数据降维
Posted weijiazheng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据降维相关的知识,希望对你有一定的参考价值。
利用PCA主成分分析法对数据进行降维
原理 : 我们一般使用数据降维来降低模型的复杂度,把数据集从一个散点组成的面变成一条直线,也就是从二维变成了一维,这就是数据降维,而其中用到的方法就是主成分分析法(Principal Component Analysis ,PCA)
1.导入数据集并用StandardScaler进行数据预处理
############################# 通过数据预处理提高模型准确率 ####################################### #导入红酒数据集 from sklearn import datasets wine = datasets.load_wine() #导入数据预处理工具 from sklearn.preprocessing import StandardScaler #导入画图工具 import matplotlib.pyplot as plt #对红酒数据集进行预处理 scaler = StandardScaler() X = wine.data y = wine.target X_scaled = scaler.fit_transform(X) #打印处理后的数据集形态 print(X_scaled.shape)
(178, 13)
2.导入PCA模块并进行数据处理
#导入PCA from sklearn.decomposition import PCA #设置主成分数量为2,以便我们进行可视化 pca = PCA(n_components=2) pca.fit(X_scaled) X_pca = pca.transform(X_scaled) #打印主成分提取后的数据形态 print(X_pca.shape)
(178, 2)
3.用经过PCA处理的数据集进行可视化
#将三个分类中的主成分提取出来 X0 = X_pca[wine.target==0] X1 = X_pca[wine.target==1] X2 = X_pca[wine.target==2] #绘制散点图 plt.scatter(X0[:, 0],X0[:, 1],c=‘b‘,s=60,edgecolor=‘k‘) plt.scatter(X1[:, 0],X1[:, 1],c=‘g‘,s=60,edgecolor=‘k‘) plt.scatter(X2[:, 0],X2[:, 1],c=‘r‘,s=60,edgecolor=‘k‘) #设置图注 plt.legend(wine.target_names,loc=‘best‘) plt.xlabel(‘component 1‘) plt.ylabel(‘component 2‘) #显示图像 plt.show()
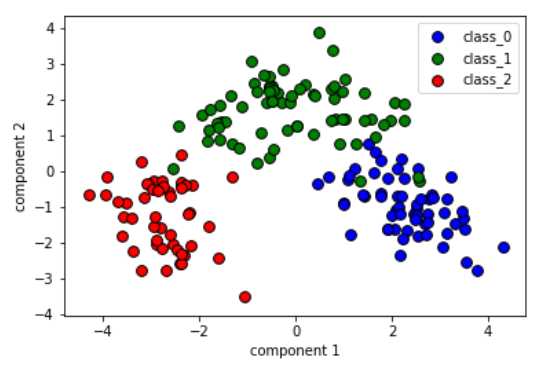
4.原始特征与PCA主成分之间的关系
#使用主成分绘制热度图 plt.matshow(pca.components_,cmap=‘plasma‘) #纵轴为主成分数 plt.yticks([0,1],[‘component 1‘,‘component 2‘]) plt.colorbar() #横轴为原始特征数量 plt.xticks(range(len(wine.feature_names)),wine.feature_names,rotation=60,ha=‘left‘) #显示图形 plt.show()
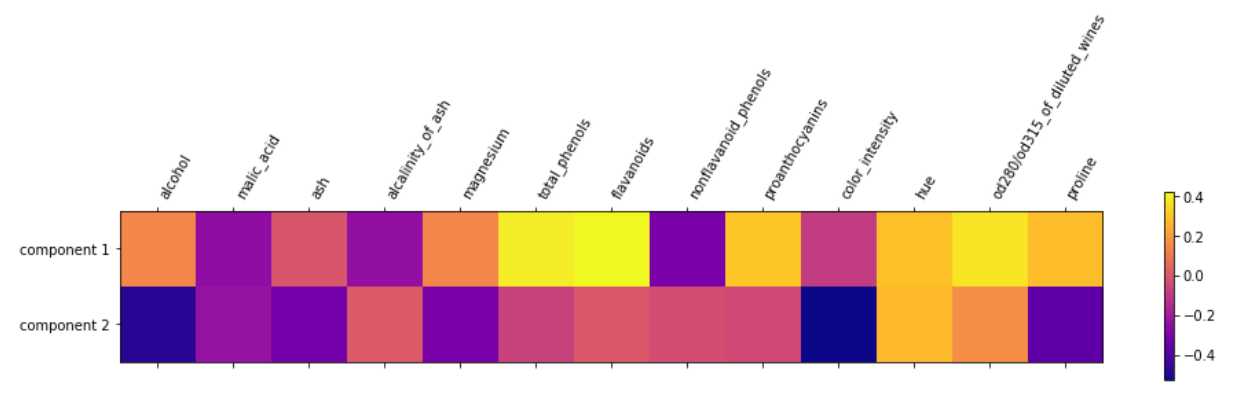
总结 :
经过降维后的两个主成分是如图的关系,颜色由深至浅代表一个-0.5~0.4的数值,而在两个主成分中,分别涉及了所有的13个特征,如果是正数则是正相关关系,如果是负数则是负相关关系.
在使用PCA过程中,我们会对PCA中的n_components进行设置,其含义不仅可以代表成分的个数,还可以设置降维之后保留信息的百分比.如:我们希望降维之后保留原始特征的90%的信息,则设置n_components为0.9
文章引自:《深入浅出python机器学习》
以上是关于数据降维的主要内容,如果未能解决你的问题,请参考以下文章
哈工大硕士生用Python实现了11种数据降维算法,代码已开源!