《ALBERT 论文解读》
Posted cx2016
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《ALBERT 论文解读》相关的知识,希望对你有一定的参考价值。
ALBERT 论文解读
NLP论文专栏里怎么可能没有关于BERT的论文呢,今天给大家介绍的就是google最近发的一个又一个秒杀各个数据集的模型ALBERT。
论文地址:
https://openreview.net/pdf?id=H1eA7AEtvSgithub地址(中文预训练模型):
brightmart/albert_zh?github.com
一、概述
最近各种大体量的预训练模型层出不穷,经常是一个出来刷榜没几天,另外一个又出现了。BERT、RoBERTa、XLNET等等都是代表人物。这些“BERT”们虽然一个比一个效果好,但是他们的体量都是非常大的,懂不懂就几千万几个亿的参数量,而且训练也非常困难。新出的ALBERT就是为了解决模型参数量大以及训练时间过长的问题。ALBERT最小的参数只有十几M, 效果要比BERT低1-2个点,最大的xxlarge也就200多M。可以看到在模型参数量上减少的还是非常明显的,但是在速度上似乎没有那么明显。最大的问题就是这种方式其实并没有减少计算量,也就是受推理时间并没有减少,训练时间的减少也有待商榷。
二、模型详解
整个模型的结构还是依照了BERT的骨架,采用了Transformer以及GELU激活函数。具体的创新部分应该有三个:一个是将embedding的参数进行了因式分解,然后就是跨层的参数共享,最后是抛弃了原来的NSP任务,现在使用SOP任务。这几个更新的细节后面会仔细再说。这三个更新前两个的主要任务就是来进行参数减少的,第三个更新这已经算不上什么更新了,之前已经有很多工作发现原来BERT中的下一句话预测这个任务并没有什么积极地影响。根据文章的实验结果来看似乎参数共享对参数降低的影响比较大,同时也会影响模型的整体效果。后面就来详细的说一下这三个改动。
- Factorized embedding parameterization
原始的BERT模型以及各种依据transformer来搞的预训练语言模型在输入的地方我们会发现它的E是等于H的,其中E就是embedding size,H就是hidden size,也就是transformer的输入输出维度。这就会导致一个问题,当我们的hidden size提升的时候,embedding size也需要提升,这就会导致我们的embedding matrix维度的提升。所以这里作者将E和H进行了解绑,具体的操作其实就是在embedding后面加入一个矩阵进行维度变换。E是永远不变的,后面H提高了后,我们在E的后面进行一个升维操作,让E达到H的维度。这使得embedding参数的维度从O(V×H)到了O(V×E + E×H), 当E远远小于H的时候更加明显。
- Cross-layer parameter sharing
之前transformer的每一层参数都是独立的,包括self-attention 和全连接,这样的话当层数增加的时候,参数就会很明显的上升。之前有工作试过单独的将self-attention或者全连接进行共享,都取得了一些效果。这里作者尝试将所有的参数进行共享,这其实就导致多层的attention其实就是一层attention的叠加。同时作者通过实验还发现了,使用参数共享可以有效地提升模型的稳定程度。实验结果如下图:
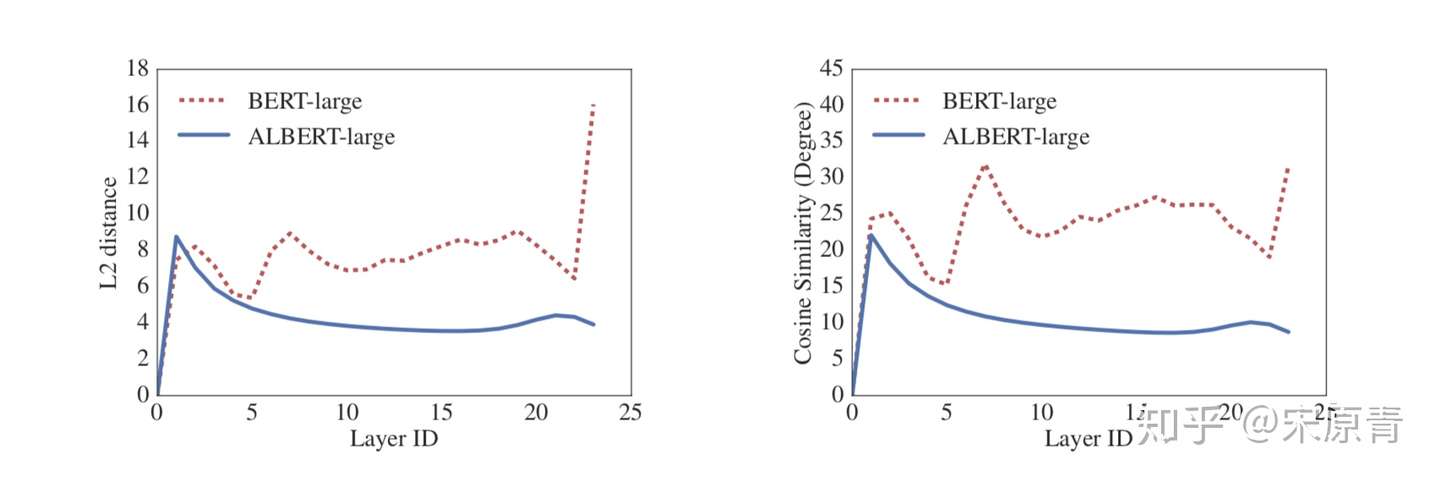
- Inter-sentence coherence loss
这里作者使用了一个新的loss,其实就是更改了原来BERT的一个子任务NSP, 原来NSP就是来预测下一个句子的,也就是一个句子是不是另一个句子的下一个句子。这个任务的问题出在训练数据上面,正例就是用的一个文档里面连续的两句话,但是负例使用的是不同文档里面的两句话。这就导致这个任务包含了主题预测在里面,而主题预测又要比两句话连续性的预测简单太多。新的方法使用了sentence-order prediction(SOP), 正例的构建和NSP是一样的,不过负例则是将两句话反过来。实验的结果也证明这种方式要比之前好很多。但是这个这里应该不是首创了,百度的ERNIE貌似也采用了一个这种的。
三、实验
作者进行了大量的对比试验对前面三个改进进行了证明,首先是模型的参数配置:
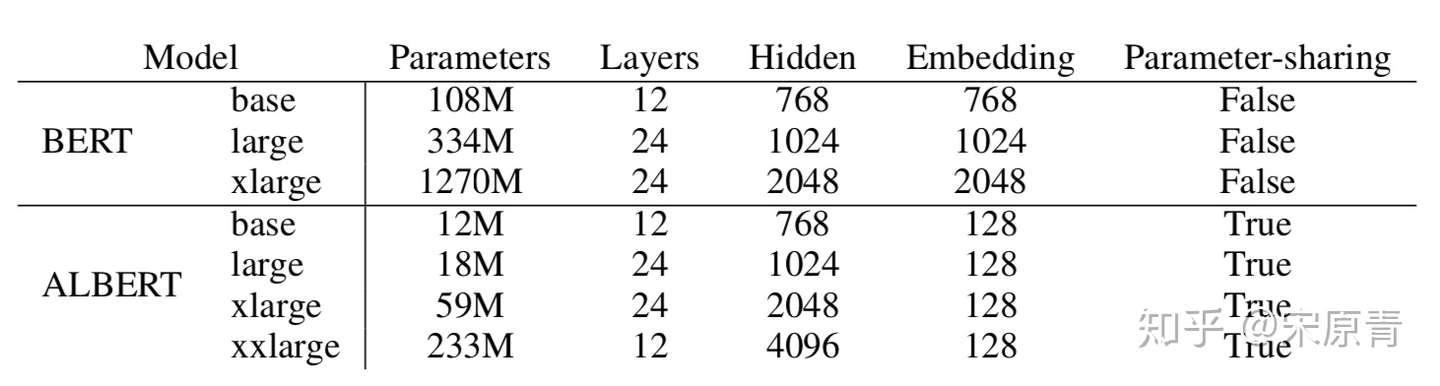
这里可以看到ALBERT的与参数的减少还是非常的显著的,同时我们也可以看出来,似乎参数共享对参数量减少的作用更大一点。
- 整体与BERT的对比
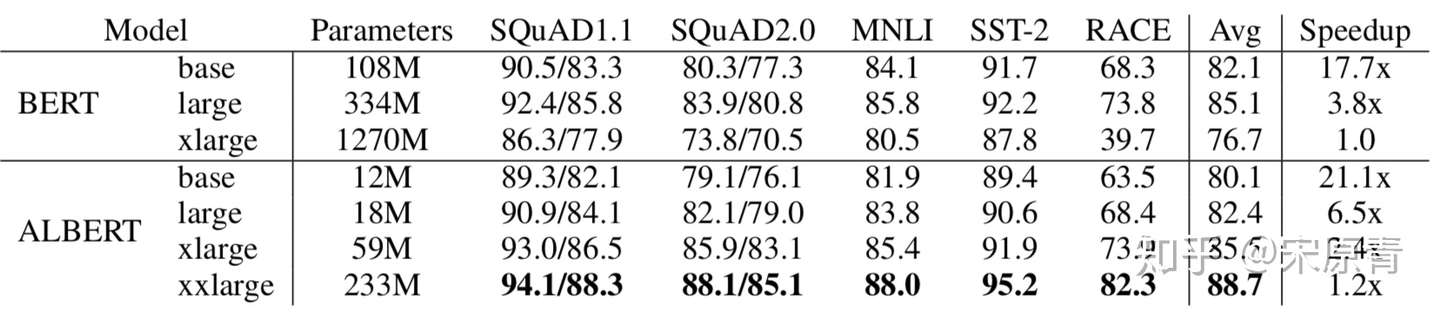
这里的比较就很有意思了,首先常规的提升我们都能看到,参数量巨大的减少以及效果的提升。但是我们可以看到ALBERT xxlarge只有233M的参数,而BERT xlarge足足有1270M的参数,但是在训练速度上之快了0.2。这个模型其实在计算效率上并没有很大的提升。
- 因式分解embedding的影响
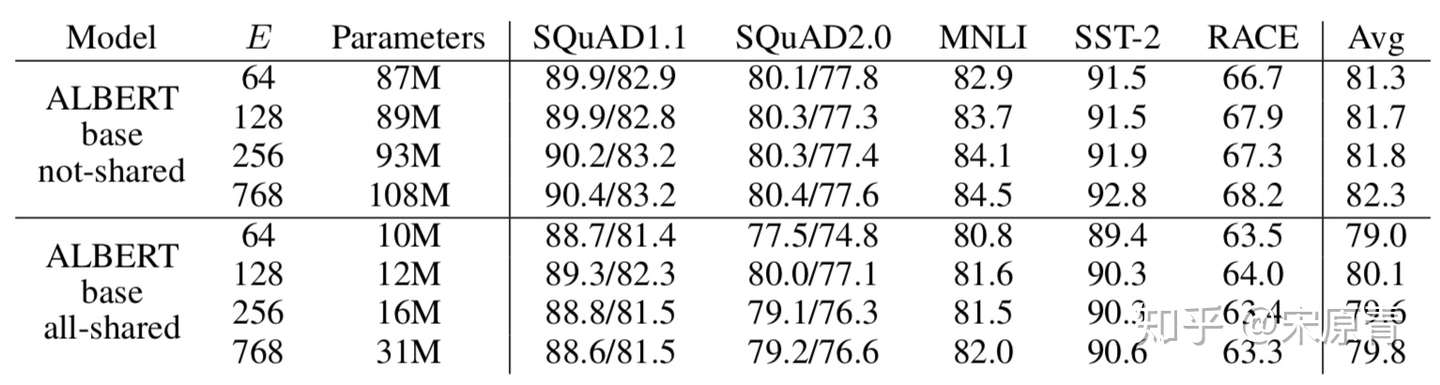
这里我们可以看到,对于参数不共享的版本,随着E的增加,效果是不断提升的。但是在参数共享的版本似乎不是这样的,效果最好的版本并不是E最大的版本。同时我们也可以发现参数共享对于效果可能带来1-2个点的下降
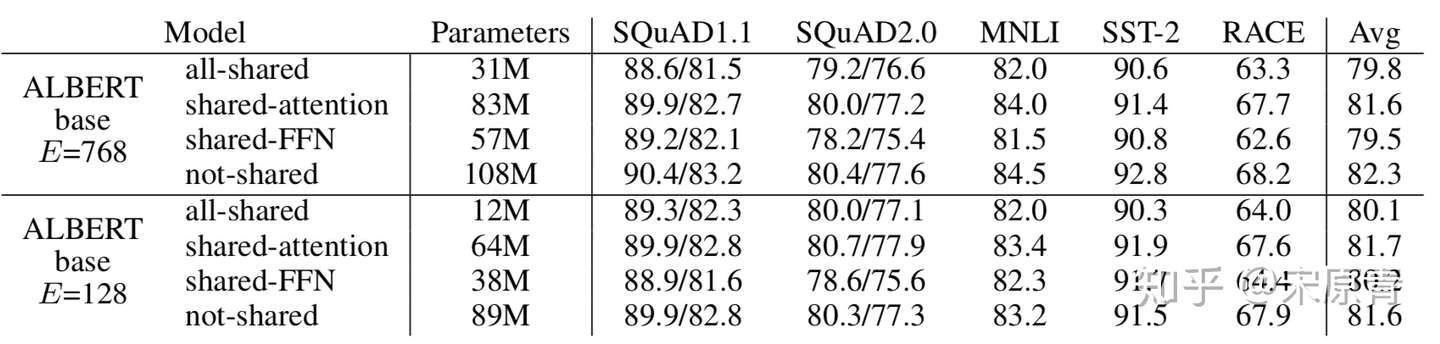
- 多层参数共享的影响
 添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
这里我们可以看到对于E=768的版本,参数不共享的效果是最好的,但是对于E=128的版本,只共享attention确实最好的。这里作者只是指出了这个情况,但是没有分析具体的原因是为啥。
- SOP任务的影响

这里可以看到SOP任务对于各个数据集效果提升还是很明显的。
- 网络深度和宽度的影响

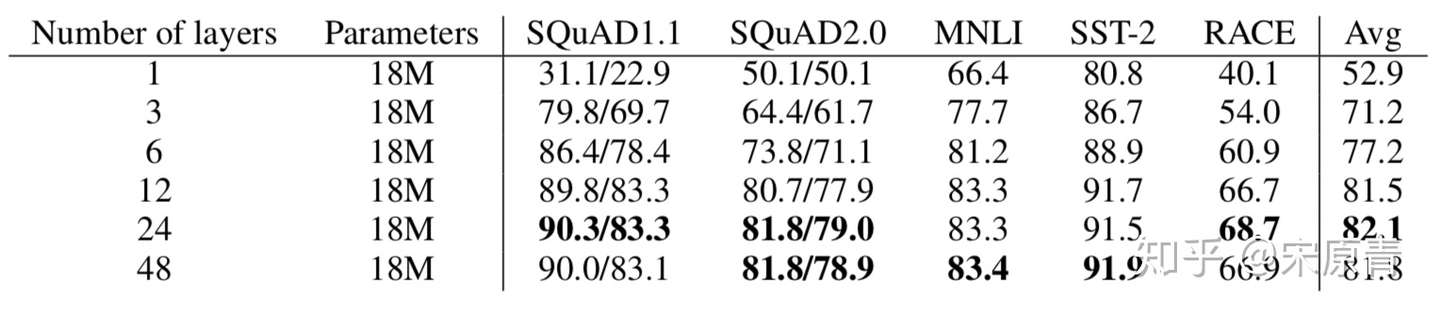
上面两个图我们可以看出来,随着网络的加深和加宽,模型效果是越来越好的。
四、结论
总体来看这个模型并没有那么的让人惊喜,虽然在各个数据及上有更好的效果而且参数量下降了。但是XXlarge版本的计算量还是非常大的,这就意味着其在训练和推理上要花更多的时间,作者也说了未来的工作就是提升模型的推理速度。
以上是关于《ALBERT 论文解读》的主要内容,如果未能解决你的问题,请参考以下文章