LipNet 论文解读
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LipNet 论文解读相关的知识,希望对你有一定的参考价值。
参考技术A 论文:LipNet:END-TO-END SENTENCE-LEVEL LIPREADING本人在对相关领域的内容进行调研时,由于缺乏指导,在中文网站上也很少见到有对Lipreading相关的文章进行详尽分析,因此也耗费了不少时间精力。这里对领域内的一篇Sentence Level的开山之作(文中自称)进行分析,介绍文章中的重点。在这篇文章之前,大多数Lipreading的工作集中在字母、单词、数字或者短语的识别上,具有一定的局限性。而这篇文章虽然使用的数据中的句式有限定,词汇量也比较小,但是不妨碍它是在语句的尺度上进行的识别,且取得了相当不错的成果。
首先介绍数据集。GRID数据集是一个Sentence-level的数据集,比较包含三万多条数据。每一个数据是一条视频,视频内容是一个人说出一条固定的句子,并对应一条文本标签,文本标签对每个单词的起始时间和终止时间都进行标注。句子的句式是进行了限制的,并不是具有逻辑性的自然语句,即:
也就是说,每一条语句都是由6个固定类型的单词组成,上标表示了数据集中这种单词类型的种类数量,比如表示这个位置为一个颜色单词(如blue),而数据集中一共有4种颜色单词。
另外需要了解的是,数据集的视频一共有34个文件夹,对应了对34个不同的人所录制的视频。每一个文件夹包含上千个视频数据,都是对同一个人录制的。而在后期实验时,作者会采用两种不同的方式进行训练和测试:(1)用其中30个人的视频进行训练,而用另外4个人的视频进行测试,即Unseen Speakers;(2)从34个人的视频中,各随机抽取255个视频作为测试数据,其它的作为训练数据;
首先会按照先前在数据集部分的末尾所介绍分组方式将数据拆分为两种训练集和测试集。然后使用已有的面部识别检测器,将视频的每一帧都处理为大小的仅包含嘴部的帧。最后再将每一帧进行标准化。
(1)分别使用常规的图像序列和水平翻转的图像序列进行训练;
(2)由于数据集提供了每一个单词的起始和终止时间,因此可以使用每一个单词所对应的图像帧序列来训练模型;
(3)随机删除或复制某些帧,概率设置为0.05;
介绍完了数据的组织方式以后,大家也都知道了这是一个Seq2seq的问题,与语音识别的套路极其相似,因此Lipreading的套路很大程度上就是将CV的套路和机器翻译的套路进行整合。
这篇文章的模型结构也没什么特别的,文中的废话比较多,总结起来其实就是用3D卷积对图像帧进行特征提取,然后使用两层双向GRU作为Encoder-Decoder,输出一个预测值,最后再用全连接层输出预测的概率。总体上模型的结构并不复杂,也有一些可以改进的地方 。
此外,损失函数函数值得注意。本文使用的是CTC损失函数,这个损失函数是一个比较经典的用于语音识别相关问题的损失函数,避免了帧与字符进行对齐标注。具体地可以参考 这篇文章 。
指标WER和CER分别为word error rate 和 character error rate,即单词错误率和字符错误率,固然是越低越好。指标分为了两栏:Unseen Speakers和 Overlapped Speakers,对应于在数据集部分介绍的两种数据划分方式下的测试结果。可以看到,LipNet在GRID数据集上的各项指标都达到了当时的最好。后续的很多工作在GRID数据集上的WER已经来到1.0%~2.0%,但是在例如LRS数据集上的表现,远无法达到GRID数据集上的效果,因为GRID数据集中的句式单一,且人脸正对着镜头,只能作为一项基础研究,Lipreading在自然场景下的sentence-level的识别,仍然有很长的路要走。
水平有限,欢迎大家批评指正。有问题可以共同探讨。
ResNet论文解读/总结
此文章为深度学习在计算机视觉领域的图片分类经典论文ResNet(Deep Residual Learning for Image Recognition)论文总结。
此系列文章是非常适合深度学习领域的小白观看的图像分类经典论文。系列文章如下:
AlexNet:AlexNet论文解读/总结_耿鬼喝椰汁的博客-CSDN博客
VGGNet:VGGNet论文解读/总结_耿鬼喝椰汁的博客-CSDN博客
GoogLeNet:GoogLeNet(Inception)v1 论文解读/总结_耿鬼喝椰汁的博客-CSDN博客
ResNet:ResNet论文解读/总结_耿鬼喝椰汁的博客-CSDN博客
文章目录
摘要
(一)通常情况下,神经网络的深度越深,越难以训练,本文提出了一种残差神经网络来解决这个问题,它的优化更简单,并且可以在深层的神经网络中也相应获得更高的准确度。这种深度残差神经网络在ImageNet等数据集的测试效果均为第一名。
(二)更深的神经网络更加难以训练,残差网络主要用来减轻训练的网络,这些网络比之前使用的网络都要深得多。
(三)在ImageNet的的数据集中网络层数达到了152层,前一年夺冠的VGG只有19层。在COCO物体检测数据集上获得了28%的相对改进。
(一)论文要解决问题
(1)论文首先说明:一味地加深网络深度会使得网络达到了一种饱和状态,而导致精度的下降。
(2)在以往的知识中,深度学习层数越深,提取的特征越多。如下图所示,并非网络层数越多越好。引起这部分的原因,这种现象主要是退化:随着网络层数的加深,准确性会达到饱和,梯度传播过程中会逐渐消失,导致无法对前面的网络层权重进行调整,训练误差加大,结果也随之变差。(并非过拟合,如果过拟合,训练的时候误差很小,但是测试的时候误差就很大)
由下图可以看出,56-layer(层)的网络比20-layer的网络在训练集和测试集上的表现都要差。注意:这里不是过拟合(过拟合是在训练集上表现得好,而在测试集中表现得很差),说明如果只是简单的增加网络深度,可能会使神经网络模型退化,进而丢失网络前面获取的特征。
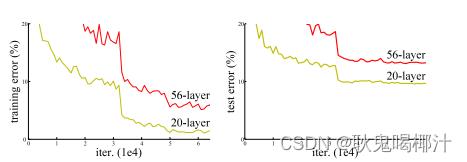
(二)解决方法
为了解决上面提到的退化,引入一个[深度残差网络].gray (理论上深层次网络和浅层的网络性能一样,但现实卷积层层数越到后面会出现退化)
残差深度学习
本文提出了深度残差学习(deep residual learning)框架来解决上图中的问题,如下图所示,通过前馈神经网络的shortcut connections来跨过一个层或者多个层,将前层的输出直接与卷积层的输出叠加,相当于做了个恒等映射。
在极端情况下,如果恒等映射最优,可以将残差设置为0就简单地实现了恒等映射。简单来说,残差学习就是将一层的输入与另一层的输出结果一起作为一整个块的输出。
整体的网络架构如下:使用两层卷积加relu激活函数,经过第一层的时候输出 F(x),之后在经过第二层(此处增加了shortcut connection),将其shortcut connection连接到第二层的激活函数之前,输出结果变为H(x)=F(x)+x(恒等映射)
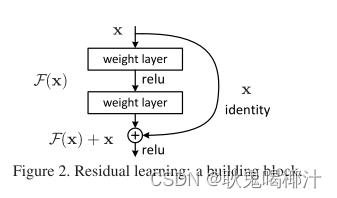
大致参数如下:浅层网络的输出为:x,要学习的目标值为H(x),那么就让该层网络学习一个残差目标值F(x) = H(x)- x,最后的输出为F(x) + x, identity 恒等映射。
残差网络作用:(1)残差网络比较容易优化,普通网络架构(简单的堆叠层)在训练的时候容易出现较高的误差。(2)残差网络随着深度的增加,准确性、精度也会提高
残差:也就是真实值和预测值的偏差,类似数据的回归,作用:(1)修正上一层的错误。(2)防止梯度消失(以往的线性结构训练,梯度都是越来越小)
残差网络的定义如下:
(1)当结构块的输入和输出一致时,恒等映射直接叠加到输出上:
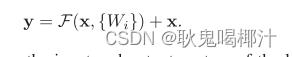
(2)当结构块的输入和输出不一致时,使用x进行线性映射之后,叠加到输出中:
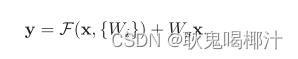
(三) 网络架构
从Vgg的启发出发,我们构建一个简单的卷积神经网络。(后两个网络以全局平均池化层和具有softmax的1000维全连接层结束。 左:作为参考的VGG-19模型。中:具有34个参数层的简单网络 。右:具有34个参数层的残差网络 。)
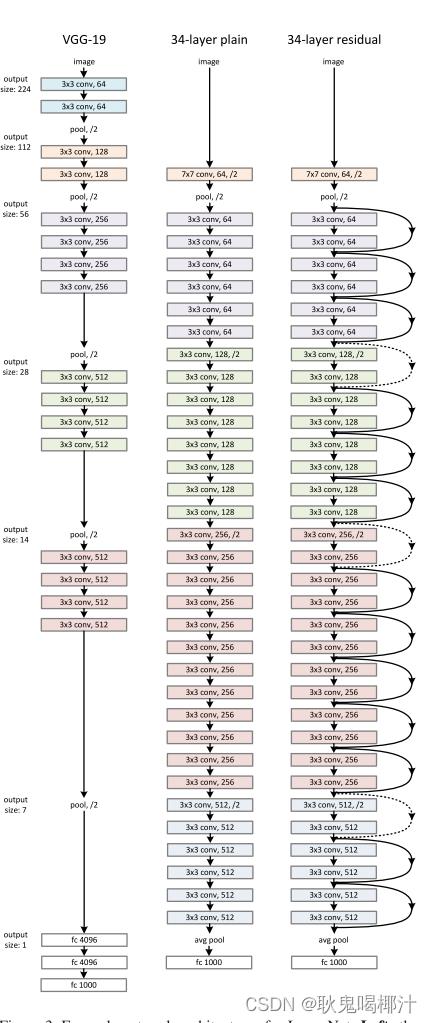
用两个设计规则设计出我们的残差网络:(1)对于相同的输出特征图尺寸,层具有相同数量的滤波器; (2) 如果特征图尺寸减半,则滤波器数量加倍,以便保持每层的时间复杂度。我们通过步长为2的卷积层直接执行下采样。
(一)VGG19的架构:(1).总共有5个block组成,所有的卷积都是3*3, block的卷积核个数以此为64、128、256、512、512 。(2)每个block之间通过下采样。 (3)特征图减半,步长加倍。(4)最后使用两个全连接层(输出1000个类别的概率).
(二)Plain Network:受VGG网络(如下图左图)的影响,plain网络(如下图中间)的卷积层主要是3*3的滤波器,加权层的层数为34,在网络的最后是全局的平均pooling层和一个1000种类的包含softmax函数的全连接层。plain网络比VGG网络有更少的滤波器(卷积核后面的64,128,256等代表个数)和更低的计算复杂度。
(三)Residual Network:在plain网络的基础上,加入shortcut连接,就变成了相应的残差网络,如上图右图所示,图中所加实线表明可以直接使用恒等shortcuts,虚线表示维度不匹配时的情况,需要先调整维度再相加。 调整维度的方法有两种: (1)仍然使用恒等映射,只是在增加的维度上使用0来填充,这种方法不会引入额外的参数; (2)使用1x1的卷积映射shortcut来调整维度保持一致。 (这两种方法都使用stride为2的卷积。)
(四)实验
下面是基于ImageNet2012数据集进行评估实验,训练集包含128万张图像,验证集包含5万张图像,测试集有10万张图像,对top-1和top-5的错误率来评估。
plain网络:
首先进行的实验是18层和34层的plain网络,实验结果如下表所示,产生了一种退化现象:在训练过程中34层的网络比18层的网络有着更高的训练错误率。

残差网络:
接着对18层和34层的残差网络进行评估,为了保证变量的一致性,其基本框架结构和plain网络的结构相同,只是在每一对卷积层上添加了shortout连接来实现残差结构,对于维度不匹配的情况,使用0来填充维度(即上面介绍过的方法),因此也并没有添加额外的参数。训练效果如下图:

结合下表验证集上的top-1错误率与前面两个表格,可以对比得到:
(1)与plain网络相反,34层的resnet网络比18层的错误率更低,表明可以通过增加深度提高准确率,解决了退化问题。
(2)与plain网络相比,层次相同的resnet网络二错误率更低,这也说明残差网络在深层次下仍然有效。
(3)对于18层的plain网络,它和残差网络的准确率很接近,但是残差网络的收敛速度要更快。

(五)深度瓶颈结构(bottleneck)
接下来介绍层次更多的模型,对于每一个残差块,不再使用两层卷积,而是使用三层卷积来实现,如下图所示。只需要将34层resnet网络中的残差模块从2层换成3层,整个网络就变成了50层的resnet。
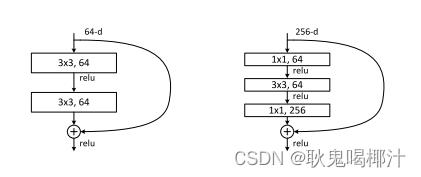
先用1x1降维,再用3x3处理数据,再用1x1升维。(结构主要用于Restnet50/101/152)
实验结果表明 50/101/152层的resnet比34层resnet的准确率要高很多,解决了深层的退化问题。同时即使是152层resnet的计算复杂度仍然比VGG-16和VGG-19要小。
(六)总结
1、退化现象定义:随着网络深度的增加,准确率开始达到饱和并且在之后会迅速下降。
判断方法:随着网络的加深,错误率不降反升,收敛速率也呈指数级下降。
原因:网络过于复杂,训练不加约束。
解决方案:使用残差网络结构。
2、在残差网络中得出的结论:(1)极深残差网络易于优化收敛;(2)解决了退化问题;(3)可以在很深的同时提升准确率。
3、本文提出两种残差结构,一种是两层卷积残差块,应用于ResNet-18和ResNet-34; 另一种是bottleneck三层卷积残差块(分别为1x1降维、3x3、1x1升维)。应用于ResNet-50、ResNet-101和ResNet-152。ResNet-50、ResNet-101、ResNet-152性能都比ResNet-34好。
4.论文成果:基于深度残差网络,在ILSVRC和COCO 2015竞赛中获得了多个赛道的第一名:ImageNet检测、ImageNet定位、COCO检测和COCO分割。
5.数据集:基于ImageNet2012数据集进行评估实验,训练集包含128万张图像,验证集包含5万张图像,测试集有10万张图像,对top-1和top-5的错误率来评估。开源了。
今天的学习总结就到这里啦!如果有什么问题可以在评论区留言呀~
如果帮助到大家,可以一键三连+关注 支持下~
以上是关于LipNet 论文解读的主要内容,如果未能解决你的问题,请参考以下文章