Python爬虫之网站验证码识别
Posted 胜天半月子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫之网站验证码识别相关的知识,希望对你有一定的参考价值。
前言
- 验证码和爬虫之间的爱恨情仇?
门户网站所提供的一种反爬机制:验证码
- 应用场景
识别下图中的验证码
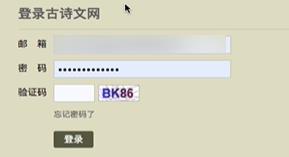
爬取基于用户的相关信息时,我们需要在爬取数据之前做登录的操作:
- 浏览器中进行登录操作很简单只需要输入相关信息后点击登录即可
- 用requests模块登陆操作时,可能需要提交验证码
- 如何做
识别验证码图片中的数据,用于模拟登陆操作:
- 人工肉眼识别(不推荐)
有些验证码干扰线少,肉眼可以识别清楚,而有些肉眼无法识别清除,需要切换验证码识别,效率低下- 第三方自动识别(推荐⭐)
云打码:http://www.yundama.com/demo.html 需要收费(已经无法使用了)
一、云打码平台使用流程
由于该平台已经无法使用,我们先在此记录使用流程,然后使用其他的平台(推算:不同平台之间的使用流程应该相差无几,但是具体平台要具体分析 )
操作流程
- 注册
普通用户和开发者用户(两种都要注册)
- 登录
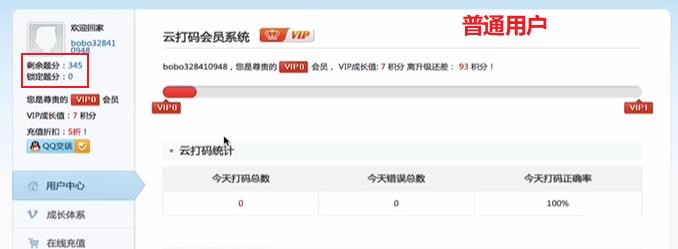
- 普通用户的登录
登录成功后,你需要:
- 查看登陆积分:
有积分则继续使用,没有积分则充值
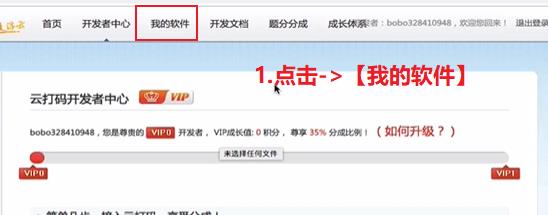
- 开发者用户登录
登录成功后,你需要:
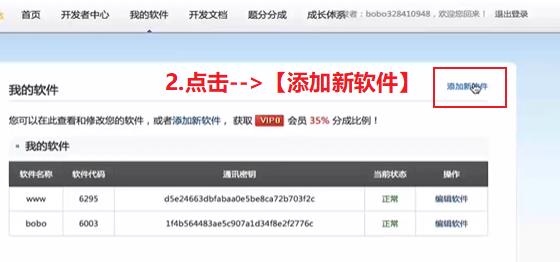
创建一个软件:
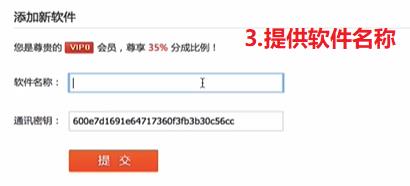
点击【①我的软件】–>【②添加新软件】–>【③录入软件名称】最后点击提交即可
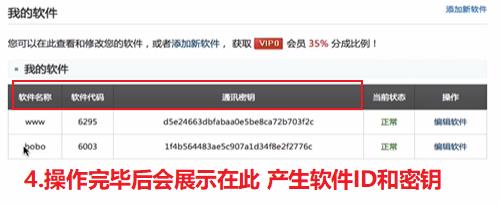
成功提交后,提供的信息:-软件名称 -软件ID -通讯密钥【ID和密钥是后续编码需要使用的】点击开发文档:
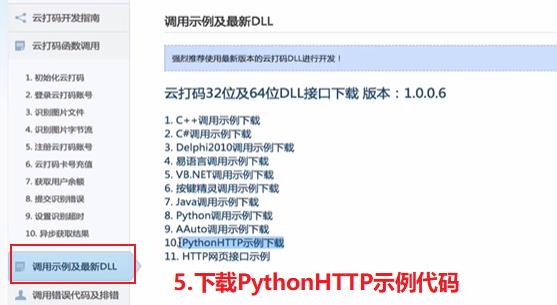
【①下载示例代码】–> 【②点此下载:云打码接口DLL】–> 【③选择Python语言示例下载】–> 【④解压缩下载好的文件并copy当前文件】–> 【⑤修改下载好的.py文件】
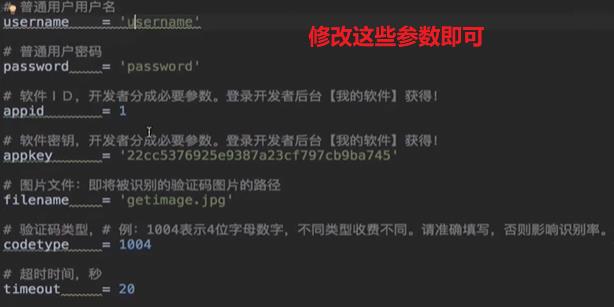
- 修改下载好的.py文件
注意事项⭐(按顺序看文章可能不理解,但没关系请往下看):
- 用户名和密码需要录入普通用户(普通用户登录有积分,商家扣除才会有收入)
- 软件ID和密钥需要换成我们录入软件所提供的ID和密钥
- 要对想要被识别的验证码进行下载
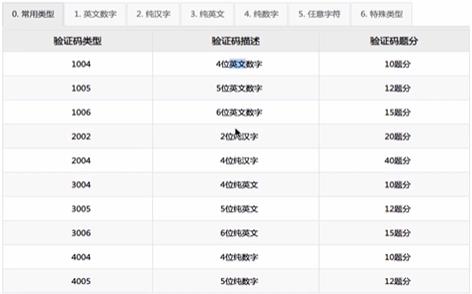
- 指定验证码类型,查看云平台的价格表【价格表中有类型】
- 指定超时时间【允许验证码平台识别耗时的最大时间】,一般指定15-20s
修改上述参数即可
- 修改之前
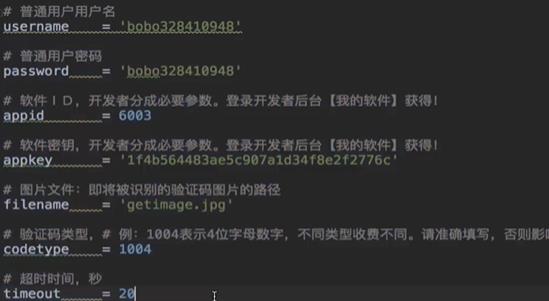
- 修改之后
- 验证码类型
- 图解登录流程
- 普通用户的登录
- 开发者用户登录
二、代码编写⭐
这个章节只是提供思路,视频中的验证码识别平台已经无法使用了(已经倒闭),但是问题的处理思路是一样的
2.1 使用超级鹰云平台
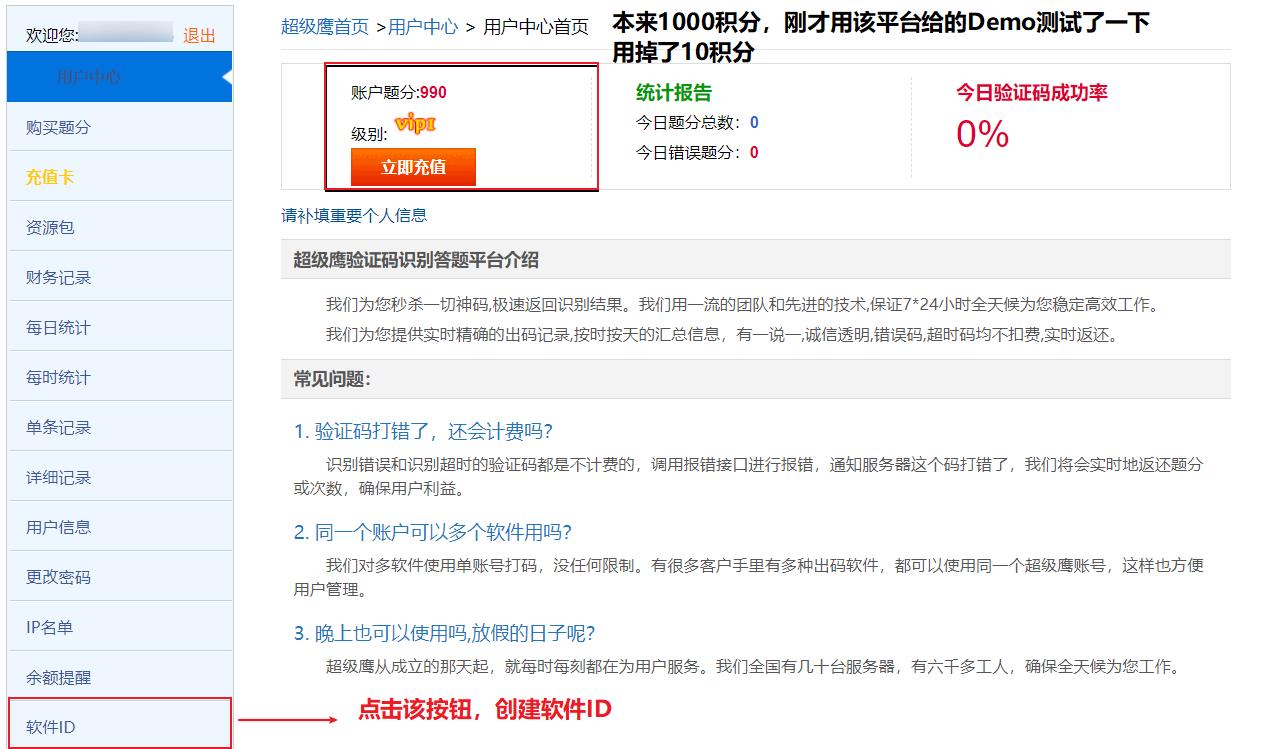
我在网上找了一个可以使用的验证码识别平台:超级鹰官方网站,相对于视频教程中不仅需要普通用户,还需要开发者用户方便许多,这个超级鹰云平台只需要注册一个账号即可,而且我充值了一块钱作为测试使用(其实一毛钱就够用,每次需要10积分,1元=1000积分,但是平台最低充值1元钱
( ╯□╰ ))
-
注册

-
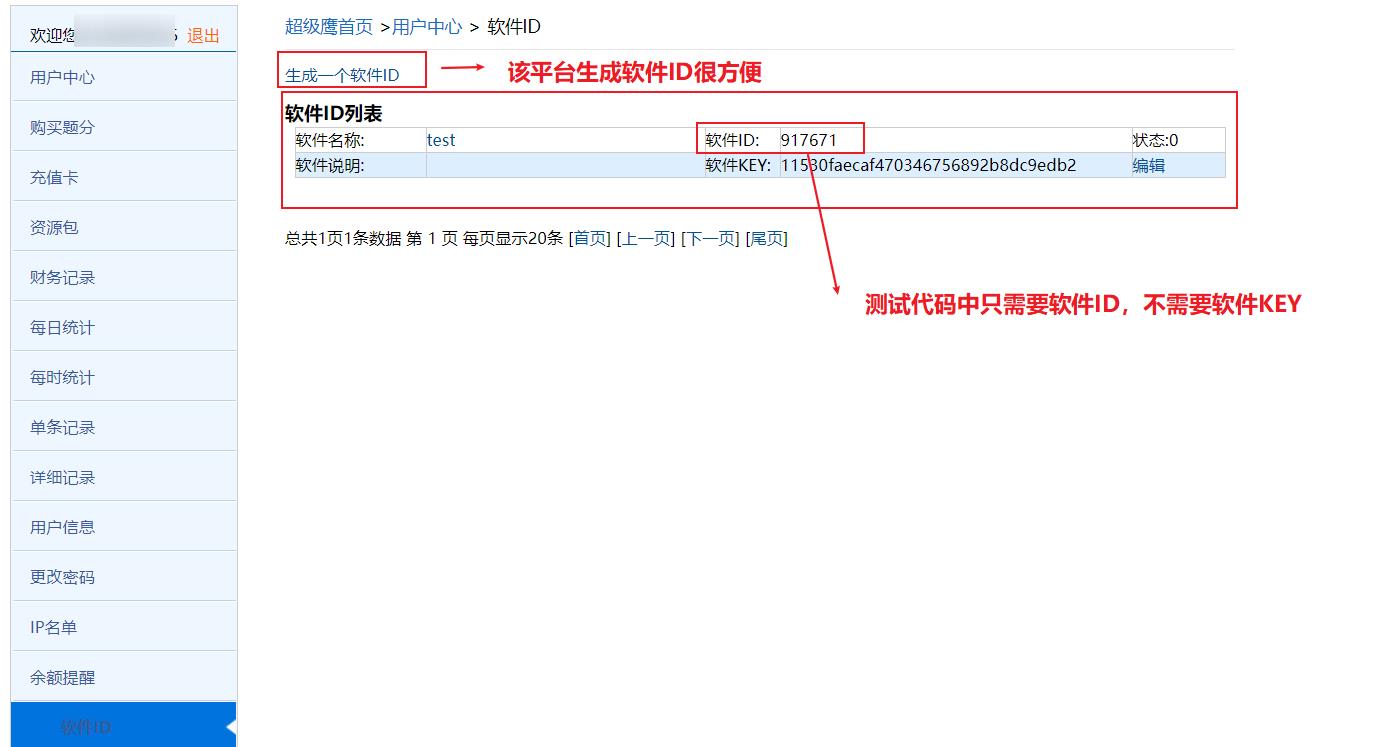
创建软件ID

-
下载测试Demo


-
修改测试代码
- Demo内部
- 测试图片

- 具体修改

- Demo测试

2.2 实战演练⭐
- 主要代码
超级鹰网站下载的API我没有放到博客里,自己去官网下载即可
import requests
from lxml import etree
from chaojiying import getCodeText
if __name__ == "__main__":
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36'
}
url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx'
page_text = requests.get(url=url,headers=headers).text
# 解析验证码图片img中src属性值
tree = etree.HTML(page_text)
code_img_src = 'https://so.gushiwen.cn'+ tree.xpath('/html/body/form[1]/div[4]/div[4]/img/@src')[0]
print('image url:',code_img_src)
img_data = requests.get(url=code_img_src,headers=headers).content # 二进制数据
with open('./code.jpg','wb') as fp:
fp.write(img_data)
# 运用云打码平台进行验证码解析
img_code = getCodeText('./code.jpg')
print(img_code)
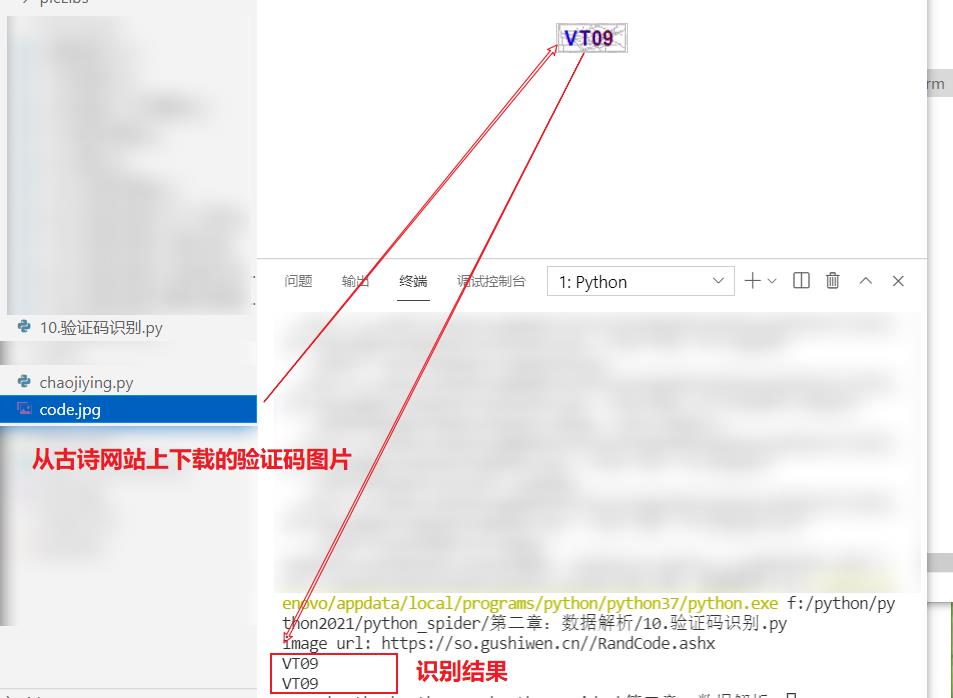
- 识别结果
由于每次的验证码图片都不一样。因此执行一次程序,结果显示也都会不同
- 第一次测试
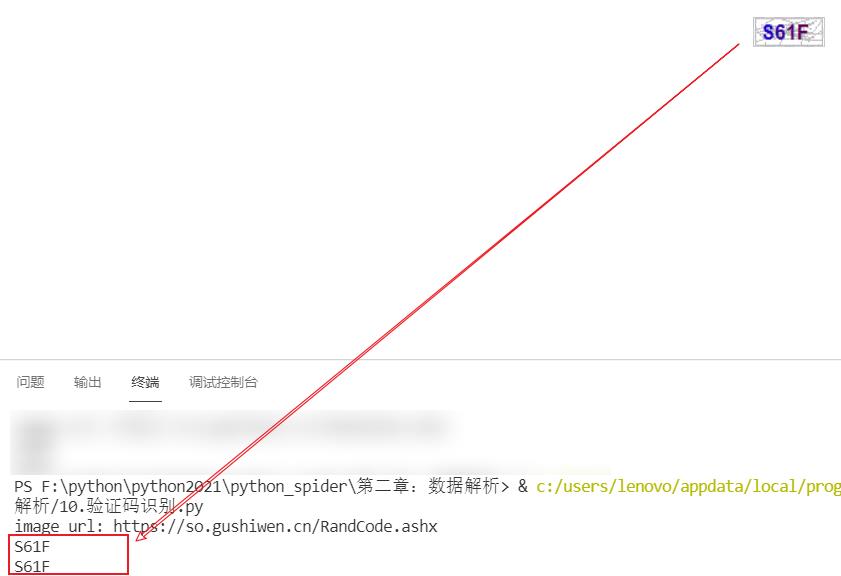
- 第二次测试
- 第三次测试
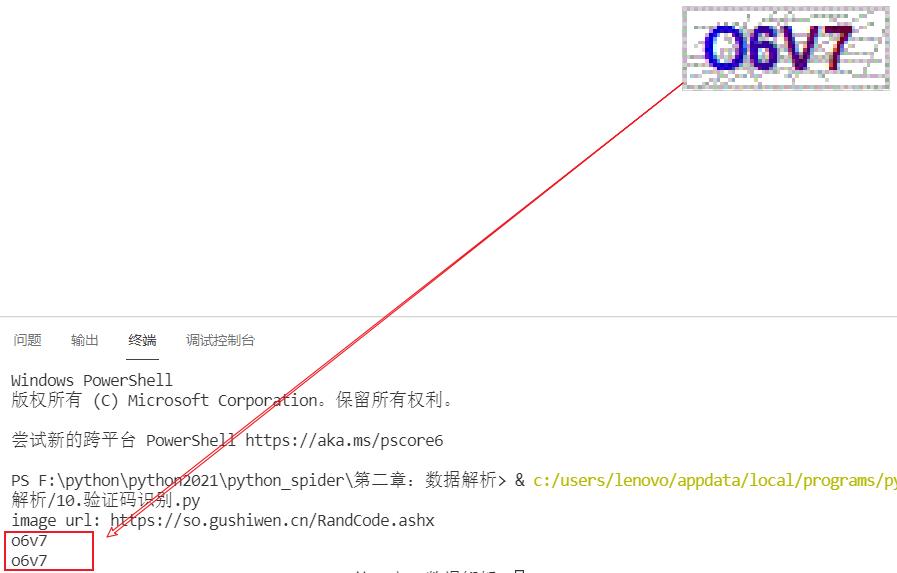
综上三次测试可知该平台的识别效果还是不错的
总结
初步了解了如何通过第三方平台进行网站验证码的识别,进一步了解了爬虫能做的事情。
此外,如果大家想使用我的账号、密码欢迎私信我
以上是关于Python爬虫之网站验证码识别的主要内容,如果未能解决你的问题,请参考以下文章