Word2vec原理详细解读
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Word2vec原理详细解读相关的知识,希望对你有一定的参考价值。
参考技术A Softmax函数:哈夫曼树(Huffman Tree)
从图1可以看出Skip-gram就是用当前中心词 (banking)预测附近的词,图1中将窗口大小设为2,即需要预测左边的2个词和右边的2个词。
对于每个位置 ,预测窗口大小为 的上下文,设当前中心词为 ,那么目标为最大化:
(1)
其中 为模型的参数。
为了将最大化转为最小化,可对 取负数,为了简化计算,可取对数:
(2)
现在问题的关键是如何计算 ,我们使用两个向量表示: 为中心词的表示, 为上下文词的表示。那么,计算中心词 c 和上下文词 o 的出现概率为:
(3)
其中,V为整个词表大小, 为中心词向量表示。其实式3就是softmax函数。
图2展示了Skip-gram的计算过程,从图中可以看出Skip-gram预测的是 , , ,由于只预测前后两个单词,因此窗口大小为2。
输入层到隐藏层 :输入层的中心词 用one-hot向量表示(维度为V*1,V为整个词表大小),输入层到隐藏层的权重矩阵为中心词矩阵W(维度为V*d,d为词向量维度),设隐含向量为 (维度为d*1),那么:
(4)
隐藏层到输出层: 隐藏层到输出层的上下文权重矩阵为U(维度为d*V),输出层为y(维度为V*1),那么:
(5)
注意 ,输出层的向量 y 与输出层的向量 虽然维度一样,但是 y 并不是one-hot向量,并且向量 y 的每一个元素都是有意义的。如,假设训练样本只有一句话”I like to eat apple”,此时我们正在使用eat去预测to,输出层结果如图3所示。
向量y中的每个元素表示用 I、like、eat、apple 四个词预测出来的词是对应的词的概率,比如是like的概率为0.05,是to的概率是0.80。由于我们想让模型预测出来的词是to,那么我们就要尽量让to的概率尽可能的大,所以我们将式子(1)作为最大化函数。
Continuous Bag-of-Words(CBOW),的计算示意图如图4所示。从图中可以看出,CBOW模型预测的是 ,由于目标词 只取前后的两个词,因此窗口大小为2。假设目标词 前后各取 个词,即窗口大小为 ,那么CBOW模型为:
(6)
输入层到隐藏层: 如图4所示,输入层为4个词的one-hot向量表示,分别为 , , , (维度都为V*1,V为整个词表大小),记输入层到隐藏层的上下文词的权重矩阵为W(维度为V*d,d是词向量维度),隐藏层的向量h(维度为d*1),那么:
(7)
这里就是把各个上下文词的向量查找出来,再进行简单的加和平均。
隐藏层到输出层: 记隐藏层到输出层的中心词权重矩阵为U(维度d*V),输出层的向量y(维度V*1),那么:
(8)
注意 ,输出层的向量 与输入层的 虽然维度一样,但是 并不是one-hot向量,并且向量 的每个元素都是有意义的。CBOW的目标是最大化函数:
(9)
由于softmax的分母部分计算代价很大,在实际应用时,一般采用层次softmax或者负采样替换掉输出层,降低计算复杂度。
层次softmax(Hierarchical Softmax)是一棵哈夫曼树,树的叶子节点是训练文本中所有的词,非叶子节点是一个逻辑回归二分类器,每个逻辑回归分类器的参数都不同,分别用 表示,假定分类器的输入为向量h,记逻辑回归分类器输出的结果为 将向量h传递给节点的左孩子概率为 ,否则传递给节点的右孩子概率为 。重复这个传递流程直到叶子节点。
从图5和图6可以看出,我们就是将隐藏层的向量h直接传递到了层次softmax,层次softmax的复杂度为O(log(V)),层次softmax采样到每个词的概率如下:
对于CBOW或者skip-gram模型,如果要预测的词是to,那么我们就让 尽量大,所以我们将任务转换成训练V-1个逻辑分类器。CBOW模型和skip-gram模型训练目标函数和之前形式一样,为:
(10)
(11)
负采样实际上是采样负例来帮助训练的手段,其目的与层次softmax一样,是用来提升模型的训练速度。我们知道,模型对正例的预测概率是越大越好,模型对负例的预测概率是越小越好。负采样的思路就是根据某种负采样的策略随机挑选一些负例,然后保证挑选的这部分负例的预测概率尽可能小。所以,负采样策略是对模型的效果影响很大,word2vec常用的负采样策略有均匀负采样、按词频率采样等等。
以“I like to eat apple”为例子,假设窗口的大小是2,当中心词为like时,即我们会用 I to 来预测like,所以在这里我们就认为(I,like)和(to,like)都是正例,而(I,apple)、(to,apple)就是负例,因为(I,apple)、(to,apple)不出现在当前正例中。用NEG(w)表示负样本,有:
(12)
(13)
这里的 是词*的中心词向量表示,h为隐藏层的输出向量。我们只需要最大化目标函数:
(14)
这个损失函数的含义就是让正例概率更大,负例的概率更小。
以“I like to eat apple”为例子,假设窗口的大小是1,即我们会用 like 来预测 I to,所以在这里我们就认为(like,I)和(like,to)都是正例,而(like,apple)就是负例,因为(like,apple)不会出现在正例中。那么,对于给定的正样本(w,context(w))和采样出的负样本(w,NEG(w)),有:
(15)
(16)
这里的 是词*的中心词向量表示,h为隐藏层的输出向量。我们只需要最大化目标函数:
(17)
word2vec常用的负采样策略有均匀负采样、按词频率采样等等。比较常用的采样方法是一元分布模型的3/4次幂。该方法中,一个词被采样的概率,取决于这个词在语料中的词频 ,其满足一元分布模型(Unigram Model).
(18)
其中V为整个词表大小, 为词 的词频。
至于为什么选择3/4呢?其实是由论文作者的经验所决定的。
假设由三个词,,”我“,”和平“,”觊觎“ 权重分别为 0.9 ,0.01,0.003;经过3/4幂后:
我: 0.9^3/4 = 0.92
和平:0.01^3/4 = 0.03
觊觎:0.003^3/4 = 0.012
对于”觊觎“而言,权重增加了4倍;”和平“增加3倍;”我“只有轻微增加。
可以认为:在保证高频词容易被抽到的大方向下,通过权重3/4次幂的方式, 适当提升低频词、罕见词被抽到的概率 。如果不这么做,低频词,罕见词很难被抽到,以至于不被更新到对应的Embedding。
Question&Answer
Question1: 如图7中,skip-gram模型中,从隐藏层到输出层,因为使用权值共享,所以会导致输出的几个上下文词向量总是完全一样,但网络的目的是要去预测上下文会出现的词,而实际中给定中心词的情况下上下文的词会五花八门。怎么解释skip gram的这种输出形式?
Answer1: 网络的目的不是要预测上下文会出现啥词,这只是一个fake task。实际上这个loss就是降不下来的,所以本来就不能用于真正预测上下文,而初衷也不是用于预测上下文,只是利用上下文信息去实现嵌入。
如果你的100W个句子都是”I really love machine learning and deep learning“,加上权值共享,结果就是给定machine以后,它输出really,love,learning,and这四个词的概率完全相同,这就意味着这四个词的词向量也是差不多的。正因为这样,语义相近的词,他们在空间上的映射才会接近。
Question2 : Word2Vec哪个矩阵是词向量?
Answer2: 如图7所示,中心词矩阵W,上下文矩阵W' 可以任意选一个作为词向量矩阵。但是,如果采用优化后(层次softmax)的模型,那么将不存在W',这种情况下只能选矩阵W。
三千多字,码字不易,如果大家发现我有地方写得不对或者有疑问的,麻烦评论, 我会回复并改正 。对于重要问题,我会持续更新至 Question&Answer。
参考:
[1] skip-gram的关键术语与详细解释
[2] 一篇浅显易懂的word2vec原理讲解
[3] CS224n:深度学习的自然语言处理(2017年冬季)1080p
[4] Stanford CS224N: NLP with Deep Learning | Winter 2019 | Lecture 2 – Word Vectors and
Word Senses
[5] 关于skip gram的输出?
[6] Le, Quoc V , and T. Mikolov . "Distributed Representationsof Sentences and Documents." (2014).
[7] Mikolov, T. . "Distributed Representations of Words andPhrases and their Compositionality." Advances in Neural InformationProcessing Systems 26(2013):3111-3119.
[8] Mikolov, Tomas , et al."Efficient Estimation of Word Representations in Vector Space." Computerence (2013).
[9] Goldberg, Yoav , and O. Levy . "word2vec Explained:deriving Mikolov et al.'s negative-sampling word-embedding method." arXiv(2014).
TS 原理详细解读绑定1-符号
在上一节主要介绍了语法树的解析生成。就好比电脑已经听到了“你真聪明”这句话,现在要让电脑开始思考这句话的含义——是真聪明还是假聪明。
这是一个非常的复杂的过程,接下来将有连续几节内容介绍实现原理,本节则主要提前介绍一些相关的概念。
符号
在代码里面,可以定义一个变量、一个函数、或者一个类,这些定义都有一个名字,然后在其它地方可以通过名字引用这个定义。
这些定义统称为符号(Symbol)(注意和 ES6 里的 Symbol 不相干)。
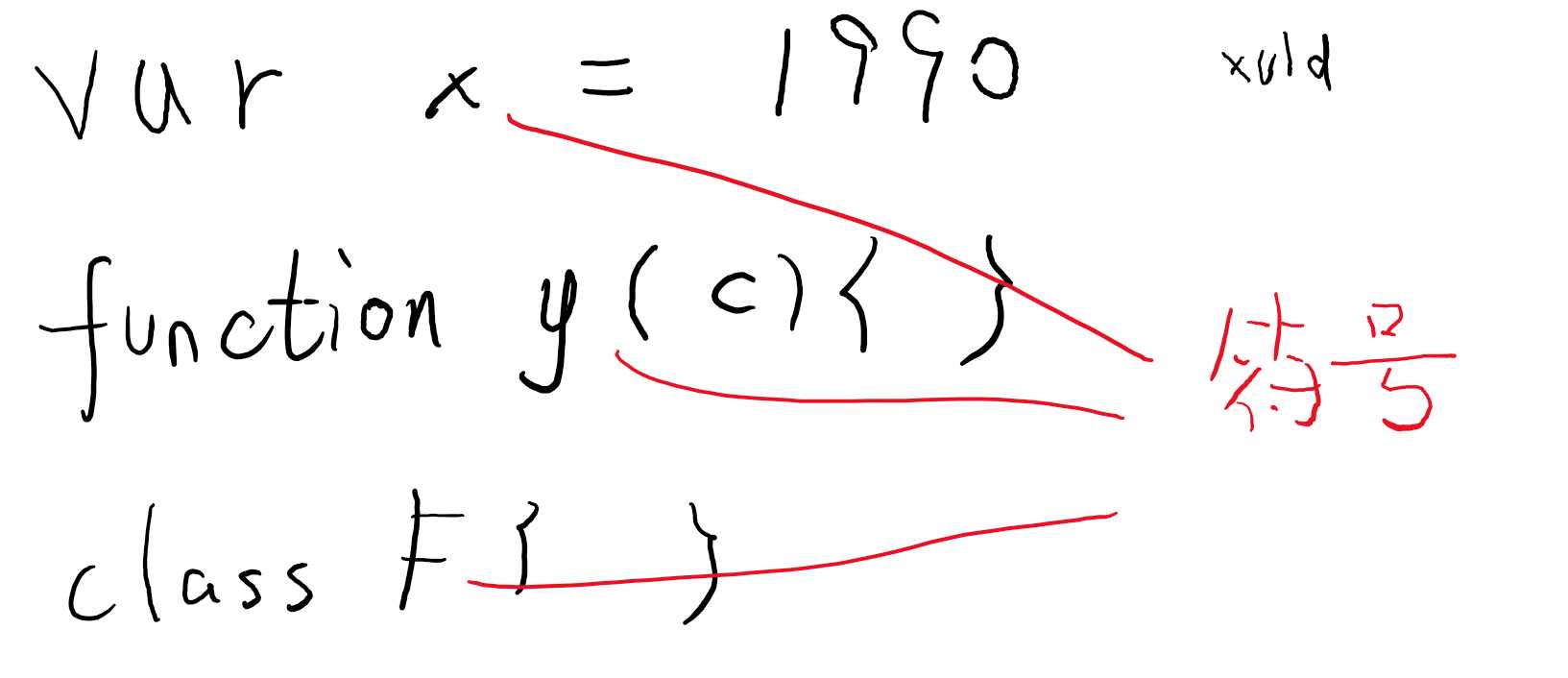
当在代码里写了一个标识符名称(变量名),这个名称一定可以解析为某个符号(可能是变量、参数、函数或其它的,可能是用户自己写的,也可能系统自带),如果无法解析,那一定是一个错误。
一个符号一般和一个声明节点对应,比如一个变量符号就对应一个 var 声明节点或 let/const 声明节点。
可能存在一个符号对应多个声明节点的情况,比如:
class A{}
interface A{}
同名的类和接口只产生一个符号 A,但这个符号拥有两个声明。
可能存在一个符号没有源声明节点的情况,比如:
type T = {[key: string]: any}
T 有无限个成员,每个成员都是没有源声明节点的。
TS 中符号的定义:
export interface Symbol { flags: SymbolFlags; // Symbol flags escapedName: __String; // Name of symbol declarations: Declaration[]; // Declarations associated with this symbol valueDeclaration: Declaration; // First value declaration of the symbol members?: SymbolTable; // Class, interface or object literal instance members exports?: SymbolTable; // Module exports globalExports?: SymbolTable; // Conditional global UMD exports /* @internal */ id?: number; // Unique id (used to look up SymbolLinks) /* @internal */ mergeId?: number; // Merge id (used to look up merged symbol) /* @internal */ parent?: Symbol; // Parent symbol /* @internal */ exportSymbol?: Symbol; // Exported symbol associated with this symbol /* @internal */ nameType?: Type; // Type associated with a late-bound symbol /* @internal */ constEnumOnlyModule?: boolean; // True if module contains only const enums or other modules with only const enums /* @internal */ isReferenced?: SymbolFlags; // True if the symbol is referenced elsewhere. Keeps track of the meaning of a reference in case a symbol is both a type parameter and parameter. /* @internal */ isReplaceableByMethod?: boolean; // Can this Javascript class property be replaced by a method symbol? /* @internal */ isAssigned?: boolean; // True if the symbol is a parameter with assignments /* @internal */ assignmentDeclarationMembers?: Map<Declaration>; // detected late-bound assignment declarations associated with the symbol }
其中,declarations 表示关联的源节点。valueDeclaration 则表示第一个具有值的源节点。
注意两者都可能为 `undefined`,源码中之所以没将它们标上 `?`,主要是因为作者懒(不然代码需要经常判断空)。
其中,escapedName 表示符号的名称,名称本质是字符串,TS 在源码中有一些内部的特殊符号名称,这些名称都以“__”前缀,如果用户本身就定义了名字带__的,会被转义成其它名字,所以 TS 内部将转义后的名字标记成 __String 类型,运行期间它本质还是字符串,所以不影响性能。
作用域
允许定义符号的节点叫作用域(Scope),比如全局范围(源文件),函数,大括号。
在同一个作用域中,不能定义同名的符号。
作用域是一个树结构,查找变量时,先在就近的作用域查找,找不到就向外层查找。
如图共四个作用域:
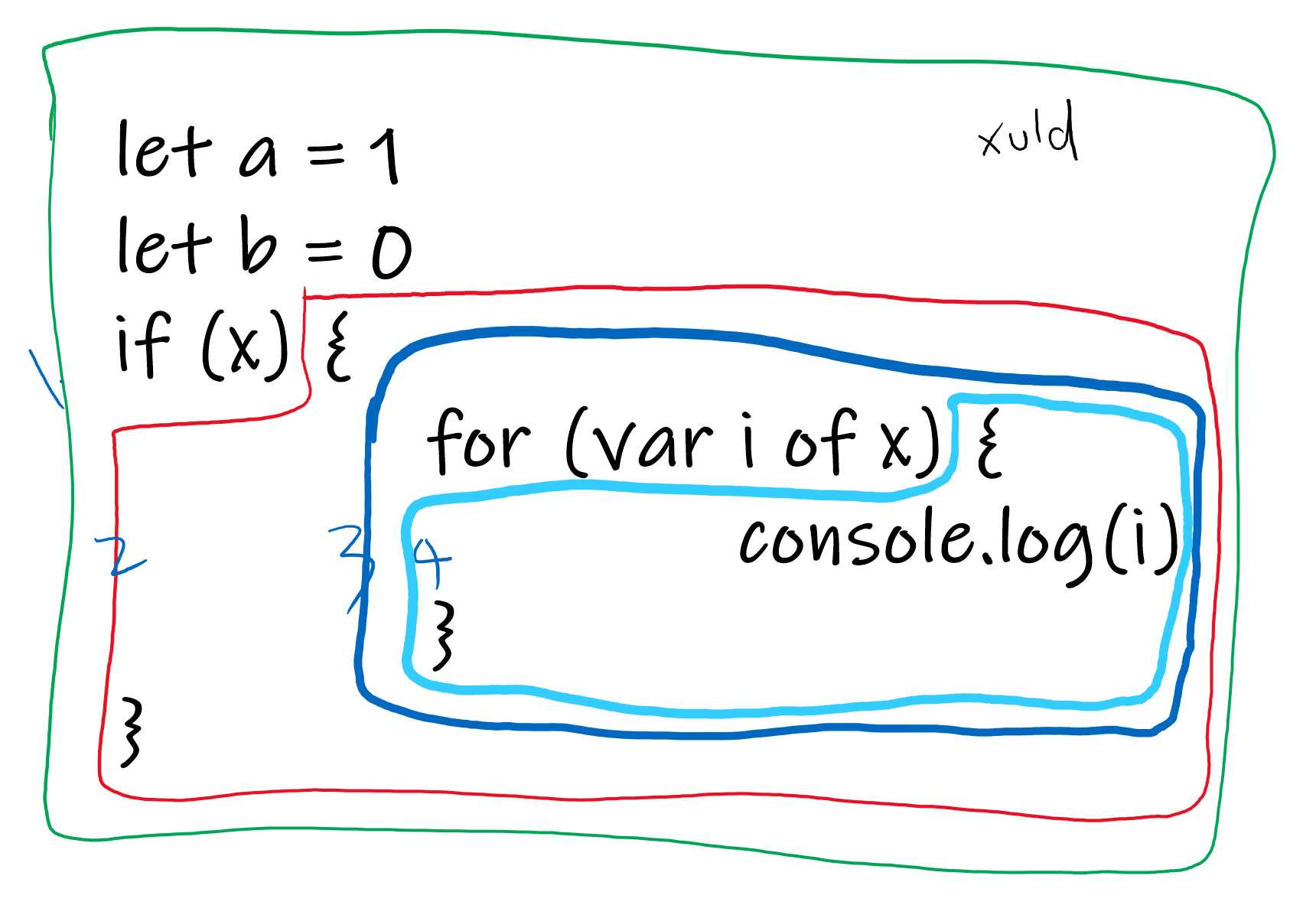
仔细观察会发现,if 语句不是一个作用域,但 for 语句却是。
语言本身就是这么设计的,因为在 for 里面可以声明变量。
流程节点
流程节点是执行流程图的组成部分。
比如 a = b > c && d == 3 ? e : f 的执行顺序:
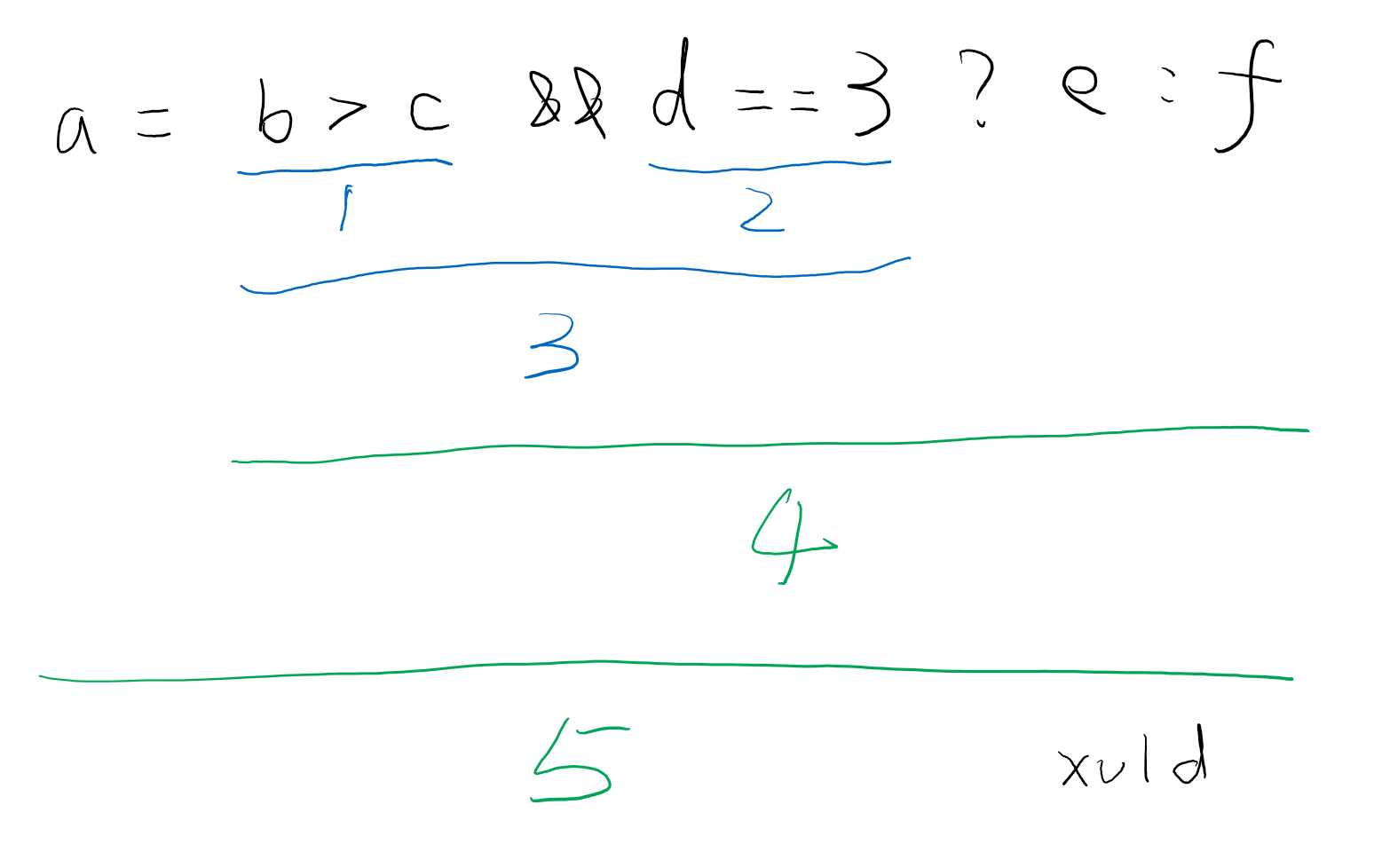
由于 JS 是动态语言,变量的类型可能随执行的流程发生变化,因此在分析时需要知道整个代码的执行顺序。
流程节点就是拥有记录这个顺序的对象。
开始流程
开始流程是整个流程图的根节点。
// FlowStart represents the start of a control flow. For a function expression or arrow // function, the node property references the function (which in turn has a flowNode // property for the containing control flow). export interface FlowStart extends FlowNodeBase { node?: FunctionExpression | ArrowFunction | MethodDeclaration; }
代码总是从一个函数开始执行的,所以开始流程也会记录关联的函数声明。
标签流程
如果执行的时候出现判断,则可能从一个流程进入两个子流程,即流程跳转,跳转的目标叫标签流程:
// FlowLabel represents a junction with multiple possible preceding control flows. export interface FlowLabel extends FlowNodeBase { antecedents: FlowNode[] | undefined; }
缩小类型范围的流程
理论上,每行节点都可能对变量的类型有影响,比如上图例子中,e 所在的位置在流程上可以确认 d == 3。
那么 d == 3 就是一种缩小类型范围的流程,在这个流程节点后面,统一认为 d 就是 3。
TS 目前并不支持将所有的表达式都按缩小类型范围的流程处理,只支持特定的几种表达式,甚至有些表达式如果加了括号就不认识。
这主要是基于性能考虑,这样可以更少创建流程节点。
TS 目前支持的流程有:
// FlowAssignment represents a node that assigns a value to a narrowable reference, // i.e. an identifier or a dotted name that starts with an identifier or ‘this‘. export interface FlowAssignment extends FlowNodeBase { node: Expression | VariableDeclaration | BindingElement; antecedent: FlowNode; } export interface FlowCall extends FlowNodeBase { node: CallExpression; antecedent: FlowNode; } // FlowCondition represents a condition that is known to be true or false at the // node‘s location in the control flow. export interface FlowCondition extends FlowNodeBase { node: Expression; antecedent: FlowNode; } export interface FlowSwitchClause extends FlowNodeBase { switchStatement: SwitchStatement; clauseStart: number; // Start index of case/default clause range clauseEnd: number; // End index of case/default clause range antecedent: FlowNode; } // FlowArrayMutation represents a node potentially mutates an array, i.e. an // operation of the form ‘x.push(value)‘, ‘x.unshift(value)‘ or ‘x[n] = value‘. export interface FlowArrayMutation extends FlowNodeBase { node: CallExpression | BinaryExpression; antecedent: FlowNode; }
finally 流程
try finally 流程稍微有些麻烦。
try { // 1 // ...(其它代码)... // 2 } catch { // 3 // ...(其它代码)... // 4 } finally { // 5 } // 6
对于位置 5,其父流程是 1/2/3/4 (假设 try 中任何一行代码都可能报错)
对于位置 6,其父流程只能是 5,且此时的 5 的父流程只能是 2/4,
所以位置 6 的父流程节点是 finally 结束位置的节点 5,而节点 5 的父流程有两种可能:1/2/3/4 或只有 2/4
所以 TS 在 5 的前后插入了两个特殊的流程节点:StartFinally 和 EndFinally,
当遍历到 EndFinally 时,则给 StartFinally 加锁,说明此时需要的是 finally 之后的流程节点,否则说明需要的是 finally 本身的父节点
export interface AfterFinallyFlow extends FlowNodeBase, FlowLock {
antecedent: FlowNode;
}
export interface PreFinallyFlow extends FlowNodeBase {
antecedent: FlowNode;
lock: FlowLock;
}
综合
以上所有类型的流程节点,通过父节点的方式组成一个图
export type FlowNode =
| AfterFinallyFlow
| PreFinallyFlow
| FlowStart
| FlowLabel
| FlowAssignment
| FlowCall
| FlowCondition
| FlowSwitchClause
| FlowArrayMutation;
如果将流程节点可视化,将类似地铁图,每个节点就是一个站点,站点之间的线路存在分叉,也存在合并,也存在循环。
自测题
为了帮助验证到此为止的知识点是否都已掌握,这里准备了一些题目:
1. 解释以下术语:
- Token
- Node
- SyntaxKind
- Symbol
- Declaration
- TypeNode
- FlowNode
- Increamentable
- fullStart
- Trivial
2. 阐述编译器从源文件到符号的流程步骤
3. 猜测编译器在生成符号后的操作内容
以上是关于Word2vec原理详细解读的主要内容,如果未能解决你的问题,请参考以下文章