Tensorflow的安装和使用——Jetson Nano 初体验3
Posted albert-8
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Tensorflow的安装和使用——Jetson Nano 初体验3相关的知识,希望对你有一定的参考价值。
1.安装 Jupyter notebook 和 Jupyter Lab
notebook 是 Donald Knuth 在 1984 年提出的文字表达化编程的一种形式。在文字表达化编程中,直接在代码旁写出叙述性文档,而不是另外编写单独的文档。
1.1 安装pip3
Jetson Nano中已经安装了Python3.6版本
# 安装pip3
sudo apt-get install python3-pip python3-dev安装后pip是9.01版本,需要把它升级到最新版,升级后pip版本为19.1.1。
# 升级pip3
python3 -m pip install --upgrade pip
pip3 install --upgrade --user升级后会有一个小Bug,需要手动改一下
打开pip3文件
sudo vim /usr/bin/pip3 将原来的
from pip import main
if __name__ == '__main__':
sys.exit(main())改成
from pip import __main__
if __name__ == '__main__':
sys.exit(__main__._main())修改结束后保存。运行 pip3 -V 成功后显示
pip3 -V
pip 19.1.1 from /home/albert/.local/lib/python3.6/site-packages/pip (python 3.6)1.2 安装 Jupyter notebook
pip3 install jupyter notebook --user
Successfully installed Send2Trash-1.5.0 backcall-0.1.0 bleach-3.1.0 defusedxml-0.6.0 entrypoints-0.3 ipykernel-5.1.0 ipython-7.5.0 ipython-genutils-0.2.0 ipywidgets-7.4.2 jedi-0.13.3 jinja2-2.10.1 jsonschema-3.0.1 jupyter-1.0.0 jupyter-client-5.2.4 jupyter-console-6.0.0 jupyter-core-4.4.0 mistune-0.8.4 nbconvert-5.5.0 nbformat-4.4.0 notebook-5.7.8 pandocfilters-1.4.2 parso-0.4.0 pexpect-4.7.0 pickleshare-0.7.5 prometheus-client-0.6.0 prompt-toolkit-2.0.9 ptyprocess-0.6.0 pygments-2.3.1 pyrsistent-0.15.1 pyzmq-18.0.1 qtconsole-4.4.3 terminado-0.8.2 testpath-0.4.2 tornado-6.0.2 traitlets-4.3.2 wcwidth-0.1.7 widgetsnbextension-3.4.2jupyter --help
usage: jupyter [-h] [--version] [--config-dir] [--data-dir] [--runtime-dir]
[--paths] [--json]
[subcommand]
Jupyter: Interactive Computing
positional arguments:
subcommand the subcommand to launch
optional arguments:
-h, --help show this help message and exit
--version show the jupyter command's version and exit
--config-dir show Jupyter config dir
--data-dir show Jupyter data dir
--runtime-dir show Jupyter runtime dir
--paths show all Jupyter paths. Add --json for machine-readable
format.
--json output paths as machine-readable json
Available subcommands: bundlerextension console contrib kernel kernelspec
migrate nbconvert nbextension nbextensions_configurator notebook qtconsole run
serverextension troubleshoot trustjupyter notebook --help
The Jupyter html Notebook.
This launches a Tornado based HTML Notebook Server that serves up an
HTML5/javascript Notebook client.
Subcommands
-----------
Subcommands are launched as `jupyter-notebook cmd [args]`. For information on
using subcommand 'cmd', do: `jupyter-notebook cmd -h`.
list
List currently running notebook servers.
stop
Stop currently running notebook server for a given port
password
Set a password for the notebook server.
Options
-------
Arguments that take values are actually convenience aliases to full
Configurables, whose aliases are listed on the help line. For more information
on full configurables, see '--help-all'.
--debug
set log level to logging.DEBUG (maximize logging output)
--generate-config
generate default config file
-y
Answer yes to any questions instead of prompting.
--no-browser
Don't open the notebook in a browser after startup.
--pylab
DISABLED: use %pylab or %matplotlib in the notebook to enable matplotlib.
--no-mathjax
Disable MathJax
MathJax is the javascript library Jupyter uses to render math/LaTeX. It is
very large, so you may want to disable it if you have a slow internet
connection, or for offline use of the notebook.
When disabled, equations etc. will appear as their untransformed TeX source.
--allow-root
Allow the notebook to be run from root user.
--script
DEPRECATED, IGNORED
--no-script
DEPRECATED, IGNORED
--log-level=<Enum> (Application.log_level)
Default: 30
Choices: (0, 10, 20, 30, 40, 50, 'DEBUG', 'INFO', 'WARN', 'ERROR', 'CRITICAL')
Set the log level by value or name.
--config=<Unicode> (JupyterApp.config_file)
Default: ''
Full path of a config file.
--ip=<Unicode> (NotebookApp.ip)
Default: 'localhost'
The IP address the notebook server will listen on.
--port=<Int> (NotebookApp.port)
Default: 8888
The port the notebook server will listen on.
--port-retries=<Int> (NotebookApp.port_retries)
Default: 50
The number of additional ports to try if the specified port is not
available.
--transport=<CaselessStrEnum> (KernelManager.transport)
Default: 'tcp'
Choices: ['tcp', 'ipc']
--keyfile=<Unicode> (NotebookApp.keyfile)
Default: ''
The full path to a private key file for usage with SSL/TLS.
--certfile=<Unicode> (NotebookApp.certfile)
Default: ''
The full path to an SSL/TLS certificate file.
--client-ca=<Unicode> (NotebookApp.client_ca)
Default: ''
The full path to a certificate authority certificate for SSL/TLS client
authentication.
--notebook-dir=<Unicode> (NotebookApp.notebook_dir)
Default: ''
The directory to use for notebooks and kernels.
--browser=<Unicode> (NotebookApp.browser)
Default: ''
Specify what command to use to invoke a web browser when opening the
notebook. If not specified, the default browser will be determined by the
`webbrowser` standard library module, which allows setting of the BROWSER
environment variable to override it.
--pylab=<Unicode> (NotebookApp.pylab)
Default: 'disabled'
DISABLED: use %pylab or %matplotlib in the notebook to enable matplotlib.
To see all available configurables, use `--help-all`
Examples
--------
jupyter notebook # start the notebook
jupyter notebook --certfile=mycert.pem # use SSL/TLS certificate
jupyter notebook password # enter a password to protect the server安装扩展
pip3 install tqdm jupyter_contrib_nbextensions --user
#安装关联的 JavaScript 和 CSS 文件:
jupyter contrib nbextension install --user
# 安装主题,安装完成后,我们将会有一个jt的命令。
pip3 install --upgrade jupyterthemes --user
# jt 的 help ,之后可以自行配置主题
jt --help1.3 启动 notebook 服务器并配置远程访问
1.3.1 配置Jupyter
生成配置文件
jupyter notebook --generate-config生成密码
ipython
from notebook.auth import passwd
passwd()设定一个密码,会生成一个sha1的秘钥
Out[2]: 'sha1:0fb67bb71f8f:9525f730807d01c04ea963492b0e3340de7b9d67'修改默认配置文件
vim ~/.jupyter/jupyter_notebook_config.pyjupyter_notebook_config.py 文件全是注释,所以直接在第一行前插入以下内容:
c.NotebookApp.ip='*' # 就是设置所有ip皆可访问
c.NotebookApp.password = u'sha1:0fb67bb71f8f:9525f730807d01c04ea963492b0e3340de7b9d67' #刚才复制的那个sha1密文
c.NotebookApp.open_browser = False # 禁止自动打开浏览器
c.NotebookApp.port = 8888 #指定为NAT端口映射的端口号个人建议:屏蔽掉密码那一行,如果不是服务器安装,而只是自己的Jetson Nano 或虚拟机,自己用不需要安全设置
1.3.2 启动 notebook
在终端或控制台中输入
jupyter notebook --ip=192.168.1.115服务器会在你运行此命令的目录中启动。
http://192.168.1.115:8888/?token=d2e1e7e1e6e59f20725237958ade0c1f9f24b3a31cfaec5f1.3.3 关闭 Jupyter
关闭running的notebook
通过在服务器主页上选中 notebook 旁边的复选框,然后点击“Shutdown”(关闭),你就可以关闭各个 notebook。但是,在这样做之前,请确保你保存了工作!否则,在你上次保存后所做的任何更改都会丢失。下次运行 notebook 时,你还需要重新运行代码。
关闭整个服务器
通过在终端中按两次 Ctrl + C,可以关闭整个服务器。再次提醒,这会立即关闭所有运行中的 notebook,因此,请确保你保存了工作!
1.3.4 保存Notebook
工具栏包含了保存按钮,但 notebook 也会定期自动保存。标题右侧会注明最近一次的保存。你可以使用保存按钮手动进行保存,也可以按键盘上的 Esc,然后按 s。按 Esc 键会变为命令模式,而 s 是“保存”的快捷键。
1.4 Notebook用法
1.4.1 Markdown单元格
像代码单元格一样,按 Shift + Enter 或 Ctrl + Enter 可运行 Markdown 单元格,这会将 Markdown 呈现为格式化文本。加入文本可让你直接在代码旁写出叙述性文档,以及为代码和思路编写文档。
1.4.2 Magic关键词
Magic-What?
- 1.Magic 关键字是可以在单元格中运行的特殊命令,能让你控制 notebook 本身或执行系统调用(例如更改目录)。
- 2.Magic 命令的前面带有一个或两个百分号(% 或 %%),分别对应行 Magic 命令和单元格 Magic 命令。行 Magic 命令仅应用于编写 Magic 命令时所在的行,而单元格 Magic 命令应用于整个单元格。
注意:这些 Magic 关键字是特定于普通 Python 内核的关键字。如果使用其他内核,这些关键字很有可能无效。
Magic-How?
- 1.交互工作方式:画图前先运行如下命令,可以直接显示Matplotlib的图形
%matplotlib - 2.代码计时
有时候,你可能要花些精力优化代码,让代码运行得更快。在此优化过程中,必须对代码的运行速度进行计时。可以使用 Magic 命令timeit测算函数的运行时间。如果要测算整个单元格的运行时间,请使用%%timeit,也可以使用timeit包测量程序运行时间:
# calculate time using
import timeit
start = timeit.default_timer()
# runing program
# output time using
end = timeit.default_timer()
tdf = end -start
timeh = tdf // 3600
timem = (tdf % 3600) // 60
times = tdf % 60
print("The total cost time is : " , int(timeh) , "h" , int(timem) , "m" ,times, "s")- 3.在notebook 中嵌入可视化内容
- 4.在 notebook 中进行调试
对于 Python 内核,可以使用 Magic 命令 %pdb 开启交互式调试器。出错时,你能检查当前命名空间中的变量。
1.5 Jupyter Lab 安装
Jupyter源于Ipython Notebook,是使用Python(也有R、Julia、Node等其他语言的内核)进行代码演示、数据分析、可视化、教学的很好的工具,对Python的愈加流行和在AI领域的领导地位有很大的推动作用。
Jupyter Lab是Jupyter的一个拓展,提供了更好的用户体验,例如可以同时在一个浏览器页面打开编辑多个Notebook,Ipython console和terminal终端,并且支持预览和编辑更多种类的文件,如代码文件,Markdown文档,json,yml,csv,各种格式的图片,vega文件(一种使用json定义图表的语言)和geojson(用json表示地理对象),还可以使用Jupyter Lab连接Google Drive等云存储服务,极大得提升了生产力。
我们可以通过Try Jupyter网站(https://jupyter.org/try)试用Jupyter Lab
1.5.1 安装Jupyter Lab
pip3 install jupyterlab --user1.5.2 运行Jupyter Lab
jupyter-labJupyter Lab会继承Jupyter Notebook的配置(地址,端口,密码等)
jupyter-lab --help
JupyterLab - An extensible computational environment for Jupyter.
This launches a Tornado based HTML Server that serves up an HTML5/Javascript
JupyterLab client.
JupyterLab has three different modes of running:
* Core mode (`--core-mode`): in this mode JupyterLab will run using the JavaScript
assets contained in the installed `jupyterlab` Python package. In core mode, no
extensions are enabled. This is the default in a stable JupyterLab release if you
have no extensions installed.
* Dev mode (`--dev-mode`): uses the unpublished local JavaScript packages in the
`dev_mode` folder. In this case JupyterLab will show a red stripe at the top of
the page. It can only be used if JupyterLab is installed as `pip install -e .`.
* App mode: JupyterLab allows multiple JupyterLab "applications" to be
created by the user with different combinations of extensions. The `--app-dir` can
be used to set a directory for different applications. The default application
path can be found using `jupyter lab path`.
Subcommands
-----------
Subcommands are launched as `jupyter-notebook cmd [args]`. For information on
using subcommand 'cmd', do: `jupyter-notebook cmd -h`.
build
clean
path
paths
workspace
workspaces
Options
-------
Arguments that take values are actually convenience aliases to full
Configurables, whose aliases are listed on the help line. For more information
on full configurables, see '--help-all'.
--debug
set log level to logging.DEBUG (maximize logging output)
--generate-config
generate default config file
-y
Answer yes to any questions instead of prompting.
--no-browser
Don't open the notebook in a browser after startup.
--pylab
DISABLED: use %pylab or %matplotlib in the notebook to enable matplotlib.
--no-mathjax
Disable MathJax
MathJax is the javascript library Jupyter uses to render math/LaTeX. It is
very large, so you may want to disable it if you have a slow internet
connection, or for offline use of the notebook.
When disabled, equations etc. will appear as their untransformed TeX source.
--allow-root
Allow the notebook to be run from root user.
--script
DEPRECATED, IGNORED
--no-script
DEPRECATED, IGNORED
--core-mode
Start the app in core mode.
--dev-mode
Start the app in dev mode for running from source.
--watch
Start the app in watch mode.
--log-level=<Enum> (Application.log_level)
Default: 30
Choices: (0, 10, 20, 30, 40, 50, 'DEBUG', 'INFO', 'WARN', 'ERROR', 'CRITICAL')
Set the log level by value or name.
--config=<Unicode> (JupyterApp.config_file)
Default: ''
Full path of a config file.
--ip=<Unicode> (NotebookApp.ip)
Default: 'localhost'
The IP address the notebook server will listen on.
--port=<Int> (NotebookApp.port)
Default: 8888
The port the notebook server will listen on.
--port-retries=<Int> (NotebookApp.port_retries)
Default: 50
The number of additional ports to try if the specified port is not
available.
--transport=<CaselessStrEnum> (KernelManager.transport)
Default: 'tcp'
Choices: ['tcp', 'ipc']
--keyfile=<Unicode> (NotebookApp.keyfile)
Default: ''
The full path to a private key file for usage with SSL/TLS.
--certfile=<Unicode> (NotebookApp.certfile)
Default: ''
The full path to an SSL/TLS certificate file.
--client-ca=<Unicode> (NotebookApp.client_ca)
Default: ''
The full path to a certificate authority certificate for SSL/TLS client
authentication.
--notebook-dir=<Unicode> (NotebookApp.notebook_dir)
Default: ''
The directory to use for notebooks and kernels.
--browser=<Unicode> (NotebookApp.browser)
Default: ''
Specify what command to use to invoke a web browser when opening the
notebook. If not specified, the default browser will be determined by the
`webbrowser` standard library module, which allows setting of the BROWSER
environment variable to override it.
--pylab=<Unicode> (NotebookApp.pylab)
Default: 'disabled'
DISABLED: use %pylab or %matplotlib in the notebook to enable matplotlib.
--app-dir=<Unicode> (LabApp.app_dir)
Default: '/home/albert/.local/share/jupyter/lab'
The app directory to launch JupyterLab from.
To see all available configurables, use `--help-all`
Examples
--------
jupyter lab # start JupyterLab
jupyter lab --dev-mode # start JupyterLab in development mode, with no extensions
jupyter lab --core-mode # start JupyterLab in core mode, with no extensions
jupyter lab --app-dir=~/myjupyterlabapp # start JupyterLab with a particular set of extensions
jupyter lab --certfile=mycert.pem # use SSL/TLS certificate
1.5.3 访问Jupyter Lab
浏览器访问 http://localhost:8888
2.安装TensorFlow GPU
2.1 安装机器学习依赖包
# numpy scipy pandas matplotlib sklearn
sudo apt install python3-numpy python3-scipy python3-pandas python3-matplotlib python3-sklearn libhdf5-serial-dev hdf5-tools2.2 安装TensorFlow GPU版并加入环境变量
#安装TensorFlow GPU版本
pip3 install --extra-index-url https://developer.download.nvidia.com/compute/redist/jp/v42 tensorflow-gpu==1.13.1+nv19.3 --user然后是漫长的安装过程
Successfully installed absl-py-0.7.1 astor-0.7.1 gast-0.2.2 grpcio-1.20.1 h5py-2.9.0 keras-applications-1.0.7 keras-preprocessing-1.0.9 markdown-3.1 mock-2.0.0 pbr-5.2.0 protobuf-3.7.1 tensorboard-1.13.1 tensorflow-estimator-1.13.0 tensorflow-gpu-1.13.1+nv19.3 termcolor-1.1.0 werkzeug-0.15.2由于安装时使用了 --user 参数,即
pip3 install --user package_name这样会将Python3 程序包安装到 $HOME/.local 路径下,其中包含三个子文件夹:bin,lib 和 share。
需要修改 .bash_profile 文件使得 $HOME/.local/bin 目录下的程序加入到环境变量中
sudo vim ~/.bashrc在最后添加
export PATH=$HOME/.local/bin:$PATH对了最后别忘了source一下这个文件。
source ~/.bashrc2.3 测试TensorFlow
查看 TensorFlow 版本,可知当前版本为1.13.1
python3
Python 3.6.7 (default, Oct 22 2018, 11:32:17)
[GCC 8.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import tensorflow as tf
>>> tf.__version__
'1.13.1'2.3.1 线性回归例程测试:
%matplotlib inline
# 图片内联且以矢量格式显示
# %config InlineBackend.figure_format = 'svg'
# 计算运行时间
# calculate time using
import timeit
start = timeit.default_timer()
import tensorflow as tf
import numpy
import matplotlib.pyplot as plt
rng = numpy.random
learning_rate = 0.01
training_epochs = 1000
display_step = 50
#数据集x
train_X = numpy.asarray([3.3,4.4,5.5,7.997,5.654,.71,6.93,4.168,9.779,6.182,7.59,2.167,
7.042,10.791,5.313,9.27,3.1])
#数据集y
train_Y = numpy.asarray([1.7,2.76,3.366,2.596,2.53,1.221,1.694,1.573,3.465,1.65,2.09,
2.827,3.19,2.904,2.42,2.94,1.3])
n_samples = train_X.shape[0]
X = tf.placeholder("float")
Y = tf.placeholder("float")
W = tf.Variable(rng.randn(), name="weight")
b = tf.Variable(rng.randn(), name="bias")
pred = tf.add(tf.multiply(X, W), b)
cost = tf.reduce_sum(tf.pow(pred-Y, 2))/(2*n_samples)
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost)
init = tf.initialize_all_variables()
with tf.Session() as sess:
sess.run(init)
# 训练数据
for epoch in range(training_epochs):
for (x, y) in zip(train_X, train_Y):
sess.run(optimizer, feed_dict={X: x, Y: y})
print ("优化完成!")
training_cost = sess.run(cost, feed_dict={X: train_X, Y: train_Y})
print ("Training cost=", training_cost, "W=", sess.run(W), "b=", sess.run(b),)
#可视化显示
plt.plot(train_X, train_Y, 'ro', label='Original data')
plt.plot(train_X, sess.run(W) * train_X + sess.run(b), label='Fitted line')
plt.legend()
plt.show()
# output time using
end = timeit.default_timer()
tdf = end -start
timeh = tdf // 3600
timem = (tdf % 3600) // 60
times = tdf % 60
print("The total cost time is : " , int(timeh) , "h" , int(timem) , "m" ,times, "s")结果:
优化完成!
Training cost= 0.17327271 W= 0.17206146 b= 1.3159091
The total time is : 0 h 0 m 36.63376809600004 s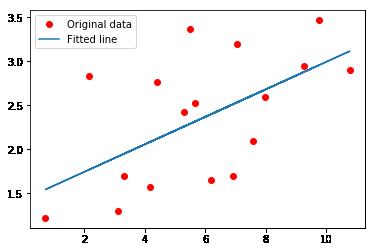
2.3.2 非线性回归例程测试
%matplotlib inline
# 图片内联且以矢量格式显示
# %config InlineBackend.figure_format = 'svg'
# 计算运行时间
# calculate time using
import timeit
start = timeit.default_timer()
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
x_data = np.linspace(-0.5, 0.5, 200)[:, np.newaxis]
noise = np.random.normal(0, 0.02, x_data.shape)
y_data = np.square(x_data) + noise
x = tf.placeholder(tf.float32, [None, 1])
y = tf.placeholder(tf.float32, [None, 1])
# 输入层一个神经元,输出层一个神经元,中间10个
# 第一层
Weights_L1 = tf.Variable(tf.random.normal([1, 10]))
Biases_L1 = tf.Variable(tf.zeros([1, 10]))
Wx_plus_b_L1 = tf.matmul(x, Weights_L1) + Biases_L1
L1 = tf.nn.tanh(Wx_plus_b_L1)
# 第二层
Weights_L2 = tf.Variable(tf.random.normal([10, 1]))
Biases_L2 = tf.Variable(tf.zeros([1, 1]))
Wx_plus_b_L2 = tf.matmul(L1, Weights_L2) + Biases_L2
pred = tf.nn.tanh(Wx_plus_b_L2)
# 损失函数
loss = tf.reduce_mean(tf.square(y - pred))
# 训练
train = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(2000):
sess.run(train, feed_dict={x: x_data, y: y_data})
print("第{0}次,loss = {1}".format(i, sess.run(loss,feed_dict={x: x_data, y: y_data})))
pred_vaule = sess.run(pred, feed_dict={x: x_data})
plt.figure()
plt.scatter(x_data, y_data)
plt.plot(x_data, pred_vaule, 'r-', lw=5)
# output time using
end = timeit.default_timer()
tdf = end -start
timeh = tdf // 3600
timem = (tdf % 3600) // 60
times = tdf % 60
print("The total cost time is : " , int(timeh) , "h" , int(timem) , "m" ,times, "s")结果 :
第0次,loss = 0.602253794670105
...
第1999次,loss = 0.00045431163744069636
The total cost time is : 0 h 0 m 24.807942360999732 s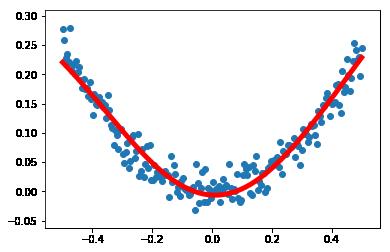
2.3.3 TensorBoard 可视化
用于教学目的的简单神经网络的在线演示、实验的图形化平台,非常强大的可视化了神经网络的训练过程。
http://playground.tensorflow.org/
安装 TensorBoard
pip3 install tensorboard --userTensorBoard可视化例程
运行手写数字识别MNIST的入门例子作为演示
虽然TensorFlow运行过程中可以自动下载数据集,但是经常容易断开连接且下载速度很慢。可以先下载数据集,MNIST数据集的官网是Yann LeCun‘s website
下载数据集 :
#训练集图片
wget http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz
#训练集图片对应的数字标签
wget http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz
#测试集图片
wget http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz
#测试集图片对应的数字标签
wget http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz并放在当前目录下的 MNIST_data 文件夹下
下载 Tensorflow 源码和例子
git clone https://github.com/tensorflow/tensorflow.git
# 当网络质量较差无法下载时,可以从国内镜像下载
git clone https://gitee.com/mirrors/tensorflow.git
# 复制例子到当前目录
cp tensorflow/tensorflow/examples/tutorials/mnist/mnist_with_summaries.py ./修改 mnist_with_summaries.py 文件中关于数据集和 TensorBoard log 目录的配置:
将如下内容
mnist = input_data.read_data_sets(FLAGS.data_dir,fake_data=FLAGS.fake_data)
parser.add_argument(
'--data_dir',
type=str,
default=os.path.join(os.getenv('TEST_TMPDIR', '/tmp'),
'tensorflow/mnist/input_data'),
help='Directory for storing input data')
parser.add_argument(
'--log_dir',
type=str,
default=os.path.join(os.getenv('TEST_TMPDIR', '/tmp'),
'tensorflow/mnist/logs/mnist_with_summaries'),
help='Summaries log directory')修改为:
mnist = input_data.read_data_sets("./MNIST_data",fake_data=FLAGS.fake_data)
parser.add_argument(
'--data_dir',
type=str,
default=os.path.join(os.getenv('TEST_TMPDIR', './'),
'MNIST_data'),
help='Directory for storing input data')
parser.add_argument(
'--log_dir',
type=str,
default=os.path.join(os.getenv('TEST_TMPDIR', './'),
'logs'),
help='Summaries log directory')然后开始训练并输出log
python3 mnist_with_summaries.py
Accuracy at step 990: 0.9685然后打开 TensorBoard
tensorboard --logdir=./logs
TensorBoard 1.13.1 at http://localhost:6006 (Press CTRL+C to quit)可以查看支持的7种可视化:
- SCALARS : 展示训练过程中的准确率、损失值、权重/偏置的变化情况
- IMAGES : 展示训练过程中记录的图像
- AUDIO : 展示训练过程中记录的音频
- GRAPHS : 展示模型的数据流图,以及训练在各个设备上消耗的内存和时间
- DISTRIBUTIONS : 展示训练过程中记录的数据的分布图
- HISTOGRAMS : 展示训练过程中记录的数据的柱状图
- EMBEDDINGS : 展示词向量(如 Word2Vec )后的投影分布
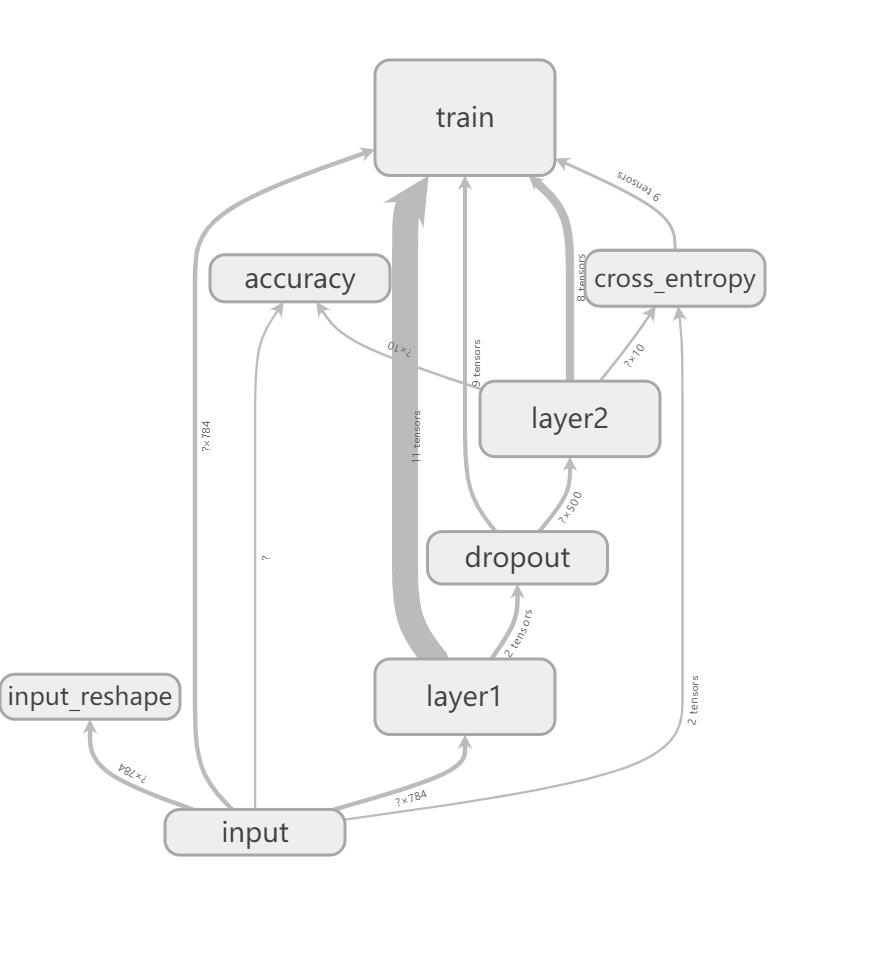
SCALARS 面板
左边是以下选项,包括 split on undercores (用下划线分开显示) 、 data downloadlinks(数据下载链接)、smoothing (图像的光滑程度) 以及 horizontal axis (水平轴)的表示,其中水平轴有三种(step 代表迭代次数,relative代表训练集和测试集的相对值,wall代表时间)
右边的图分别是 准确率 交叉熵损失函数值 每一层的偏置(biases)和权重(weights),包括每次迭代中的最大值、最小值、平均值和标准差
IMAGE 面板
展示了训练数据集和测试集经过预处理后图片的样子
GRAPHS 面板
对理解神经网络结构最有帮助的一个面板,它直观地展示了数据流图。节点之间的连线即为数据流,连线越粗,说明在两个节点之间流动的张量(tensor)越多
在面板左侧,可以选择迭代步骤。可以用不同color(颜色)来表示不同的 structure(整个流图的结构),或者用不同的 color 来表示不同的 device (设备)。
当我们选择特定的某次迭代时,可以显示出各个节点的 computer time (计算时间) 以及 memory (内存消耗)
DISTRIBUTIONS 面板
用平面来表示来自特定层的激活前后、权重和偏置的分布
HISTOGRAMS 面板
主要是立体地展现来自特定层的激活前后、权重和偏置的分布
3. TensorFlow 基础
顾名思义, TensorFlow 是指 “张量的流动”。TensorFlow 的数据流图是由 节点(node) 和边 (edge)组成的有向无环图(directed acycline graph , DAG) TensorFlow 由 Tensor 和 Flow 两部分构成,Tensor代表了数据流图中的边 ,而 Flow 这个动作代表了数据流图中节点所做的操作
TensorFlow 支持卷积神经网络(convolutional neural network , CNN)和循环神经网络(recurrent neural network , RNN)以及 RNN 的一个特例 长短期记忆网络 (long short-term memory , LSTM)
特性
- 高度的灵活性 :采用数据流图(date flow graph)
- 可移植性
- 自动求微分:只需要定义预测模型的结构和目标函数
- 多语言支持:核心部分使用C++实现
- 最优化性能
3.1 数据流图
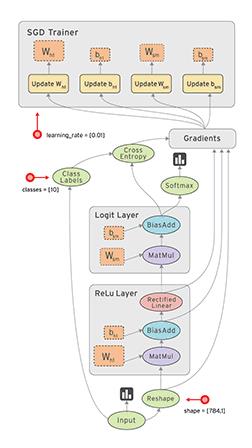
3.1.1 边
边 有两种连接关系:数据依赖和控制依赖。其中,实线边表示数据依赖,代表数据,即张量。任意维度的数据统称为张量。张量在数据流图中从前向后流动一遍就完成了一次前行传播(forward propagation),而 残差(数理统计中,残差指实际观察值与训练估计值之间的差)从后向前流动一遍就完成了一次反向传播
还有一种边,一般画为虚线边,称为 控制依赖 (control dependency),可以用于控制操作的运行,这被用来确保 happens-before 关系,这类边上没有数据流过,但源节点必须在目的节点开始前完成执行。常用代码:
tf.Graph.control_dependencies(control_inputs)有关图以及张量的实现源码在 /tensorflow/python/framework/ops.py
3.1.2 节点
又称为算子,代表一个操作,一般用来表示施加的数学运算,也可以表示 数据输入(feed in)的起点以及 输出(push out) 的终点,或者读取/写入 持久变量(persistent variable)的终点。
与操作相关的代码位于 /tensorflow/python/ops/ 目录下
3.1.3 图
把操作任务描述成 有向无环图
3.1.4 会话
启动图的第一步是创建一个会话。要创建并运行操作的类,在Python的API中使用 tf.Session,在C++的API中使用tensorflow::Session。示例:
with tf.Session() as sess:
result = sess.run([product])
print result在调用 Session 对象的 run() 方法来执行图时,传入一些 Tensor ,这个过程叫做 填充 (feed);返回的结果类型根据输入的类型而定,这个过程叫做取回(fetch)
与会话有关的代码位于 /tensorflow/python/client/session.py
会话主要有两个 API 接口: Extend 和 Run 。Extend 操作是在 Graph 中添加节点和边 ,Run 操作是输入计算的节点和填充必要的数据后,进行运算并输出运算结果
3.1.5 设备
指一块可以用来运算并且拥有自己的地址空间的硬件,为了实现分布式执行操作,充分利用计算资源,可以明确指定操作在哪个设备上执行。
with tf.Session() as sess:
with tf.device("/gpu:1")
result = sess.run([product])
print result与设备有关的代码位于 /tensorflow/python/framwork/device.py
3.2 优化方法
目前加速训练的优化方法都是基于梯度下降的,只是细节上有些差异。梯度下降是求函数极值得一种方法,学习到最后就是求损失函数的极值问题。
TensorFlow 提供了很多 优化器(optimizer)
- class tf.train.GradiwentDescentOptimizer # 梯度下降法(BGD 和 SGD)
- class tf.train.AdadeltaOptimizer
- class tf.train.AdagradDAOptimizer
- class tf.train.MomentumOptimizer
- class tf.train.AdamOptimizer
- class tf.train.FtrlOptimizer
- class tf.train.RMSPropOptimizer
其中 BGD 、 SGD 、Momentum 和 Nesterov Momentum 是手动指定学习率的,其余算法能够自动调节学习率
3.2.1 BGD
全称是 batch gradient descent 即批梯度下降,优点是使用所有训练数据计算,能够保证收敛,并且不需要逐渐减小学习率;缺点是,每一步都需要使用所有的训练数据,随着训练的进行,速度会越来越慢
3.2.2 SGD
stochastic gradient descent 即随机梯度下降,将数据集随机拆分成一个个批次(batch),随机抽取一批数据来更新参数,所以也称为 MBGD (minibatch gradient descent)。在训练集很大时仍然以较快的速度收敛。缺点:(1)抽取时不可避免地梯度会有误差,需要手动调整学习率,但是选择合适的学习率比较困难。(2)容易收敛到局部最优
3.2.3 Momentum
模拟物理学中动量的概念,更新时在一定程度上保留之前的更新方向,利用当前的批次再微调本次的更新参数,因此引入了一个新变量 v(速度),作为前几次梯度的累加 ,因此,能过更新学习率,在下降初期,前后梯度方向一致时,能够加速学习;在下降的中后期,在局部最小值的附近来回震荡时,能够抑制震荡,加快收敛
3.2.4 Nesterov Momentum
自适应学习率优化方法
3.2.5 Adagrad
自适应地为每个参数分配不同的学习率,能够控制每个维度的梯度方向。优点是能够实现学习率的自动更改:如果本次更新时梯度大,学习率就衰减得快一些;如果这次更新时梯度较小,学习率衰减就慢一些。缺电:学习率单调递减,在训练后期学习率非常小,并且需要手动设置一个全局的初始学习率
3.2.6 Adadelta
为了解决Adagrad 的缺点,用一阶的方法近似模拟二阶牛顿法
3.2.7 RMSProp
引入一个衰减函数,使每一个回合都衰减一定的比例。在实践中,对 循环神经网络 (RNN)效果很好。
3.2.8 Adam
源于 自适应矩估计(adaptive moment estimation)。Adam 法根据损失函数针对每个参数的梯度的一阶矩估计动态调整每个参数的学习率。
3.2.9 方法比较
在不怎么调整参数的情况下,Adagrad法比 SGD法和 Momentum 法 更稳定,性能更优;精确调整参数的情况下,SGD法和Momentum 法在收敛速度和准确性上优于 Adagrad法。
3.3设计理念:
3.3.1 将图的定义和图的运行完全分开
在现代深度学习框架中,Torch 是典型的命令式的,Caffe、MXNet 采用了两种编程模式混合的方法,而 TensorFlow 完全采用符号式编程
符号式计算一般是先定义各种变量,然后建立一个数据流图,在数据流图中规定各个变量之间的计算关系,最后需要对数据流图进行编译,把需要运算的输入放进去后,在整个模型中形成数据流,从而形成输出值
3.3.2 涉及的运算都要放在图中
图的运行只发生在 会话 (session) 中。开启会话后,就可以用数据去填充节点,进行运算;关闭会话后,就不能计算了。会话提供了操作运行和Tensor 求值的环境。
参考资料
- 安装、配置Jupyter Notebook快速入门教程
- 访问虚拟机中的jupyter
- JupyterLab——更具生产力的Jupyter环境
- 玩转Jetson Nano(三)安装TensorFlow GPU
- 《TensorFlow技术解析与实战》 李嘉璇 著 2017年4月版
以上是关于Tensorflow的安装和使用——Jetson Nano 初体验3的主要内容,如果未能解决你的问题,请参考以下文章
Nvidia Jetson TX2 上编译安装 TensorFlow r1.5
markdown Jetson Tx2的tensorflow-gpu安装
在 Jetson nano 和 jetson xavier 上运行 Nvidia-docker 以实现 tensorflow 等深度学习框架