Python 小爬虫流程总结
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 小爬虫流程总结相关的知识,希望对你有一定的参考价值。
接触Python3一个月了,在此分享一下知识点,也算是温故而知新了。
接触python之前是做前端的。一直希望接触面能深一点。因工作需求开始学python,几乎做的都是爬虫。。第一个demo就是爬取X博数据,X博的API我在这就不吐槽了 。用过的估计都晓得。
好了 。下面进入正题,,一个小demo的开始与结束 。
1.首先对于像我一样0基础的,推荐几个网址:
廖雪峰的教程从安装到基本语法、模块安装等等基础都不简单易懂。这里就不赘述了
(1).http://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000
(2)http://cn.python-requests.org/zh_CN/latest/ requests模块的语法。请求是爬数据的起始点 ,这个可以多了解(然而我也是初学)
(3)https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html BeautifulSoup模块(核心就是节点操作,和js的节点操作挺像)
爬取简单数据我个人总结就是大致的 3点:
1、请求数据
2、进行数据处理
3、写数据
第一点 请求的数据 会有几种可能:
1、很简单的html页面。。就直接requests就可以请求成功
2、js渲染的页面 (这种页面超多)requests请求一堆js数据 (以前我用的一个模块 selenium (代码基于浏览器运行) 推荐大家千万别用,性能 很差。)
3、需要登录才能获取(( ̄▽ ̄)")至今登录我都是用的cookie 请求登录—— 其他更好的方法目前还在研究途中 有验证码更麻烦 balabala...(chookie有效期长的话直接就用就好了 )
4、json数据
第二点 数据处理 会有几种可能:
1、请求的数据是简单的html结构页面--直接BS4解析就好了
2、请求的数据是json--导入json模块进行解析
3、请求的数据是简单的js渲染的html页面
遇到这种页面(通过抓包 或者简单的在网站上审查请求) 然后找的你想要的那部分数据(数据有可能是json数据 有可能嵌到js中)
如果是js渲染的html 例如这样:
这其实就是js拼写的html,,只要把其他无用的数据匹配掉用正则找到剩下想要的html文本就好了 。
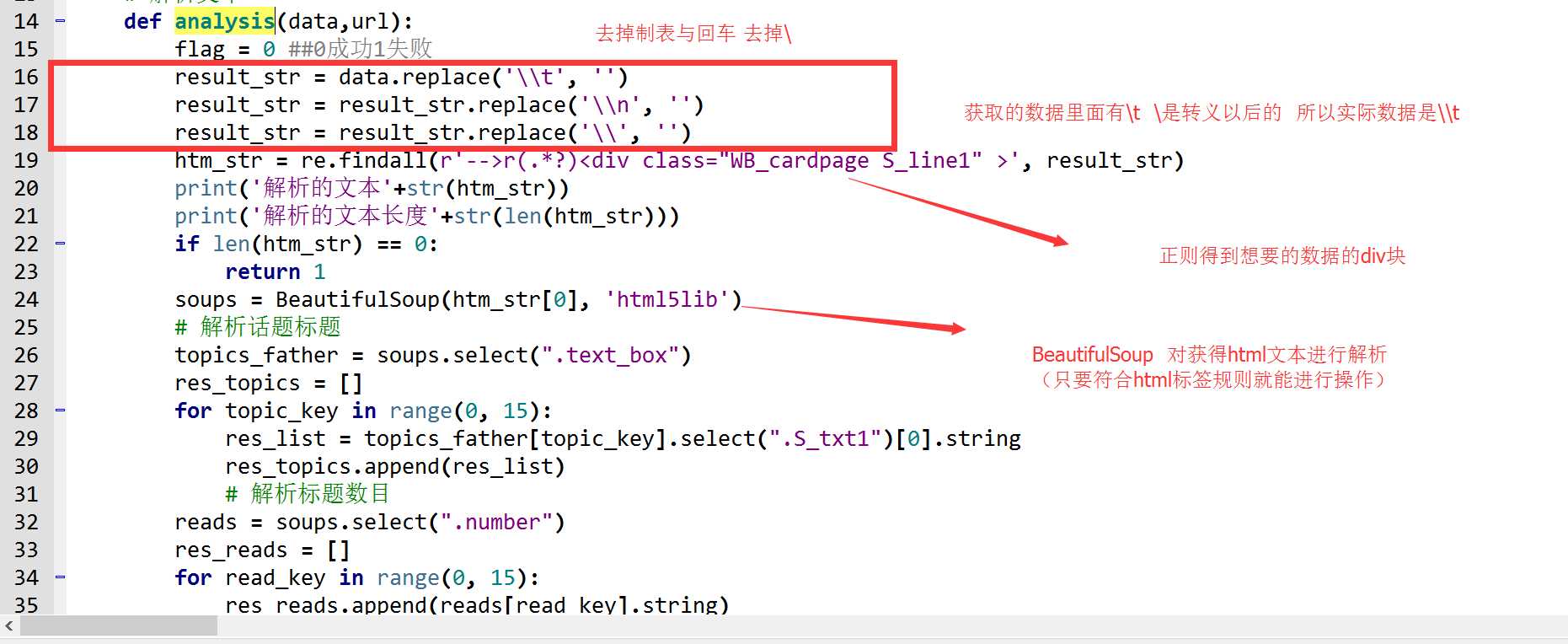
然后BS4解析。。
第三点 写数据(当初一个编码格式弄了半天 在这我会多啰嗦几句)
open方法进行文件打开 里面的参数进行文件格式设置,读写文件、编码格式操作
with open("XXX.xxx","a",encoding="utf-8") as f :
f.write(‘‘‘写入的数据‘‘‘)
文件格式我用过的就是txt、csv 、xml 大部分文本格式都支持的。
a--是创建文件 每次写都是重新创建
w--是追加
a--是读数据
encoding="utf-8"这句话 不加encoding= 在windows系统下会报编码错误 linux不会。
然后就是数据量太大 写入到数据库
数据库就用sqlite 记得引入模块 import sqlite3(就是创建数据表等等。。教程里面都有。。)
目前先就这样,以后会不定期总结 也会直接更代码案例等...
以上是关于Python 小爬虫流程总结的主要内容,如果未能解决你的问题,请参考以下文章
python爬虫知识点总结Requests+正则表达式爬取猫眼电影