DeepID_V2解读
Posted jiangshaoyin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DeepID_V2解读相关的知识,希望对你有一定的参考价值。
港中文汤晓鸥团队在DeepID_v1基础上提出的新版本架构,发表于NIPS2014
一、Architecture
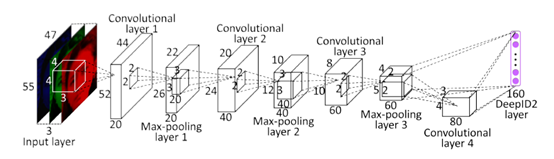
网络架构基本上与DeepId_v1一致。
二、Pipeline
图片被分成20regions,每个region有5scales,2RGB&Gray共10种模式,共生成200个pathes,进行水平翻转,分别送入200个网络中。
以1个55 * 47的RGB 模式patch为例,过程和DeepID_v1相似,最后生成1个160维的向量。
用前后向贪心算法,从400个DeepID中,筛选出25个有效且互补的DeepID2向量,缩减计算规模,得到160*25 = 4000的特征值。

再利用PCA对此向量进行降维,得到1* 180的向量,以此向量为依据,做cls和verif,cls用交叉熵,verif用join Bayesian。
三、相比于DeepID_V1的改动
网络结构没有多大改动,重点是在loss计算上。众所周知,表征人脸的特征最好能使不同的人脸之间的差异尽可能大,使相同人脸的不同照片人脸之间差异尽可能小。我们希望得到一个网路,这个网络计算出来的特征vector尽可能满足上述条件。设计loss函数如下:
(一)分类loss
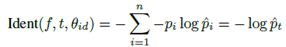
F是特征向量,θid是softmax层参数,t是label的分类结果。
(二)Verification loss
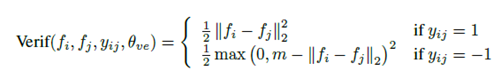
1.类内loss
当 ,input image和标签数据是同一个分类,此时训练网络,使之与label中的特征,尽可能的相近。
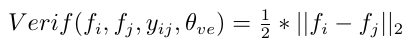
2.类间loss
当 ,input image和标签数据属于不同分类。
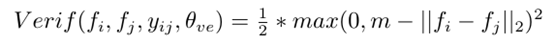
m为超参数,事先指定好。由上图知,当输入的图片的特征vector,和label的vector差异很大,其L2距离超过m时,loss值为0,网络倾向于学习,使类间距离尽可能的大的vector。
总Verification loss为类间loss和类内loss的加权和,权重各为0.5。
之前业界普遍采用的方法是L1/L2范式和余弦相似度,文中采用一种基于L2 Norm的损失函数。paper中作者测试了其他几种距离算法对准确率的影响,L2距离的性能最好。
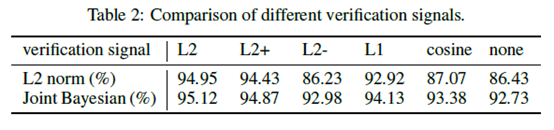
(三)cls和verif的组合
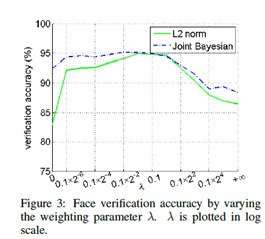
选取合适的λ,调整verif loss在总loss中的系数,当λ=0时,不计算verfi的loss,文中选取λ=0.5
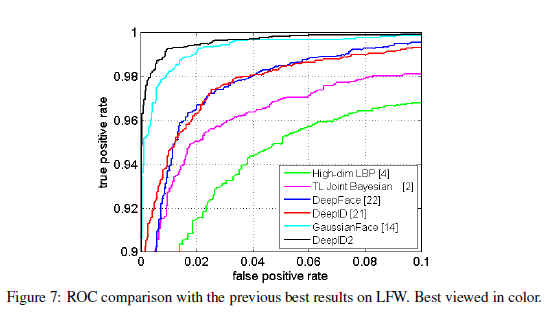
三、网络成绩
LFW共有5749个人的数据,共13233张脸。数据集太小,paper中引入外部数据集CelebFace+,有10177个人的数据,共202599张脸。
为充分利用从大量图像块中提取到的特征,作者重复使用7次前项后向贪婪算法选取特征,每次的选择是从之前的选择中未被留下的部分中进行选取。然后在每次选择的特征上,训练联合贝叶斯模型。再将这七个联合贝叶斯模型使用SVM进行融合,得到最佳的效果在LFW上为99.15%。
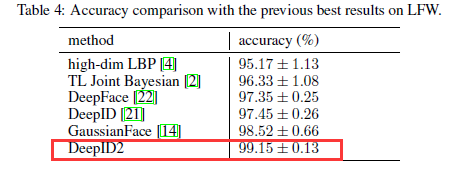
五、小结
DeeoID_V2印象最深的就是loss函数的创新,之前听师兄说发paper的3点分别是数据集,网络架构和loss函数,这次又验证了这一个观点。
以上是关于DeepID_V2解读的主要内容,如果未能解决你的问题,请参考以下文章