基于Distiller的模型压缩工具简介
Posted fourmi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于Distiller的模型压缩工具简介相关的知识,希望对你有一定的参考价值。
Reference:
https://github.com/NervanaSystems/distiller
https://nervanasystems.github.io/distiller/index.html
PART I: 介绍
Distiller模型压缩包含的算法: 稀疏算法(剪枝+正则化)+低精度算法(量化)
Distiller特点:
(1) 该框架融合了剪枝,正则化及量化算法
(2) 一系列分析及评估压缩性能的工具
(3) 较流行压缩算法的应用
稀疏神经网络可以基于 (weight and biases) activations的稀疏tensor进行计算。
关注稀疏度的原因:对于像GoogleNet 之类的大型网络,对计算十分敏感,在经过加速处理过的设备上进行inference仍需花费大量时间。较大的模型占用内存资源
在移动端模型的存储及转移主要受到模型的大小及下载时间限制
Smaller
具有稀疏表示的数据并不需要进行解压缩
三种表示方法:1.稀疏表示,2.密集表示,3.针对硬件特点进行特殊的表示
通过剪枝及正则化处理,对于向量计算的compute engine的权重删除。
Faster
神经网络中的许多层都是bandwidth-bound,这意味着执行时间主要是被可利用的bandwidth占用,其中,占用时间比较长的为全连接层,同时RNN及LSTM层存在大量的bandwidth-dominated操作。
Pruning:对网络中的权重及激活值进行稀疏化处理,基于二元标准来进行决定那个权重可以修剪。将满足修剪标准的权重进行赋值为0并不让其参见反向传播运算。
可修剪的对象包括:权重,偏差及激活值。
稀疏性:张量中存在0元素的个数占整个tensor向量中的比例,L0正则化,统计非0元素的个数
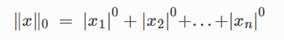
Density = 1 – sparsity
Distiller工具:distiller.sparsity distiller.density
权重/模型修剪:用于提高网络权重稀疏性的一系列方法,通过一个修剪标准来决定哪个元素需要进行修剪,标准即pruning criteria,最常用的标准是每个元素的绝对值,其值与某个阈值进行比较,如果低于这个阈值,就将该元素的值置为0.
Distiller工具:distiller.MagnitudeParameterPruner 基于L1正则化的对于最终结果贡献量较小的权重重要性较低,而且可以被移除。
对于prune的理解 :参数量较大的模型中,存在大量的逻辑及特征冗余。一种想法是搜索尽可能多的权值为0的权重,同时在inference时可以达到与密集模型相似的准确率。另一种想法是,在高维度的参数空间中,密集模型的解空间中可能会存在一些稀疏解,修剪算法就是为了寻找这个稀疏解。
One-shot pruning :对一个训练好的模型进行一次修剪
Iterative training :pruning-followed-by-retraining(fine-tuning),在训练迭代过程中,需要考虑的问题包括:pruning的标准是如何改变,迭代多少次,多久变化一次,那些张量需要被prune,这些被称为pruning schedule
对Iterative pruning 的理解:基于一个评价标准将权重进行重复训练学习,判断哪个权重是重要的,并将不重要的权重进行删除。 调整后的权重将模型进行性能上的恢复,每次迭代修剪更多的权重。
修剪的停止条件也在schedule中,其取决于修剪算法。停止条件两个参考: specific sparsity level,required compute budget
修剪粒度(pruning granularity):对单个权重元素进行修剪,称为element-wise修剪,有时被称为find-grained pruning
Coarse-grained pruning: structure pruning , group pruning(filter pruning整个filters被移除),block pruning
敏感度分析:
将稀疏性引入修剪过程中的难点在于:对于每层网络张量中,阈值的选择及sparsity level,根据张量对修剪的敏感度进行排序。
其思想是,针对特定的网络层设置pruning level(percentage),只对模型修剪一次,然后在测试数据集上进行评估并记录得到的分数值。若在每个参数化的网络层上应用此方法,在每个层上设置多个sparsity levels,可以得到每个层对于修剪的敏感性。
在进行敏感度分析前,预训练模型应达到最大的准确率,这是因为需要了解对于特定层权重的修剪对模型的性能造成的影响。
Distiler可以对结构进行敏感性评估,基于L1 –normal的独立元素进行element-wise pruning 敏感度分析以及基于filters间的mean L1-Norm 的filter-wise pruning 。
相关函数:perform_sensitivity_analysis
正则化: 对模型算法进行修改的主要目的是减少generalization loss而不是训练损失。
正则化与网络稀疏表达的关系:
通过稀疏修剪对模型进行正则化处理:在给定sparsity constraint的限制条件下,网络一旦达到了局部最小值,则放宽限制条件,让网络可以以更高准确率逃离局部极小值的鞍点。
正则化也可以应用到稀疏表达中:L2正则化可以减少过拟合,同时压缩较大值的参数,但无法使这些参数的值完全变为0。而L1正则化则可以将某些参数置为0,在限制模型的同时对模型进行了简化处理。
Group Regularization:
对整个groups of parameter elements进行正则化处理。无论这个group是否被稀疏化处理过,该group结构都要预先定义。

Distiller中的相关函数: distiller.GroupLassoRegularizer
量化
量化是减少表示一个数的bit位数的过程,deep learning中的主流精度为32位浮点精度。为了降低网络模型的带宽及计算需求,开始转向较低精度的研究。
如果权重为二值的,如(-1,1)或者为(-1,0,1)则卷积层及全连接层中的计算可以由加减操作执行,将乘法操作完全移除。如果激活值也为二值类型的,则加法操作也可以移除,可以用位运算代替。
Integer与FP32的对比
数字精度的两个属性,I:动态范围,即可以表示数字的范围。II:根据需要表示的数值来决定精度。对于n位整形数字,其动态范围为[-2^(n-1)..2^(n-1)-1],INT8:[-128,127],可以表示2^(N)个数字,网络模型中32位精度能够表示的分布范围更广,同时,模型中不同层动态范围是不同的,权重及activation的分布也是不同的。
为了将tensor的浮点动态范围映射到整数精度的范围内增加了一个scale factor,scale factor大部分情况为浮点型。
避免溢出
累加器中存放卷积层及全连接层的中间结果。如果,将权重以及激活值的设置相同的比特位,很快就会溢出。因此,累加器中的精度要更高一些。两个n-bit的数字相乘得到2n-bit的数字,卷积层中存在c*k^2次乘法操作,为了避免溢出,累加器的位数应为(2n+M),M至少为log2(c*k^2)
保守量化:INT8
如果将一个FP32的预训练模型不进行再训练直接将其量化为INT8,则会造成一定准确率的损失。
Simple factor的设置:根据每个tensor中的每一层进行确定,最简单的方式就是将float tensor中的min/max映射为integer中的min/max,对于权重及偏差,这种操作比较简单,是因为其训练完成后,其值是固定的,而对于activation,其值可以从两个方面进行获得。
(1)Offline:即在部署模型之前进行激活值统计操作,基于统计的信息,计算得到scale factor,当模型部署完后将其值固定。这种方式存在一定的风险,即运行时,遇到的值超出了原来观察到的范围,而这个超出的值会被clip,进而造成准确率上的损失。
(2)Online:即在运行时动态的计算tensor中的min/max值。这种方式不会发生clip情况。而增加的计算量却很大。
基于全精度的激活层存在异常值,可以通过缩小min/max的范围将这个异常值进行丢弃,同时,也可以通过clip操作来提高包含主要信息部分的精度。一种简单有效的方式是用min/max的均值来替换实际的值
另一个可以优化的点是scale factor:最常用的方法是每一层使用scale-factor,也可以每个通道进行设置。
贪婪型量化:INT4
将FP32模型直接量化为INT4或者更低的精度,使准确率大幅度降低
解决方法:
(1) training/retraining:将量化考虑到训练中
(2) 替换激活函数:将无边界的ReLU替换为有边界的激活函数。
(3) 调整网络的结构:通过增加层的宽度来弥补由于量化产生的损失信息。或者将卷积用多个二值卷积进行替换,通过scale可以调整覆盖更大的范围
(4) 模型的第一层和最后一层不进行量化操作
(5) 迭代量化:首先对预训练的FP32的模型进行部分量化,然后进行再训练恢复由于量化产生的准确率的损失
(6) 将权重及激活值的精度进行混合:激活对量化的敏感度相比权重要更敏感一些
包含量化的训练
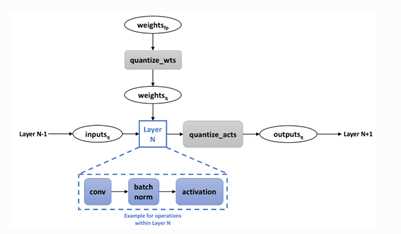
训练过程中全精度的权重也被保留,用于记录精度损失造成 的梯度上的变化,inference时只有量化后的权重起作用。
PART II: 基于Distiller 的分类模型
Step I : git clone https://github.com/NervanaSystems/distiller.git
Step II: 创建环境 python3 –m virtualenv env (安装参考: https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/)
StepIII: cd distiller && pip3 install -e .
StepIV: cd distiller/examples/classifier_compression
StepV: 只对模型进行训练,不进行压缩处理
python3 compress_classifier.py --arch simplenet_cifar ../../../data.cifar10 -p 30 -j=1 --lr=0.01
--arch:模型名称
-p:打印频率
-j: 线程
--lr:学习率
StepVI: 统计稀疏模型的参数
python3 compress_classifier.py --resume=../ssl/checkpoints/checkpoint_trained_ch_regularized_dense.pth.tar -a=resnet20_cifar ../../../data.cifar10 --summary=sparsity
--resume:稀疏模型文件路径
--summary: {sparsity,compute,model,modules,png,png_w_params,onnx}
Sparsity:统计稀疏信息
Compute:统计计算量信息
Model:详细的模型描述
Modules:每层对应的类型
PNG:将网络结构保存为图片
png_w_params:将网络中的权重信息保存为图片
打印信息
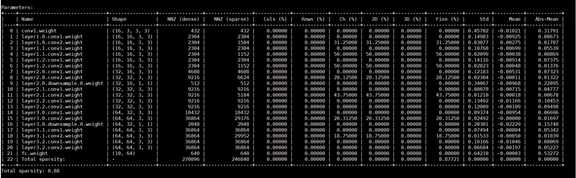
Name:处理层名称
Shape:该层尺寸
NNZ(dense):稀疏前该层的参数量,其值为shape[0]*shape[1]*shape[2]*shape[3]
NNZ(sparse):处理后该层的参数量。
Cols,Rows,Ch,2D,3D,Fine分别代表,在纵向,横向,Channel-wise,Kernel-wise,Filter-wise,Element-wise(属于Fine-grained pruning)上参数稀疏的程度,其值为(NNZ(dense)-NNZ(sparse)) / NNZ(dense)
Std:该层的标准差
Mean: 该层的均值
Abs-Mean:该层绝对值的均值
Total sparsity = (total_NNZ(dense) – total_NNZ(sparse)) / total_NNZ(dense)
StepVII: 统计稀疏模型的计算量
python3 compress_classifier.py --resume=../ssl/checkpoints/checkpoint_trained_ch_regularized_dense.pth.tar -a=resnet20_cifar ../../../data.cifar10 --summary=sparsity
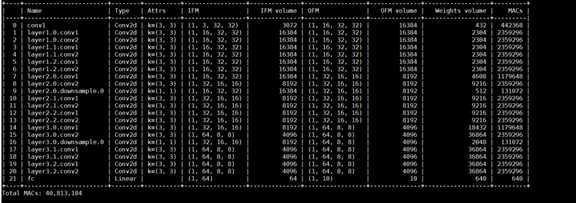
Name:该层名称
Type:该层的类型
Attrs: 卷积核大小
IFM:输入尺寸
IFM volume:输入维度 = IFM[0] * IFM[1] * IFM[2] * IFM[3]
OFM:输出尺寸
OFM volume:输出维度 = OFM[0] * OFM[1] * OFM[2] * OFM[3]
Weights volume:权重维度 = Attrs[0] * Attrs[1] * IFM[1] * OFM[1]
MACs = OFM[2] * OFM[3] * Weights volume
Step VIII: post-training quantization
python3 compress_classifier.py -a resnet20_cifar ../../../data.cifar10 --resume ../ssl/checkpoints/checkpoint_trained_dense.pth.tar --quantize-eval --evaluate
--quantize-eval 在进行evaluate前进行线性量化操作
PART III: Distiller 代码部署步骤
Step I: 在 main.py中增加代码
1. Preparing the code: 调用Distiller 通过sys.path将distiller的根目录引入到main.py文件中。
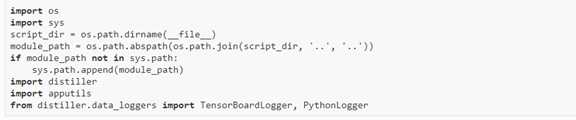
2. 置定义输入参数

--summary:有关压缩说明
--compress:指明 compression schedule文件路径
增加对上面两个参数的处理代码


3. Optimizer及learning-rate decay policy scheduler

4. setup the logging backends:一个是Python logger backend用于从文件及命令行中读取参数;另一个是TensorBoard backend logger将logs信息变为tensorboard 数据文件(tflogger)

5. Training loop:
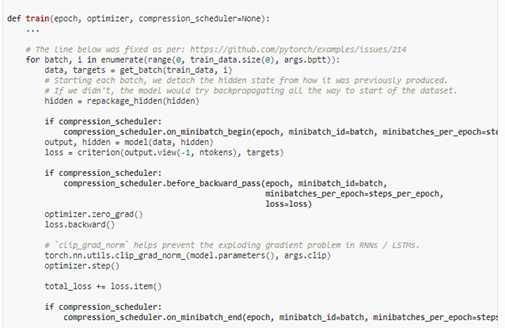
6. 下列代码位于train中用于记录信息
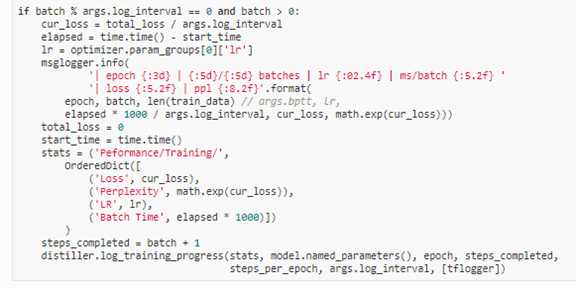
7. 在train外进行迭代训练优化

以上是关于基于Distiller的模型压缩工具简介的主要内容,如果未能解决你的问题,请参考以下文章