如何用socket构建一个简单的Web Server
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何用socket构建一个简单的Web Server相关的知识,希望对你有一定的参考价值。
背景现代社会网络应用随处可见,不管我们是在浏览网页、发送电子邮件还是在线游戏都离不开网络应用程序,网络编程正在变得越来越重要
目标
了解web server的核心思想,然后自己构建一个tiny web server,它可以为我们提供简单的静态网页
最终效果
完整的事例代码可以查看这里
如何运行
python3 index.py注意
我们假设你已经学习过Python的系统IO、网络编程、Http协议,如果对此不熟悉,可以点击这里的Python教程进行学习,可以点击这里的Http协议进行学习,事例基于Python 3.7.2编写。
TinyWeb实现
首先我们给出TinyWebServer的主结构
import socket
# 创建socket
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 绑定地址和端口
server.bind(("127.0.0.1", 3000))
server.listen(5)
while True:
# 等待客户端请求
client, addr = server.accept()
# 处理请求
process_request(client, addr)上面代码的核心逻辑是socket等待客户端请求,一旦接受到客户端请求就处理请求。
接下来我们主要工作就是实现process_request函数,我们都知道Http协议,Http请求主要包含4部分请求行、请求头、空行、请求体,于是我们可以抽象process_request的过程如下:
读取请求行--->读取请求头--->读取请求体--->处理请求--->关闭请求
具体的Python代码如下所示:
def process_request(client, addr):
try:
# 获取请求行
request_line = read_request_line(client)
# 获取请求头
request_headers = read_request_headers(client)
# 获取请求体
request_body = read_request_body(
client, request_headers[b"content-length"])
# 处理客户端请求
do_it(client, request_line, request_headers, request_body)
except BaseException as error:
# 错误处理
handle_error(client, error)
finally:
# 关闭客户端请求
client.close()为什么我们不用单独解析空行,因为空行是用来表示整个http请求头的结束,除此之外空行对我们来说没有什么作用,关于如何解析Http消息,首先我们先来看一下Http消息结构:
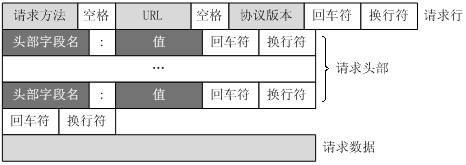
从上面的消息结构我们可以看出,要解析http消息,其中有一个关键的步骤是从socket中读取行,我们可以不断地从socket中读取直到遇到\r\n,这样我们就可以读取到完整的行
def read_line(socket):
recv_buffer = b‘‘
while True:
recv_buffer += recv(socket, 1)
if recv_buffer.endswith(b"\r\n"):
break
return recv_buffer上面的recv只是对socket.recv的一个包装,具体代码如下:
def recv(socket, count):
if count > 0:
recv_buffer = socket.recv(count)
if recv_buffer == b"":
raise TinyWebException("socket.rect调用失败!")
return recv_buffer
return b""在上面的封装中我们主要是处理了socket.recv返回错误和count小于0的异常情况,然后我们自己定义了一个TinyWebException用来表示我们的错误,TinyWebException的代码如下:
class TinyWebException(BaseException):
pass解析请求行:
请求行的解析从上面的结构中我们知道只要从请求数据中读取第一行,然后通过空格把他们分开就可以了,具体代码如下所示:
def read_request_line(socket):
"""
读取http请求行
"""
# 读取行并把\r\n替换成空字符,最后以空格分离
values = read_line(socket).replace(b"\r\n", b"").split(b" ")
return dict(
# 请求方法
b‘method‘: values[0],
# 请求路径
b‘path‘: values[1],
# 协议版本
b‘protocol‘: values[2]
)解析请求头:
请求头的解析要稍微复杂一点,它要不停得读取行,直到遇到单独的\r\n行结束,具体代码如下:
def read_request_headers(socket):
"""
读取http请求头
"""
headers = dict()
line = read_line(socket)
while line != b"\r\n":
keyValuePair = line.replace(b"\r\n", b"").split(b": ")
# 统一header中的可以为小写,方便后面使用
keyValuePair[0] = keyValuePair[0].decode(
encoding="utf-8").lower().encode("utf-8")
if keyValuePair[0] == b"content-length":
# 如果是cotent-length我们需要把结果转化为整数,方便后面读取body
headers[keyValuePair[0]] = bytesToInt(keyValuePair[1])
else:
headers[keyValuePair[0]] = keyValuePair[1]
line = read_line(socket)
# 如果heander中没有content-length,我们就手动把cotent-length设置为0
if not headers.__contains__(b"content-length"):
headers[b"content-length"] = 0
return headers解析请求体:
请求体的读取相对也简单,只要连续读取conetnt-length个bytes
def read_request_body(socket, content_length):
"""
读取http请求体
"""
return recv(socket, content_length)完成了Http数据解析以后我们需要实现核心的do_it,它主要是基于Http数据处理请求,我们在上面说过,tiny web server主要是实现了静态资源的读取,读取资源首先我们要定位资源,资源的定位主要是基于path的,在解析path的时候,我们用到了urllib.parse模块的urlparse功能,只要我们解析到了具体的资源,我们直接向浏览器输出响应就可以了。在输出具体的代码之前,我们需要简单说明一个Http消息响应的格式,HTTP响应也由四个部分组成,分别是:状态行、消息报头、空行和响应正文,下面给出一个简单的事例: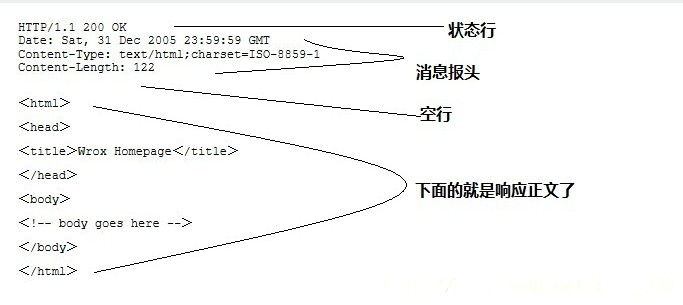
def do_it(socket, request_line, request_headers, request_body):
"""
处理http请求
"""
# 生成静态资源的目标地址,在这里我们所有的静态文件都统一放在static目录下面
parse_result = urlparse(request_line[b"path"])
current_dir = os.path.dirname(os.path.realpath(__file__))
file_path = os.path.join(current_dir, "static" +
parse_result.path.decode(encoding="utf-8"))
# 如果静态资源存在就向客户端提供静态文件
if os.path.exists(file_path):
serve_static(socket, file_path)
else:
# 静态文件不存在,向客户展示404页面
serve_static(socket, os.path.join(current_dir, "static/404.html"))do_it最核心的逻辑是serve_static,serve_static主要就是实现了读取静态文件并以Htt的响应格式返回给客户端,下面是serve_static的主要代码
def serve_static(socket, path):
# 检查是否有path读的权限和具体path对应的资源是否是文件
if os.access(path, os.R_OK) and os.path.isfile(path):
# 文件类型
content_type = static_type(path)
# 文件大小
content_length = os.stat(path).st_size
# 拼装Http响应
response_headers = b"HTTP/1.0 200 OK\r\n"
response_headers += b"Server: Tiny Web Server\r\n"
response_headers += b"Connection: close\r\n"
response_headers += b"Content-Type: " + content_type + b"\r\n"
response_headers += b"Content-Length: %d\r\n" % content_length
response_headers += b"\r\n"
# 发送http响应头
socket.send(response_headers)
# 以二进制的方式读取文件
with open(path, "rb") as f:
# 发送http消息体
socket.send(f.read())
else:
raise TinyWebException("没有访问权限")在serve_static中首先我们需要判断我们是否有文件的读全权,并且我们指定的资源是文件,而不是文件夹,如果不是合法文件我们直接提示没有访问权限,我们还需要直到文件的格式,因为客户端需要通过content-type来决定如何处理资源,然后我们需要文件大小,用来确定content-length,文件格式主要是通过后缀名简单判断,我们单独提供了static_type来生成content-type,文件的大小只要通过Python的os.stat获取就可以,最后我们只要把所有信息拼装成Http Response就可以了。
def static_type(path):
if path.endswith(".html"):
return b"text/html; charset=UTF-8"
elif path.endswith(".png"):
return b"image/png; charset=UTF-8"
elif path.endswith(".jpg"):
return b"image/jpg; charset=UTF-8"
elif path.endswith(".jpeg"):
return b"image/jpeg; charset=UTF-8"
elif path.endswith(".gif"):
return b"image/gif; charset=UTF-8"
elif path.endswith(".js"):
return b"application/javascript; charset=UTF-8"
elif path.endswith(".css"):
return b"text/css; charset=UTF-8"
else:
return b"text/plain; charset=UTF-8"完整的tiny web server 代码
#!/usr/bin/env python3
# -*- coding: UTF-8 -*-
import socket
from urllib.parse import urlparse
import os
class TinyWebException(BaseException):
pass
def recv(socket, count):
if count > 0:
recv_buffer = socket.recv(count)
if recv_buffer == b"":
raise TinyWebException("socket.rect调用失败!")
return recv_buffer
return b""
def read_line(socket):
recv_buffer = b‘‘
while True:
recv_buffer += recv(socket, 1)
if recv_buffer.endswith(b"\r\n"):
break
return recv_buffer
def read_request_line(socket):
"""
读取http请求行
"""
# 读取行并把\r\n替换成空字符,最后以空格分离
values = read_line(socket).replace(b"\r\n", b"").split(b" ")
return dict(
# 请求方法
b‘method‘: values[0],
# 请求路径
b‘path‘: values[1],
# 协议版本
b‘protocol‘: values[2]
)
def bytesToInt(bs):
"""
把bytes转化为int
"""
return int(bs.decode(encoding="utf-8"))
def read_request_headers(socket):
"""
读取http请求头
"""
headers = dict()
line = read_line(socket)
while line != b"\r\n":
keyValuePair = line.replace(b"\r\n", b"").split(b": ")
# 统一header中的可以为小写,方便后面使用
keyValuePair[0] = keyValuePair[0].decode(
encoding="utf-8").lower().encode("utf-8")
if keyValuePair[0] == b"content-length":
# 如果是cotent-length我们需要把结果转化为整数,方便后面读取body
headers[keyValuePair[0]] = bytesToInt(keyValuePair[1])
else:
headers[keyValuePair[0]] = keyValuePair[1]
line = read_line(socket)
# 如果heander中没有content-length,我们就手动把cotent-length设置为0
if not headers.__contains__(b"content-length"):
headers[b"content-length"] = 0
return headers
def read_request_body(socket, content_length):
"""
读取http请求体
"""
return recv(socket, content_length)
def send_response():
print("send response")
def static_type(path):
if path.endswith(".html"):
return b"text/html; charset=UTF-8"
elif path.endswith(".png"):
return b"image/png; charset=UTF-8"
elif path.endswith(".jpg"):
return b"image/jpg; charset=UTF-8"
elif path.endswith(".jpeg"):
return b"image/jpeg; charset=UTF-8"
elif path.endswith(".gif"):
return b"image/gif; charset=UTF-8"
elif path.endswith(".js"):
return b"application/javascript; charset=UTF-8"
elif path.endswith(".css"):
return b"text/css; charset=UTF-8"
else:
return b"text/plain; charset=UTF-8"
def serve_static(socket, path):
# 检查是否有path读的权限和具体path对应的资源是否是文件
if os.access(path, os.R_OK) and os.path.isfile(path):
# 文件类型
content_type = static_type(path)
# 文件大小
content_length = os.stat(path).st_size
# 拼装Http响应
response_headers = b"HTTP/1.0 200 OK\r\n"
response_headers += b"Server: Tiny Web Server\r\n"
response_headers += b"Connection: close\r\n"
response_headers += b"Content-Type: " + content_type + b"\r\n"
response_headers += b"Content-Length: %d\r\n" % content_length
response_headers += b"\r\n"
# 发送http响应头
socket.send(response_headers)
# 以二进制的方式读取文件
with open(path, "rb") as f:
# 发送http消息体
socket.send(f.read())
else:
raise TinyWebException("没有访问权限")
def do_it(socket, request_line, request_headers, request_body):
"""
处理http请求
"""
# 生成静态资源的目标地址,在这里我们所有的静态文件都统一放在static目录下面
parse_result = urlparse(request_line[b"path"])
current_dir = os.path.dirname(os.path.realpath(__file__))
file_path = os.path.join(current_dir, "static" +
parse_result.path.decode(encoding="utf-8"))
# 如果静态资源存在就向客户端提供静态文件
if os.path.exists(file_path):
serve_static(socket, file_path)
else:
# 静态文件不存在,向客户展示404页面
serve_static(socket, os.path.join(current_dir, "static/404.html"))
def handle_error(socket, error):
print(error)
error_message = str(error).encode("utf-8")
response = b"HTTP/1.0 500 Server Internal Error\r\n"
response += b"Server: Tiny Web Server\r\n"
response += b"Connection: close\r\n"
response += b"Content-Type: text/html; charset=UTF-8\r\n"
response += b"Content-Length: %d\r\n" % len(error_message)
response += b"\r\n"
response += error_message
socket.send(response)
def process_request(client, addr):
try:
# 获取请求行
request_line = read_request_line(client)
# 获取请求头
request_headers = read_request_headers(client)
# 获取请求体
request_body = read_request_body(
client, request_headers[b"content-length"])
# 处理客户端请求
do_it(client, request_line, request_headers, request_body)
except BaseException as error:
# 打印错误信息
handle_error(client, error)
finally:
# 关闭客户端请求
client.close()
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server.bind(("127.0.0.1", 3000))
server.listen(5)
print("启动tiny web server,port = 3000")
while True:
client, addr = server.accept()
print("请求地址:%s" % str(addr))
# 处理请求
process_request(client, addr)
最后想说的
上面的tiny web server只是实现了很简单的功能,在实际的应用中比这复杂得多,这里只是体现了web server的核心思想
以上是关于如何用socket构建一个简单的Web Server的主要内容,如果未能解决你的问题,请参考以下文章