Python开发轻量级爬虫
Posted 左岸繁华右岸殇
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python开发轻量级爬虫相关的知识,希望对你有一定的参考价值。
这两天自学了python写爬虫,总结一下:
开发目的:抓取百度百科python词条页面的1000个网页
设计思路:
1,了解简单的爬虫架构:

2,动态的执行流程:
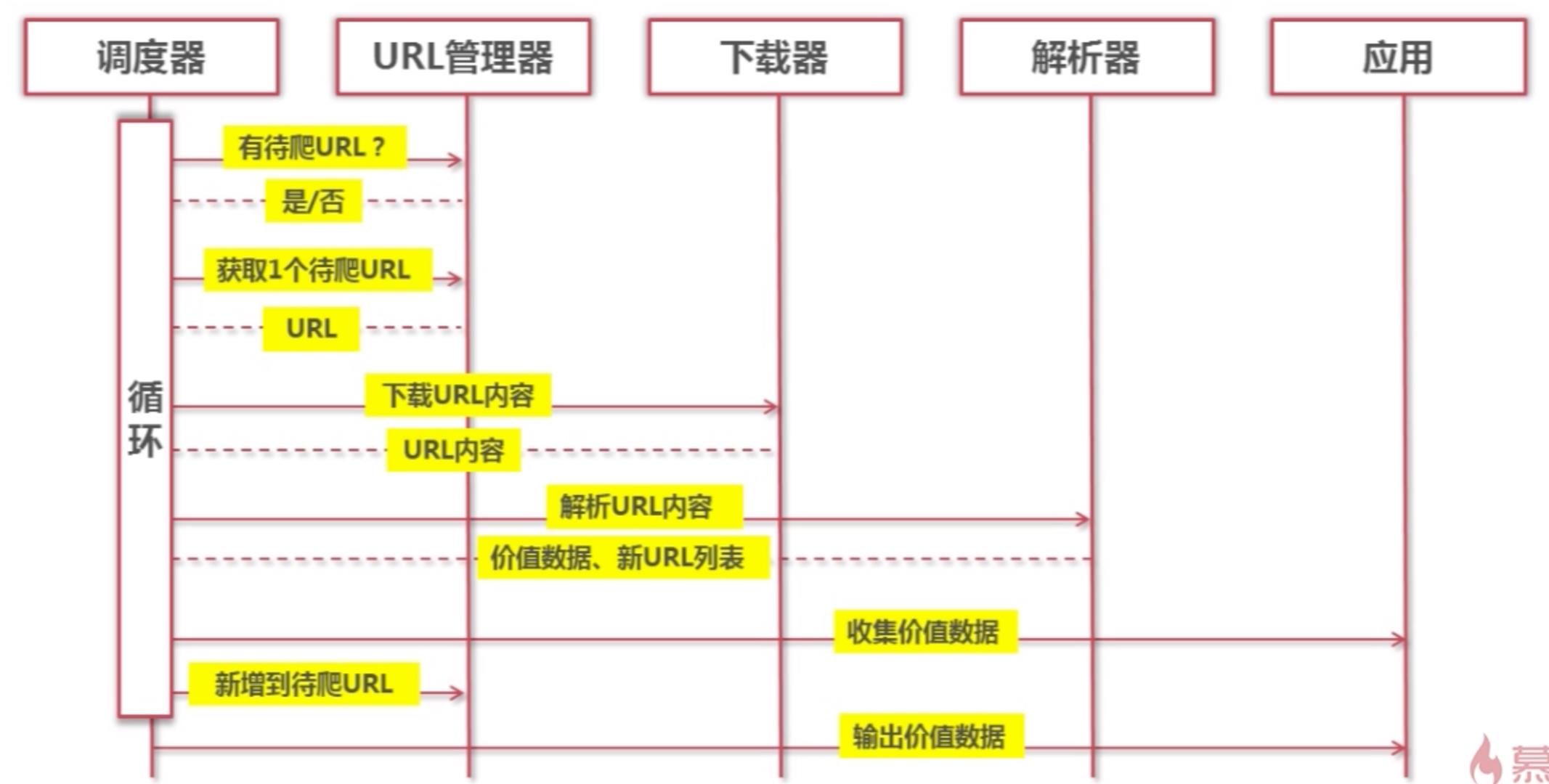
3,各部分的实现:
URL管理器:python内存
网页下载器:python3自带的urllib模块
网页解析器:使用第三方插BeautifulSoup
4,开发思路:
入口页:http://baike.baidu.com/view/21087.htm
URL格式:
词条页面URL:/view/125370.htm
数据格式:
标题:<dd class=”lemma Wgt-lemmaTitle-title”><h1>***</h1></dd>
简介:<div class=”lemma-summary”>***</div>
页面编码:UTF-8
5,开发过程:
①首先建立一个Pydev工程,新建一个web_spider库,新建一个主函数spider_main,在主函数中调用:URL管理器:url_manager,网页下载器:html_downloader,网页解析器:html_paeser.,网页输出:html_outputer来完成相应的功能
②URL管理器的建立:
新建已读取和未读取的URL集合,用来存放相应的URL地址,定义三个函数:get_new_url(self), add_new_urls(self,urls),add_new_url(self,url)来完成相应的功能
③ 网页下载器的建立:
网页下载的方法:
import urllib.request
response=urllib.request.urlopen(url)
if response.getcode()!=200:
return None
return response.read().decode(\'UTF-8\')
④网页解析器的建立:
导入BeautifulSoup模块,
创建BeautifulSoup对象,调用find方法搜索并访问节点
⑤网页输出的实现:
将抓取到的数据写入到一个HTML网页中
6,遇到的问题及解决方案:
准备工作:
一、1,BeautifulSoup下载地址:https://www.crummy.com/software/BeautifulSoup/
2.下载完成之后需要解压缩,假设放到D:/python下。
3.运行cmd,切换到D:/python/beautifulsoup4-4.1.3/目录下(根据自己解压缩后的目录 和下载的版本号修改),
4.运行命令:
setup.py build
setup.py install
5.在IDE下from bs4 import BeautifulSoup,没有报错说明安装成功。
二、在ecplise中安装PyDev插件后却无法建立项目,后来发现是没有配置python3的解释器,具体步骤为:在 Eclipse 菜单栏中,选择 Window > Preferences > Pydev > Interpreter - (Python/Jython),在这里配置 Python/Jython 解释器
实例代码如下:
(1)spider_main.py
# coding:utf8
from baike_spider import url_manager, html_downloader, html_outputer,\\
html_parser
class SpiderMain(object):
def __init__(self):
self.urls=url_manager.UrlManager()
self.downloader=html_downloader.HtmlDownloader()
self.parser=html_parser.HtmlParser()
self.outputer=html_outputer.HtmlOutputer()
def craw(self, root_url):
count=1
self.urls.add_new_url(root_url)
while self.urls.has_new_url():
try:
new_url=self.urls.get_new_url()
print("craw %d :%s"%(count,new_url))
html_cont=self.downloader.download(new_url)
new_urls,new_data=self.parser.parse(new_url,html_cont)
self.urls.add_new_urls(new_urls)
self.outputer.collect_data(new_data)
if count==1000:
break
count=count+1
except:
print("craw failed")
self.outputer.output_html()
if __name__=="__main__":
root_url="http://baike.baidu.com/view/21087.htm"
obj_spider=SpiderMain()
obj_spider.craw(root_url)
(2)url_manager.py
# coding:utf8
class UrlManager(object):
def __init__(self):
self.new_urls=set()
self.old_urls=set()
def has_new_url(self):
return len(self.new_urls)!=0
def get_new_url(self):
new_url=self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
def add_new_urls(self,urls):
if urls is None or len(urls)==0:
return
for url in urls:
self.add_new_url(url)
def add_new_url(self,url):
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
(3)html_downloader.py
# coding:utf8
import urllib.request
class HtmlDownloader(object):
def download(self,url):
if url is None:
return None
response=urllib.request.urlopen(url)
if response.getcode()!=200:
return None
return response.read().decode(\'UTF-8\')
(4)html_paeser.py
# coding:utf8
from bs4 import BeautifulSoup
import re
import urllib
class HtmlParser(object):
def _get_new_urls(self, page_url, soup):
new_urls=set()
links=soup.find_all(\'a\',href=re.compile(r"/view/\\d+\\.htm"))
for link in links:
new_url=link[\'href\']
new_full_url=urllib.parse.urljoin(page_url,new_url)
new_urls.add(new_full_url)
return new_urls
def _get_new_data(self, page_url, soup):
#<dd class="lemmaWgt-lemmaTitle-title"><h1>Python</h1>
res_data={}
res_data[\'url\']=page_url
title_node=soup.find(\'dd\',class_="lemmaWgt-lemmaTitle-title").find("h1")
res_data[\'title\']=title_node.get_text()
#<div class="lemma-summary" label-module="lemmaSummary">
summary_node=soup.find(\'div\',class_="lemma-summary")
res_data[\'summary\']=summary_node.get_text()
return res_data
def parse(self,page_url,html_cont):
if page_url is None or html_cont is None:
return None
soup=BeautifulSoup(html_cont,\'html.parser\',from_encoding=\'utf8\')
new_urls=self._get_new_urls(page_url,soup)
new_data=self._get_new_data(page_url,soup)
return new_urls,new_data
(5)html_outputer.py
# coding:utf8
class HtmlOutputer(object):
def __init__(self):
self.datas=[]
def collect_data(self,data):
if data is None:
return
self.datas.append(data)
def output_html(self):
fout=open("output.html",\'w\',encoding=\'utf8\')
fout.write("<html>")
fout.write("<body>")
fout.write("<table>")
for data in self.datas:
fout.write("<tr>")
fout.write("<td>%s</td>"%str(data[\'url\']))
fout.write("<td>%s</td>"%str(data[\'title\']))
fout.write("<td>%s</td>"%str(data[\'summary\']))
fout.write("</tr>")
fout.write("</table>")
fout.write("</body>")
fout.write("</html>")
fout.close()
运行结果如图:

以上是关于Python开发轻量级爬虫的主要内容,如果未能解决你的问题,请参考以下文章