Redis源码剖析 - Redis持久化之RDB
Posted Fred^_^
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis源码剖析 - Redis持久化之RDB相关的知识,希望对你有一定的参考价值。
原创作品,转载请标明:http://blog.csdn.net/xiejingfa/article/details/51553370
Redis源码剖析系列文章汇总:传送门
Redis是一个高效的内存数据库,所有的数据都存放在内存中。我们知道,内存中的信息会随着进程的退出或机器的宕机而消失。为此,Redis提供了两种持久化机制:RDB和AOF。这两种持久化方式的原理实际上就是把内存中所有数据的快照保存到磁盘文件上,以避免数据丢失。
今天我们主要来介绍一下RDB持久化机制RDB的实现原理,涉及的文件为rdb.h和rdb.c。
RDB的主要原理就是在某个时间点把内存中所有数据保存到磁盘文件中,这个过程既可以通过人工输入命令执行,也可以让服务器周期性执行。对于“把内存中的数据转存到磁盘中”这一过程,其实现无非就是通过定义好某种存储协议,然后按照该协议写入或读出。但要真正实现将Redis中的数据存储到磁盘上,还要考虑到以下几个问题:
- 如何落地存储协议?也就是如何设计一个存储协议可以兼容Redis丰富的数据类型(string、hash、list、set、zset)。
- 如何进行数据压缩?通常一个Redis服务器存放了大量数据,如果要将这些数据转存到文件中,如何进行数据压缩,也就是如何尽可能减少文件大小以减轻系统IO压力和节省磁盘空间。
- 如何解决数据转存时服务器阻塞问题?Redis是单线程的,当服务器在进行数据转存操作时就无法对外服务,如何避免这个问题?
(上面只是我觉得比较关键的几个问题,并不是说解决好这三个问题就可以了)
1、初识RDB
我们先通过一个例子直观地感受一下RDB文件。
先在Redis客户端中执行以下命令,存入一些数据:
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> set mystr "this is redis"
OK
127.0.0.1:6379> hset myhash name xiejingfa
(integer) 1
127.0.0.1:6379> lpush mylist one two three
(integer) 3
127.0.0.1:6379> sadd myset hello world
(integer) 2
127.0.0.1:6379> zadd myzset 1 a 2 b 3 c 4 d
(integer) 4Redis提供了save和bgsave两个命令来生成RDB文件(即将内存数据写入RDB文件中),关于这两个命令的区别我们下面会分析。现在我们在客户端中输入save命令:
127.0.0.1:6379> save
OK执行成功后我们在磁盘中找到该RDB文件(dump.rdb),该文件存放的内容如下:
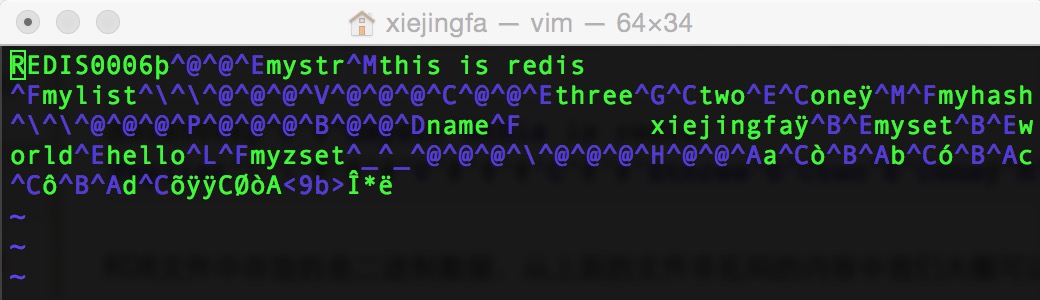
RDB文件中存放的是二进制数据,从上面的文件非乱码的内容中我们大概可以看出里面存放的各个类型的数据信息。下面我们就来介绍一下RDB的文件格式。
2、RDB文件格式
这里我画了一个图,大致展示了RDB文件的格式。如下:
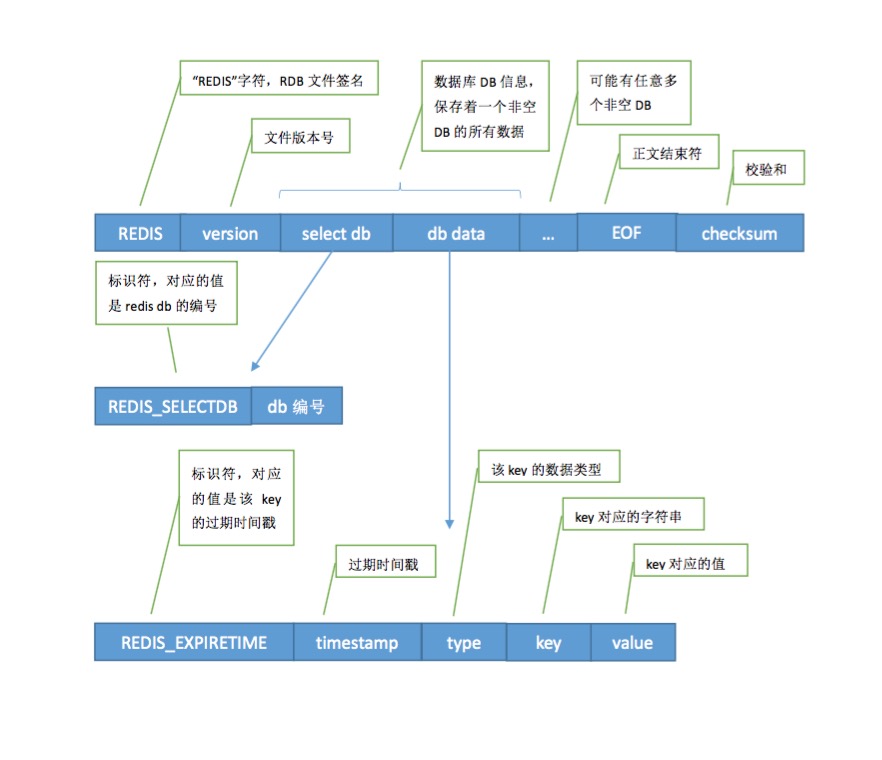
下面具体来介绍一下各部分的含义:
2.1、REDIS域
文件最开头部分是“REDIS”五个字符,为RDB文件的文件签名。在加载RDB文件时只要判断前五个字符就可以知道该文件是否为RDB文件。
2.2、version域
RDB文件的版本号。目前的版本号为6,定义在rdb.h头文件中:
#define REDIS_RDB_VERSION 62.3、select db域
该域包含两部分内容:REDIS_SELECTDB标识符和db编号。
在前面的文章中我们介绍过,当redis 服务器初始化时,会预先分配 16 个数据库。这里我们需要将非空的数据库信息保存在RDB文件中。
REDIS_SELECTDB标识符定义在rdb.h文件中,其值为254:
#define REDIS_RDB_OPCODE_SELECTDB 254db编号即对应的数据库编号,每个db编号后边到下一个REDIS_SELECTDB标识符出现之前的所有数据都是该db下的数据。在REDIS加载 RDB 文件时,会根据这个域的值切换到相应的数据库,以确保数据被还原到正确的数据库中去。
这里还有一点需要指出的是:为了尽量压缩RDB文件,Redis会对长度信息进行编码,这点我们下面会详细分析。
2.4、db data域
该域保存了某个数据库DB下面的所有键值对信息。这里可能包含任意多个键值对(key-value),对于每个键值对(key-value),主要有以下域:
(1)、REDIS_EXPIRETIME标识域
该域和后面的timestamp域是可选的。如果一个key设置了过期时间,那么在该key与value的前面会有一个REDIS_EXPIRETIME标识符与相应的timestamp值。
REDIS_EXPIRETIME标识符定义在rdb.h文件中,其值为252:
#define REDIS_RDB_OPCODE_EXPIRETIME_MS 252(2)、timestamp域
timestamp域对应的值是以毫秒为单位的过期时间戳。
(3)、type域
type域指明了数据类型,目前Redis主要有以下数据类型:
#define REDIS_RDB_TYPE_STRING 0
#define REDIS_RDB_TYPE_LIST 1
#define REDIS_RDB_TYPE_SET 2
#define REDIS_RDB_TYPE_ZSET 3
#define REDIS_RDB_TYPE_HASH 4
/* Object types for encoded objects. */
#define REDIS_RDB_TYPE_HASH_ZIPMAP 9
#define REDIS_RDB_TYPE_LIST_ZIPLIST 10
#define REDIS_RDB_TYPE_SET_INTSET 11
#define REDIS_RDB_TYPE_ZSET_ZIPLIST 12
#define REDIS_RDB_TYPE_HASH_ZIPLIST 13这些信息定义在rdb.h文件中。
(4)、key域
key域保存的是一个字符串对象,它的编码方式和REDIS_RDB_TYPE_STRING类型的value域一直,我们放到下面一起讲解。
(4)、value域
该域是RDB文件格式中最复杂的部分,因为它需要保存不同类型的数据(string、hash、list、set、zset),在介绍该域之前,我们先来看看REDIS在RDB文件中是如何对长度进行编码的,然后再用独立的一小节来分别介绍一下不同数据类型的value域是如何存储的。
(5)、EOF域
标识数据库部分的结束符,定义在rdb.h文件中:
// 数据库的结尾(但不是 RDB 文件的结尾)
#define REDIS_RDB_OPCODE_EOF 255(6)、checksum域
CRC64 校验和,如果Redis未开启校验功能,则该域的值为0。
3、长度编码
在RDB文件中有很多地方需要存储长度信息,如字符串长度、list长度等等。如果使用固定的int或long类型来存储该信息,在长度值比较小的时候会造成较大的空间浪费。为了节省空间,Redis也是无所不用其极,设计了一套特殊的方法对长度进行编码后再存储。
RDB文件中的长度编码主要通过读取第一字节的最高 2 位来决定接下来如何解析长度信息,有以下四种方式:
| 编码方式 | 占用字节数 | 说明 |
|---|---|---|
| 00|000000 | 1byte | 这一字节的其余 6 位表示长度,可以保存的最大长度是 63 (包括在内) |
| 01|000000 00000000 | 2byte | 长度为 14 位,当前字节 6 位,加上下个字节 8 位 |
| 10|000000 [32 bit integer] | 5byte | 长度由随后的 32 位整数保存 |
| 11|000000 | 后跟一个特殊编码的对象。字节中的 6 位(实际上只用到两个bit)指定对象的类型,用来确定怎样读取和解析接下来的数据 |
接下来我们从源码的角度来看看长度编码的具体运用:
(对于上面这个表格,根据其作用的不同分为“普通编码方式”和“字符串编码方式”,前三种为普通编码方式,最后一种为特殊字符串编码方式。下文的内容按这里的约定讲解)
3.1、普通编码方式
对于上表格中前三种编码,rdb.h中分别用以下宏表示:
#define REDIS_RDB_6BITLEN 0
#define REDIS_RDB_14BITLEN 1
#define REDIS_RDB_32BITLEN 2对于一个给定长度len,根据其数值大小选择相应的编码方式进行编码:
- 如果 len < (1<<6),则使用REDIS_RDB_6BITLEN方式编码
- 如果 len >= (1<<6)且len < (1<<14),则使用REDIS_RDB_14BITLEN方式编码
- 如果len >= (1<<14) 且可以用32位整数表示,则使用REDIS_RDB_32BITLEN编码
由rdbSaveLen函数负责将长度len写入RDB文件中。
/* 对 len 进行特殊编码之后写入到 rdb 。写入成功返回保存编码后的 len 所需的字节数。*/
int rdbSaveLen(rio *rdb, uint32_t len) {
unsigned char buf[2];
size_t nwritten;
if (len < (1<<6)) {
/* Save a 6 bit len */
buf[0] = (len&0xFF)|(REDIS_RDB_6BITLEN<<6);
if (rdbWriteRaw(rdb,buf,1) == -1) return -1;
nwritten = 1;
} else if (len < (1<<14)) {
/* Save a 14 bit len */
buf[0] = ((len>>8)&0xFF)|(REDIS_RDB_14BITLEN<<6);
buf[1] = len&0xFF;
if (rdbWriteRaw(rdb,buf,2) == -1) return -1;
nwritten = 2;
} else {
/* Save a 32 bit len */
buf[0] = (REDIS_RDB_32BITLEN<<6);
if (rdbWriteRaw(rdb,buf,1) == -1) return -1;
len = htonl(len);
if (rdbWriteRaw(rdb,&len,4) == -1) return -1;
nwritten = 1+4;
}
return nwritten;
}3.2、字符串编码方式
当对象是一个字符串对象时,最高两位之后的两个位(第 3 个位和第 4 个位)指定了对象的特殊编码。rdb.h中分别用以下宏表示这些特殊的编码方式:
#define REDIS_RDB_ENC_INT8 0 /* 8 bit signed integer */
#define REDIS_RDB_ENC_INT16 1 /* 16 bit signed integer */
#define REDIS_RDB_ENC_INT32 2 /* 32 bit signed integer */
#define REDIS_RDB_ENC_LZF 3 /* string compressed with FASTLZ */具体来说主要在以下两种情况下需要进行特殊编码:
3.2.1、字符串转换为整数进行存储
那些保存像是 “2391” 、 “-100” 这样的字符串的字符串对象,可以将它们的值保存到 8 位、16 位或 32 位的带符号整数值中, 从而节省一些内存。
这一过程主要由rdbTryIntegerEncoding函数实现:
int rdbTryIntegerEncoding(char *s, size_t len, unsigned char *enc) {
long long value;
char *endptr, buf[32];
/* Check if it's possible to encode this value as a number */
// 判断是否可以将字符串对象s转换为整型数值
value = strtoll(s, &endptr, 10);
// 转换失败,返回0
if (endptr[0] != '\\0') return 0;
// 将转换后的整型转换为字符串对象
ll2string(buf,32,value);
/* If the number converted back into a string is not identical
* then it's not possible to encode the string as integer */
// 如果装换后的整数值不能还远回原来的字符串,则转换失败,返回0
if (strlen(buf) != len || memcmp(buf,s,len)) return 0;
// 经过上面的检查后发现可以转换,则对转换后得到的整型数值进行编码
return rdbEncodeInteger(value,enc);
}该函数最后调用的rdbEncodeInteger函数是真正完成特殊编码的地方,定义如下:
int rdbEncodeInteger(long long value, unsigned char *enc) {
// REDIS_RDB_ENC_INT8编码
if (value >= -(1<<7) && value <= (1<<7)-1) {
enc[0] = (REDIS_RDB_ENCVAL<<6)|REDIS_RDB_ENC_INT8;
enc[1] = value&0xFF;
return 2;
}
// REDIS_RDB_ENC_INT16编码
else if (value >= -(1<<15) && value <= (1<<15)-1) {
enc[0] = (REDIS_RDB_ENCVAL<<6)|REDIS_RDB_ENC_INT16;
enc[1] = value&0xFF;
enc[2] = (value>>8)&0xFF;
return 3;
}
// REDIS_RDB_ENC_INT32编码
else if (value >= -((long long)1<<31) && value <= ((long long)1<<31)-1) {
enc[0] = (REDIS_RDB_ENCVAL<<6)|REDIS_RDB_ENC_INT32;
enc[1] = value&0xFF;
enc[2] = (value>>8)&0xFF;
enc[3] = (value>>16)&0xFF;
enc[4] = (value>>24)&0xFF;
return 5;
} else {
return 0;
}
}3.2.2、使用lzf算法进行字符串压缩
当Redis开启了字符串压缩的功能后,如果一个字符串的长度超过20bytes,Redis会使用lzf算法对其进行压缩后再存储。
压缩后的存储结构为:

该功能由rdbSaveLzfStringObject函数完成:
int rdbSaveLzfStringObject(rio *rdb, unsigned char *s, size_t len) {
size_t comprlen, outlen;
unsigned char byte;
int n, nwritten = 0;
void *out;
/* We require at least four bytes compression for this to be worth it */
// 字符串s至少超过4个字节才值得压缩
if (len <= 4) return 0;
outlen = len-4;
// 内存不足,返回0
if ((out = zmalloc(outlen+1)) == NULL) return 0;
// 使用lzf算法进行字符串压缩
comprlen = lzf_compress(s, len, out, outlen);
// 压缩失败,释放空间后返回0
if (comprlen == 0) {
zfree(out);
return 0;
}
/* Data compressed! Let's save it on disk */
/* 经过上面的操作得到压缩后的字符串,现在讲其保存在RDB文件中。*/
// 写入类型信息,指明这是一个使用lzf压缩后得到的字符串
byte = (REDIS_RDB_ENCVAL<<6)|REDIS_RDB_ENC_LZF;
if ((n = rdbWriteRaw(rdb,&byte,1)) == -1) goto writeerr;
// 记录写入的字节数
nwritten += n;
// 写入压缩后的字符串长度
if ((n = rdbSaveLen(rdb,comprlen)) == -1) goto writeerr;
// 记录写入的字节数
nwritten += n;
// 写入字符串压缩前的原始长度
if ((n = rdbSaveLen(rdb,len)) == -1) goto writeerr;
// 记录写入的字节数
nwritten += n;
// 写入压缩后的字符串
if ((n = rdbWriteRaw(rdb,out,comprlen)) == -1) goto writeerr;
// 记录写入的字节数
nwritten += n;
zfree(out);
// 返回写入的字节数
return nwritten;
writeerr:
zfree(out);
return -1;
}4、value域
介绍完长度编码后,我们就可以来介绍不同数据类型的value域是如何存储的。
4.1、string类型对象
字符串类型对象的存储结构是RDB文件中最基础的存储结构,其它数据类型的存储大多建立在字符串对象存储的基础上。注意理解!
字符串对象有两种编码方式:REDIS_ENCODING_INT和REDIS_ENCODING_RAW。
4.1.1、REDIS_ENCODING_INT编码的字符串
对于REDIS_ENCODING_INT编码的字符串对象,有以下两种保存方式:
- 如果该字符串可以用 8 bit、 16 bit或 32 bit长的有符号整型数值表示,那么就直接以整型数保存;
- 如果32bit的整数无法表示该字符串,则该字符串是一个long long类型的数,这种情况下将其转化为字符串后存储。
对于第一种方式,value域就是一个整型数值;对于第二种方式,value域的结构为:

其中length域存放字符串的长度,content域存放字符序列。
REDIS_ENCODING_INT编码的字符串对象主要由rdbSaveLongLongAsStringObject函数负责处理:
int rdbSaveLongLongAsStringObject(rio *rdb, long long value) {
unsigned char buf[32];
int n, nwritten = 0;
// 尝试以节省空间的方式编码整数值 value
int enclen = rdbEncodeInteger(value,buf);
// 编码成功,直接写入编码后的缓存
// 比如,值 1 可以编码为 11 00 0001
if (enclen > 0) {
return rdbWriteRaw(rdb,buf,enclen);
// 编码失败,将整数值转换成对应的字符串来保存
} else {
/* Encode as string */
// 转换成字符串表示
enclen = ll2string((char*)buf,32,value);
redisAssert(enclen < 32);
// 写入字符串长度
if ((n = rdbSaveLen(rdb,enclen)) == -1) return -1;
nwritten += n;
// 写入字符串
if ((n = rdbWriteRaw(rdb,buf,enclen)) == -1) return -1;
nwritten += n;
}
// 返回长度
return nwritten;
}4.1.2、REDIS_ENCODING_RAW编码的字符串
对于REDIS_ENCODING_RAW编码的字符串对象,有以下三种保存方式:
- 如果该字符串可以用 8 bit、 16 bit或 32 bit长的有符号整型数值表示,那么就将字符串转换为整型数存储以节省空间;
- 如果服务器开启了字符串压缩功能,且该字符串的长度大于20bytes,则使用lzf算法对字符串压缩后进行存储;
- 如果不满足上面两个条件,Redis只能以普通字符序列的方式来保存该字符串字符串对象。
对于前面两种方式,我们在第3小节《长度编码》中已经详细介绍过,这里就不重复讲述。
对于第三种方式,Redis以普通字符序列的方式来保存字符串对象,value域的存储结构为:

其中length域存放字符串的长度,content域存放字符串本身。
REDIS_ENCODING_RAW编码的字符串对象主要由rdbSaveRawString函数负责处理:
int rdbSaveRawString(rio *rdb, unsigned char *s, size_t len) {
int enclen;
int n, nwritten = 0;
/* Try integer encoding
*
* 尝试进行整数值编码
*/
if (len <= 11) {
unsigned char buf[5];
if ((enclen = rdbTryIntegerEncoding((char*)s,len,buf)) > 0) {
// 整数转换成功,写入
if (rdbWriteRaw(rdb,buf,enclen) == -1) return -1;
// 返回字节数
return enclen;
}
}
/* Try LZF compression - under 20 bytes it's unable to compress even
* aaaaaaaaaaaaaaaaaa so skip it
*
* 如果字符串长度大于 20 ,并且服务器开启了 LZF 压缩,
* 那么在保存字符串到数据库之前,先对字符串进行 LZF 压缩。
*/
if (server.rdb_compression && len > 20) {
// 尝试压缩
n = rdbSaveLzfStringObject(rdb,s,len);
if (n == -1) return -1;
if (n > 0) return n;
/* Return value of 0 means data can't be compressed, save the old way */
}
// 执行到这里,说明值 s 既不能编码为整数
// 也不能被压缩
// 那么直接将它写入到 rdb 中
/* Store verbatim */
// 写入长度
if ((n = rdbSaveLen(rdb,len)) == -1) return -1;
nwritten += n;
// 写入内容
if (len > 0) {
if (rdbWriteRaw(rdb,s,len) == -1) return -1;
nwritten += len;
}
return nwritten;
}4.2、hash类型对象
hash类型对象也有两种编码方式:REDIS_ENCODING_ZIPLIST和REDIS_ENCODING_HT。
4.2.1、REDIS_ENCODING_ZIPLIST编码的hash类型对象
对于REDIS_ENCODING_ZIPLIST编码的hash类型,Redis将其当做一个字符串对象(具体见《4.1、string类型对象》小节)的形式进行保存,具体由rdbSaveObject函数实现:
int rdbSaveObject(rio *rdb, robj *o) {
...
// 处理REDIS_ENCODING_ZIPLIST编码的hash
if (o->encoding == REDIS_ENCODING_ZIPLIST) {
// 计算ziplist所占用空间大小
size_t l = ziplistBlobLen((unsigned char*)o->ptr);
// ziplist本身是一个字符数组,这里以字符串的形式保存整个ziplist
if ((n = rdbSaveRawString(rdb,o->ptr,l)) == -1) return -1;
nwritten += n;
}
...
}4.2.2、REDIS_ENCODING_HT编码的hash类型对象
对于REDIS_ENCODING_HT编码的hash类型对象,在RDB文件中按下面的结构存储:

其中size域记录了字典dict中键值对的数量,每个键值对的key值和value值都以字符串对象的形式((具体见《4.1、string类型对象》小节))相邻存储。
该过程由rdbSaveObject函数实现:
int rdbSaveObject(rio *rdb, robj *o) {
...
// 处理REDIS_ENCODING_HT编码的hash
else if (o->encoding == REDIS_ENCODING_HT) {
dictIterator *di = dictGetIterator(o->ptr);
dictEntry *de;
// 保存字典dict的节点个数
if ((n = rdbSaveLen(rdb,dictSize((dict*)o->ptr))) == -1) return -1;
nwritten += n;
// 遍历字典dict的每一个节点
while((de = dictNext(di)) != NULL) {
// 获取当前节点(键值对)的key值和value值
robj *key = dictGetKey(de);
robj *val = dictGetVal(de);
// 以字符串的形式保存key值和value值
if ((n = rdbSaveStringObject(rdb,key)) == -1) return -1;
nwritten += n;
if ((n = rdbSaveStringObject(rdb,val)) == -1) return -1;
nwritten += n;
}
dictReleaseIterator(di);
}
...
}4.3、list类型对象
hash类型对象也有两种编码方式:REDIS_ENCODING_ZIPLIST和REDIS_ENCODING_LINKEDLIST。
4.3.1、REDIS_ENCODING_ZIPLIST编码的list类型对象
对于REDIS_ENCODING_ZIPLIST编码的list类型,其存储方式和REDIS_ENCODING_ZIPLIST编码的hash类型一致。
4.3.2、REDIS_ENCODING_LINKEDLIST编码的list类型对象
对于REDIS_ENCODING_LINKEDLIST编码的list类型对象,在RDB文件中按下面的结构存储:
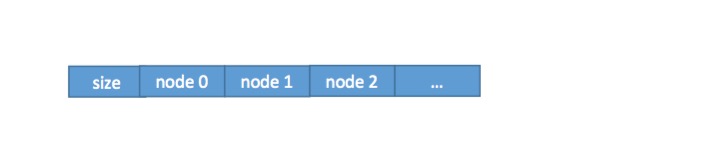
其中size域记录了链表中键值对的数量,每个节点以字符串对象((具体见《4.1、string类型对象》小节))的形式逐一存储。
该过程由rdbSaveObject函数实现:
int rdbSaveObject(rio *rdb, robj *o) {
...
// 处理REDIS_ENCODING_LINKEDLIST编码的list
else if (o->encoding == REDIS_ENCODING_LINKEDLIST) {
list *list = o->ptr;
listIter li;
listNode *ln;
// 写入长度信息(节点个数)
if ((n = rdbSaveLen(rdb,listLength(list))) == -1) return -1;
nwritten += n;
listRewind(list,&li);
// 遍历list中的每一项
while((ln = listNext(&li))) {
// 获取当前节点中的保存的数据内容
robj *eleobj = listNodeValue(ln);
// 以字符串的形式保存当前节点的内容
if ((n = rdbSaveStringObject(rdb,eleobj)) == -1) return -1;
nwritten += n;
}
}
...
}4.4、set类型对象
set类型对象也有两种编码方式:REDIS_ENCODING_HT和REDIS_ENCODING_INTSET。
4.4.1、REDIS_ENCODING_HT编码的set类型对象
对于REDIS_ENCODING_HT编码的set类型,其底层使用字典dict结构进行存储,只是该字典的value值为NULL,所以只需要存储每个键值对的key值即可。set类型在RDB文件中的存储结构如下:
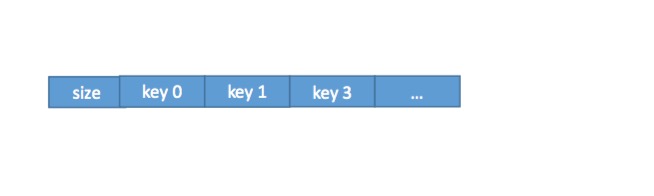
其中size域记录了集合set中元素个数,每个元素以字符串对象(具体见《4.1、string类型对象》小节)的形式逐一存储。
该过程由rdbSaveObject函数实现:
int rdbSaveObject(rio *rdb, robj *o) {
...
// 处理REDIS_ENCODING_HT编码的set
if (o->encoding == REDIS_ENCODING_HT) {
dict *set = o->ptr;
dictIterator *di = dictGetIterator(set);
dictEntry *de;
// 写入长度信息
if ((n = rdbSaveLen(rdb,dictSize(set))) == -1) return -1;
nwritten += n;
// 遍历字典dict的每个成员
while((de = dictNext(di)) != NULL) {
// 获取当前节点的key值
robj *eleobj = dictGetKey(de);
// 以字符串的形式保存当前节点的key
if ((n = rdbSaveStringObject(rdb,eleobj)) == -1) return -1;
nwritten += n;
}
dictReleaseIterator(di);
}
...
}4.4.2、REDIS_ENCODING_INTSET编码的set类型对象
对于REDIS_ENCODING_INTSET编码的set类型,Redis将其当做一个字符串对象(具体见《4.1、string类型对象》小节)的形式进行保存,具体由rdbSaveObject函数实现:
int rdbSaveObject(rio *rdb, robj *o) {
...
// 处理REDIS_ENCODING_INTSET编码的set
else if (o->encoding == REDIS_ENCODING_INTSET) {
// 计算inset所占用空间大小
size_t l = intsetBlobLen((intset*)o->ptr);
// inset本身是一个字符数组,这里以字符串的形式保存整个inset
if ((n = rdbSaveRawString(rdb,o->ptr,l)) == -1) return -1;
nwritten += n;
}
...
}4.5、zset类型对象
zset类型对象也有两种编码方式:REDIS_ENCODING_ZIPLIST和REDIS_ENCODING_SKIPLIST。
4.5.1、REDIS_ENCODING_ZIPLIST编码的zset类型对象
对于REDIS_ENCODING_ZIPLIST编码的zset类型,Redis将其当做一个字符串对象(具体见《4.1、string类型对象》小节)的形式进行保存。具体由rdbSaveObject函数实现:
int rdbSaveObject(rio *rdb, robj *o) {
...
// 处理REDIS_ENCODING_ZIPLIST编码的zset
if (o->encoding == REDIS_ENCODING_ZIPLIST) {
// 计算ziplist所占用空间大小
size_t l = ziplistBlobLen((unsigned char*)o->ptr);
// ziplist本身是一个字符数组,这里以字符串的形式保存整个ziplist
if ((n = rdbSaveRawString(rdb,o->ptr,l)) == -1) return -1;
nwritten += n;
}
...
}4.5.2、REDIS_ENCODING_SKIPLIST编码的zset类型对象
对于REDIS_ENCODING_SKIPLIST编码的zset类型,在RDB文件中的存储结构如下:

其中size域记录了有序结合zset中元素个数,随后逐一存储每一个元素。对于其中一个元素,先存储其元素值value再存储其分值score。zset的元素值是一个字符串对象,按字符串形式存储,分值是一个double类型的数值,Redis先将其转换为字符串对象再存储。具体由函数实现:
int rdbSaveObject(rio *rdb, robj *o) {
...
// 处理REDIS_ENCODING_SKIPLIST编码的zset
else if (o->encoding == REDIS_ENCODING_SKIPLIST) {
zset *zs = o->ptr;
dictIterator *di = dictGetIterator(zs->dict);
dictEntry *de;
// 保存字典dict的节点个数
if ((n = rdbSaveLen(rdb,dictSize(zs->dict))) == -1) return -1;
nwritten += n;
// 遍历字典dict的每一个节点
while((de = dictNext(di)) != NULL) {
// 获取当前节点(键值对)的key值
robj *eleobj = dictGetKey(de);
// 获取分值score值
double *score = dictGetVal(de);
// 以字符串的形式保存key值
if ((n = rdbSaveStringObject(rdb,eleobj)) == -1) return -1;
nwritten += n;
// 保存分值score
if ((n = rdbSaveDoubleValue(rdb,*score)) == -1) return -1;
nwritten += n;
}
// 释放迭代器
dictReleaseIterator(di);
}
...
}5、RDB的实现原理
前面我们介绍过Redis提供了save和bgsave两个命令来生成RDB文件。下面我们来看看这两者的具体实现。
5.1、save命令
save是在Redis进程中执行的,由于Redis是单线程实现,所以当save命令在执行时会阻塞Redis服务器一直到该命令执行完成为止。
save命令的功能由rdbSave函数实现:
/* Save the DB on disk. Return REDIS_ERR on error, REDIS_OK on success. */
/* save命令的底层函数。将Redis数据库db保存到磁盘中,如果操作成功函数返回REDIS_OK,如果操作失败函数返回REDIS_ERR。*/
int rdbSave(char *filename) {
char tmpfile[256];
FILE *fp;
rio rdb;
int error;
// 生成临时文件名称
snprintf(tmpfile,256,"temp-%d.rdb", (int) getpid());
// 创建临时文件
fp = fopen(tmpfile,"w");
if (!fp) {
redisLog(REDIS_WARNING, "Failed opening .rdb for saving: %s",
strerror(errno));
return REDIS_ERR;
}
// 初始化file rio对象
rioInitWithFile(&rdb,fp);
// 调用rdbSaveRio将db中的数据写入RDB文件中
if (rdbSaveRio(&rdb,&error) == REDIS_ERR) {
errno = error;
goto werr;
}
/* Make sure data will not remain on the OS's output buffers */
// flush操作,确保所有数据都写入RDB文件中
if (fflush(fp) == EOF) goto werr;
if (fsync(fileno(fp)) == -1) goto werr;
if (fclose(fp) == EOF) goto werr;
/* Use RENAME to make sure the DB file is changed atomically only
* if the generate DB file is ok. */
// 重命名临时文件
if (rename(tmpfile,filename) == -1) {
// 如果操作失败,删除临时文件
redisLog(REDIS_WARNING,"Error moving temp DB file on the final destination: %s", strerror(errno));
unlink(tmpfile);
return REDIS_ERR;
}
redisLog(REDIS_NOTICE,"DB saved on disk");
server.dirty = 0;
server.lastsave = time(NULL);
server.lastbgsave_status = REDIS_OK;
return REDIS_OK;
werr:
// 发生错误清理资源
redisLog(REDIS_WARNING,"Write error saving DB on disk: %s", strerror(errno));
fclose(fp);
unlink(tmpfile);
return REDIS_ERR;
}rdbSave函数内部又通过条用rdbSaveRio函数来完成真正的转存操作。
int rdbSaveRio(rio *rdb, int *error) {
dictIterator *di = NULL;
dictEntry *de;
char magic[10];
int j;
long long now = mstime();
uint64_t cksum;
// 设置校验和函数,rioGenericUpdateChecksum定义在rio.h文件中
if (server.rdb_checksum)
rdb->update_cksum = rioGenericUpdateChecksum;
// 生成RDB文件版本号
snprintf(magic,sizeof(magic),"REDIS%04d",REDIS_RDB_VERSION);
// 写入RDB版本号
if (rdbWriteRaw(rdb,magic,9) == -1) goto werr;
// 遍历Redis服务器上的所有数据库
for (j = 0; j < server.dbnum; j++) {
// 获取当前数据库
redisDb *db = server.db+j;
// 获取当前数据库的键空间key space
dict *d = db->dict;
// 如果当前数据库为空,跳过
if (dictSize(d) == 0) continue;
di = dictGetSafeIterator(d);
if (!di) return REDIS_ERR;
/* Write the SELECT DB opcode */
// 写入数据库DB的编号,即 j
if (rdbSaveType(rdb,REDIS_RDB_OPCODE_SELECTDB) == -1) goto werr;
if (rdbSaveLen(rdb,j) == -1) goto werr;
/* Iterate this DB writing every entry */
// 遍历键空间中的每一项,并写入RDB中
while((de = dictNext(di)) != NULL) {
// 获取key和value
sds keystr = dictGetKey(de);
robj key, *o = dictGetVal(de);
long long expire;
// 创建一个key对象
initStaticStringObject(key,keystr);
// 获取key的过期信息
expire = getExpire(db,&key);
// 保存当前键值对
if (rdbSaveKeyValuePair(rdb,&key,o,expire,now) == -1) goto werr;
}
dictReleaseIterator(di);
}
di = NULL; /* So that we don't release it again on error. */
/* EOF opcode */
// 写入EOF符
if (rdbSaveType(rdb,REDIS_RDB_OPCODE_EOF) == -1) goto werr;
/* CRC64 checksum. It will be zero if checksum computation is disabled, the
* loading code skips the check in this case. */
// CRC64校验和,如果Redis校验和功能被关闭则cksum的值为0。在这种情况下当Redis载入RDB时会
// 跳过该校验和的检查
cksum = rdb->cksum;
memrev64ifbe(&cksum);
// 写入校验和
if (rioWrite(rdb,&cksum,8) == 0) goto werr;
return REDIS_OK;
werr:
if (error) *error = errno;
if (di) dictReleaseIterator(di);
return REDIS_ERR;
}5.1、bgsave命令
与save命令不同的是,bgsave命令会先fork出一个子进程,然后在子进程中生成RDB文件。由于在子进程中执行IO操作,所以bgsave命令不会阻塞Redis服务器进程,Redis服务器进程在此期间可以继续对外提供服务。
bgsave命令由rdbSaveBackground函数实现,从该函数的实现中可以看出:为了提高性能,Redis服务器在bgsave命令执行期间会拒绝执行新到来的其它bgsave命令。
int rdbSaveBackground(char *filename) {
pid_t childpid;
long long start;
// 如果 BGSAVE 已经在执行,那么出错
if (server.rdb_child_pid != -1) return REDIS_ERR;
// 记录 BGSAVE 执行前的数据库被修改次数
server.dirty_before_bgsave = server.dirty;
// 最近一次尝试执行 BGSAVE 的时间
server.lastbgsave_try = time(NULL);
// fork() 开始前的时间,记录 fork() 返回耗时用
start = ustime();
if ((childpid = fork()) == 0) {
int retval;
/* Child */
// 关闭网络连接 fd
closeListeningSockets(0);
// 设置进程的标题,方便识别
redisSetProcTitle("redis-rdb-bgsave");
// 执行保存操作
retval = rdbSave(filename);
// 打印 copy-on-write 时使用的内存数
if (retval == REDIS_OK) {
size_t private_dirty = zmalloc_get_private_dirty();
if (private_dirty) {
redisLog(REDIS_NOTICE,
"RDB: %zu MB of memory used by copy-on-write",
private_dirty/(1024*1024));
}
}
// 向父进程发送信号
exitFromChild((retval == REDIS_OK) ? 0 : 1);
} else {
/* Parent */
// 计算 fork() 执行的时间
server.stat_fork_time = ustime()-start;
// 如果 fork() 出错,那么报告错误
if (childpid == -1) {
server.lastbgsave_status = REDIS_ERR;
redisLog(REDIS_WARNING,"Can't save in background: fork: %s",
strerror(errno));
return REDIS_ERR;
}
// 打印 BGSAVE 开始的日志
redisLog(REDIS_NOTICE,"Background saving started by pid %d",childpid);
// 记录数据库开始 BGSAVE 的时间
server.rdb_save_time_start = time(NULL);
// 记录负责执行 BGSAVE 的子进程 ID
server.rdb_child_pid = childpid;
// 关闭自动 rehash
updateDictResizePolicy();
return REDIS_OK;
}
return REDIS_OK; /* unreached */
}6、触发生成RDB文件
Redis提供了一个叫save的配置选项,可以让服务器在满足某种条件的情况下执行bgsave命令生成RDB文件。我把这个功能称为“触发执行”。
我们先来看看save配置选项的介绍,在redis.conf文件中可以找到:
################################ SNAPSHOTTING ################################
#
# Save the DB on disk:
#
# save <seconds> <changes>
#
# Will save the DB if both the given number of seconds and the given
# number of write operations against the DB occurred.
#
# In the example below the behaviour 以上是关于Redis源码剖析 - Redis持久化之RDB的主要内容,如果未能解决你的问题,请参考以下文章