文件,也知道每个 KeyGroup 在文件中的 offset,理所当然就可以在文件中读到每个 KeyGroup 的状态数据了。
在 《从 KeyGroup 到 Rescale》文章中讲到 KeyedState 分发时是以 KeyGroup 为最小单元的,即:不可能将同一个 KeyGroup 的数据分到两个 subtask 中,所以恢复状态时可以读到每个 KeyGroup 的数据就足够了,并不需要读到每个 Key 的数据。
KeyGroupsStateHandle 模式下,JM 该如何给各 subtask 分配 State?
这里顺便可以想一下,KeyGroupsStateHandle 模式下,JM 会怎么去给 TM 分配 State 呢?
如果不修改并发,每个新的 subtask 负责的 KeyGroupRange 与之前旧的 subtask 相同,所以 JM 直接把 Checkpoint 中保存的 KeyGroupsStateHandle 分配给新的给 subtask 即可。
修改并发的情况可能稍微复杂,举个例子:现在当前 subtask 负责的 KeyGroupRange(10,19) 即负责的 KeyGroupId 范围是 10~19,那么 offsets[] 数组中就有 10 个元素,假设 offsets 是 100,110,120,130,140,150,160,170,180,190。
新的任务 subtask A 负责 KeyGroupRange(10,14),subtask B 负责 KeyGroupRange(15,19),那么 JM 会将这个状态文件 KeyGroupsStateHandle 分发给 subtask A 和 subtask B,让 subtask A 和 subtask B 都可以通过 KeyGroupsStateHandle 中的 stateHandle 读到状态文件,但是发给 subtask A 和 subtask B 的 KeyGroupRangeOffsets 完全不一样了。subtask A 收到的是 KeyGroupRange(10,14),offsets = 100,110,120,130,140;subtask B 收到的是 KeyGroupRange(15,19) offsets = 150,160,170,180,190。
当然 subtask A 负责的 KeyGroupRange 不是这么规整,可能新的 subtask A 对应的是 KeyGroupRange(8,14)。这样会存在:subtask A 恢复的 State 来自于旧任务的两个 subtask。所以 subtask A 会收到两个 KeyGroupsStateHandle。第一个 KeyGroupsStateHandle 负责的 KeyGroupRange(8,9),第二个 KeyGroupsStateHandle 负责的 KeyGroupRange(10,14)。
其实上述过程就是 Flink 任务修改并发的情况下,状态如何恢复,如果不理解上述过程源码是看不懂的,源码只是对原理的一种实现而已,看源码能帮助我们确认我们对知识的理解是否正确,也能吸取开源项目优秀的设计思想。
这里也再次证实了为什么 OperatorSubtaskState 必须把 StateHandle 封装成集合,因为一个新的 subtask 可能要恢复多个旧 subtask 的状态数据。
IncrementalRemoteKeyedStateHandle 介绍
IncrementalRemoteKeyedStateHandle 应用于 RocksDB 增量 Checkpoint 模式,所以在介绍 IncrementalRemoteKeyedStateHandle 中具体存储的数据之前,先来描述一下 RocksDB 增量 Checkpoint 的实现原理。(之前写过,这里直接粘过来)
RocksDB 增量 Checkpoint 实现原理
RocksDB 是一个基于 LSM 实现的 KV 数据库。LSM 全称 Log Structured Merge Trees,LSM 树本质是将大量的磁盘随机写操作转换成磁盘的批量写操作来极大地提升磁盘数据写入效率。一般 LSM Tree 实现上都会有一个基于内存的 MemTable 介质,所有的增删改操作都是写入到 MemTable 中,当 MemTable 足够大以后,将 MemTable 中的数据 flush 到磁盘中生成不可变且内部有序的 ssTable(Sorted String Table)文件,全量数据保存在磁盘的多个 ssTable 文件中。HBase 也是基于 LSM Tree 实现的,HBase 磁盘上的 HFile 就相当于这里的 ssTable 文件,每次生成的 HFile 都是不可变的而且内部有序的文件。基于 ssTable 不可变的特性,才实现了增量 Checkpoint,具体流程如下所示:
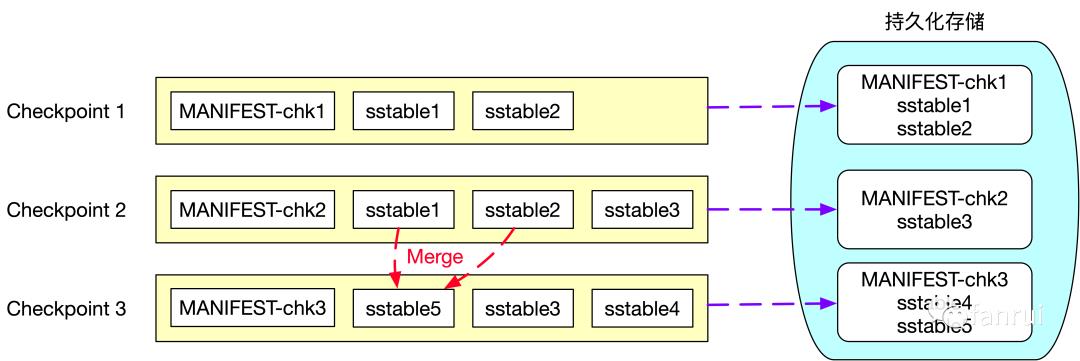
第一次 Checkpoint 时生成的状态快照信息包含了两个 sstable 文件:sstable1 和 sstable2 及 Checkpoint1 的元数据文件 MANIFEST-chk1,所以第一次 Checkpoint 时需要将 sstable1、sstable2 和 MANIFEST-chk1 上传到外部持久化存储中。第二次 Checkpoint 时生成的快照信息为 sstable1、sstable2、sstable3 及元数据文件 MANIFEST-chk2,由于 sstable 文件的不可变特性,所以状态快照信息的 sstable1、sstable2 这两个文件并没有发生变化,sstable1、sstable2 这两个文件不需要重复上传到外部持久化存储中,因此第二次 Checkpoint 时,只需要将 sstable3 和 MANIFEST-chk2 文件上传到外部持久化存储中即可。这里只将新增的文件上传到外部持久化存储,也就是所谓的增量 Checkpoint。
基于 LSM Tree 实现的数据库为了提高查询效率,都需要定期对磁盘上多个 sstable 文件进行合并操作,合并时会将已删除的、过期的以及旧版本的数据进行清理,从而降低 sstable 文件的总大小。图中可以看到第三次 Checkpoint 时生成的快照信息为sstable3、sstable4、sstable5 及元数据文件 MANIFEST-chk3, 其中新增了 sstable4 文件且 sstable1 和 sstable2 文件合并成 sstable5 文件,因此第三次 Checkpoint 时只需要向外部持久化存储上传 sstable4、sstable5 及元数据文件 MANIFEST-chk3。
基于 RocksDB 的增量 Checkpoint 从本质上来讲每次 Checkpoint 时只将本次 Checkpoint 新增的快照信息上传到外部的持久化存储中,依靠的是 LSM Tree 中 sstable 文件不可变的特性。
IncrementalRemoteKeyedStateHandle 元数据介绍
了解了基于 RocksDB 实现的增量 Checkpoint 原理,我们知道 Checkpoint 实际存储的是 RocksDB 数据库的 sst 文件和 RocksDB 数据库的元数据文件。所以 IncrementalRemoteKeyedStateHandle 的设计如下所示:
public class IncrementalRemoteKeyedStateHandle implements IncrementalKeyedStateHandle
// 每个 RocksDB 数据库的唯一 ID
private final UUID backendIdentifier;
// 这个 RocksDB 数据库负责的 KeyGroupRange
private final KeyGroupRange keyGroupRange;
private final long checkpointId;
// RocksDB 真正存储数据的 sst 文件
private final Map<StateHandleID, StreamStateHandle> sharedState;
// RocksDB 数据库的一些元数据
private final Map<StateHandleID, StreamStateHandle> privateState;
// 本次 Checkpoint 元数据的 StateHandle
private final StreamStateHandle metaStateHandle;
// StateHandleID 只是简单地对 sst 文件名做了封装
public class StateHandleID extends StringBasedID
private static final long serialVersionUID = 1L;
// keyString 为 sst 文件名
public StateHandleID(String keyString)
super(keyString);
注:StateHandleID 只是简单地对 sst 文件名做了封装,所以后续用到 StateHandleID 的地方就直接说 sst 文件名。
IncrementalRemoteKeyedStateHandle 包含了对应的 RocksDB 数据库的一个标识 ID,负责的 KeyGroupRange,本次 Checkpoint 的 ID,还有 RocksDB 的 sst 文件信息和 RocksDB 数据库的一些元数据。
其中 sharedState 是一个 Map,Map 的 key 是 sst 文件名,value 为 sst 的文件句柄。privateState 也是一个 map,Map 的 key 是 RocksDB 数据库元数据的文件名,value 为相对应的文件句柄。
用上面案例来讲,第二次 Checkpoint,即 Checkpoint Id 为 2,此时对应的 sst 为 1.sst、2.sst、3.sst,RocksDB 元数据文件为 MANIFEST-chk2。虽然第二次 Checkpoint 时只上传了一个 3.sst,但 sharedState 需要保存三个 sst 的信息,因为这三个 sst 都属于本次 Checkpoint 的一部分数据文件。
Increment 模式下,JM 该如何给各 subtask 分配 State?
如果不修改并发,每个新的 subtask 负责的 KeyGroupRange 与之前旧的 subtask 相同,所以 JM 直接把 Checkpoint 中保存的 IncrementalRemoteKeyedStateHandle 分配给新的给 subtask 即可。TM 端恢复时直接把本次 Checkpoint 对应的 sst 和 RocksDB 的元数据文件拉取到本地,整个 RocksDB 数据库就可以开始工作了。
修改并发的情况就比较复杂了,与 KeyGroupsStateHandle 模式有非常大的区别。还是用修改并行度的例子来分析:
假设旧任务并发为 2:
subtask a 负责 KeyGroupRange(0,9)
subtask b 负责 KeyGroupRange(10,19)
新任务并发为 3:
subtask A 负责 KeyGroupRange(0,6)
subtask B 负责 KeyGroupRange(7,13)
subtask C 负责 KeyGroupRange(14,19)
先分析一下新的 subtask A 和 subtask B 状态该如何恢复,subtask C 与 subtask A 恢复流程极其相似,读者可以自行分析。subtask A 负责的 KeyGroupRange(0,6),恢复时数据来源于 subtask a 负责 KeyGroupRange(0,9),但是可以拿着 StateHandle 只从 dfs 上读取 KeyGroupRange(0,6) 的数据吗?
不行,我们看到了 IncrementalRemoteKeyedStateHandle 维护的只是 RocksDB 的一份数据快照,维护了一堆 sst,实际上可能每个 sst 都有 KeyGroup 0~9 的数据,不能直接截断 sst 去拉取 KeyGroup 0~6 的部分。而且 sst 是 RocksDB 自己生成的,不是 Flink 序列化生成的。
而 KeyGroupsStateHandle 模式可以做到只拉取部分数据是因为 KeyGroupsStateHandle 模式下是按照 KeyGroup 为单位对数据进行存储的,元数据中存储了每个 KeyGroup 对应的 offset 值。
那 IncrementalRemoteKeyedStateHandle 模式该如何恢复呢?
对于新的 subtask A 虽然只负责 KeyGroup 0~6 的部分,但必须将 KeyGroup 0~9 的数据全拉取到 TM 本地,基于这些数据建立出一个 RocksDB 实例,读出自己想要的数据。
新的 subtask B 负责 KeyGroupRange(7,13),恢复时数据来源于旧 subtask a 负责 KeyGroupRange(0,9) 和旧 subtask b 负责 KeyGroupRange(10,19),所以需要将两个 subtask 对应的数据全部拉取到本地,建立两个 RocksDB 实例,读取自己想要的数据。
通过上述流程,其实发现了 JM 要做的就是:分析新的 subtask 与 Checkpoint 中保存的 StateHandle 负责的 KeyGroupRange 只要有重合,那么这个 StateHandle 就需要分配给新的 subtask。例如:新的 subtask B(7~13)与旧的 (0,9) 和 (10,19)两个 StateHandle 有重合,那么这两个 StateHandle 都要完整地分配给 subtask B。具体怎么读取数据,冗余数据的如何裁剪交给 TM 来做,在后续 TM 恢复状态部分详细介绍(备注:裁剪的逻辑非常有意思)。
以上就是 IncrementalRemoteKeyedStateHandle 模式下 JM 给 subtask 分配 StateHandle 的原理。
五、总结
本文开头介绍了 Flink 任务从 Checkpoint 处恢复流程概述,随后通过源码介绍了 Checkpoint 的元数据。最后从源码层分析了多种模式下:JM 该如何合理地给每个 subtask 分配 State,让 TM 去恢复。
下一篇文章将会介绍 JM 怎么拿到 Checkpoint 元数据,并依赖元数据给 subtask 分配 StateHandle 的详细过程。
基于 Apache Flink 的实时监控告警系统关于数据中台的深度思考与总结(干干货)日志收集Agent,阴暗潮湿的地底世界
2020 继续踏踏实实的做好自己

公众号(zhisheng)里回复 面经、ClickHouse、ES、Flink、 Spring、Java、Kafka、监控 等关键字可以查看更多关键字对应的文章。
点个赞+在看,少个 bug ????
以上是关于Flink 源码:Checkpoint 元数据详解的主要内容,如果未能解决你的问题,请参考以下文章