Boyer-Moore算法
Posted et3-tsy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Boyer-Moore算法相关的知识,希望对你有一定的参考价值。
BM(Boyer-Moore)
部分资料来自:https://blog.csdn.net/no_heart2019/article/details/96564763
https://blog.csdn.net/qzp1991/article/details/42663969
BM算法被认为是亚线性串匹配算法,它在最坏情况下找到模式所有出现的时间复杂度为O(mn),在最好情况下执行匹配找到模式所有出现的时间复杂度为O(n/m)。
尤其在空格较多的文本中,比KMP算法的实际效能高。
BM算法从模式串的尾部开始匹配,即从后往前
两个规则
这是BM算法的核心,他有两种跳转方式,分别对应两种规则,而每次跳转多少取决于这两种跳转规则的最大值
坏字符规则(文本中效率高的体现点)
当文本串中的某个字符跟模式串的某个字符不匹配时,我们称文本串中的这个失配字符为坏字符,此时模式串需要向右移动
移动的位数 = 坏字符在模式串中的位置 - 坏字符在模式串中最右出现的位置
此外,如果"坏字符"不包含在模式串之中,则最右出现位置为-1。

S失配,而模式串中S的出现在-1(即没有,w的下标为0)
减去相对位置差S->6(当前坏字符位置), S‘->-1(模式串位置), 6-(-1)==7
所以我们后移7步,得到:

如何理解?我们要让字符串匹配成功的必要条件是让这个坏字符要满足情况,所以你肯定优先找到模式串对应的字符与之匹配,让之先满足情况
其次为了防止漏了正确答案,取的是最右位置
如果是不存在,位置给-1,它就整串下移了
这也就是为什么文本中效率比较高,文本空格多,让坏字符出现的可能性更大,频率更高,跳转性以及跳转幅度很可观
进一步使用坏字符原则我们可以得到:
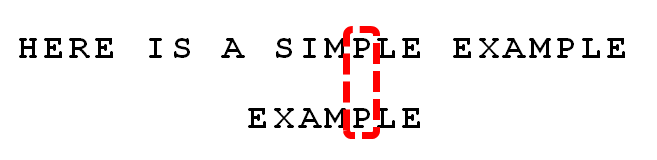
好后缀规则
好后缀,指的就是当前以及匹配上的子串
先看图,下面的图很清晰的展现了好后缀规则,我们现在有好后缀bc
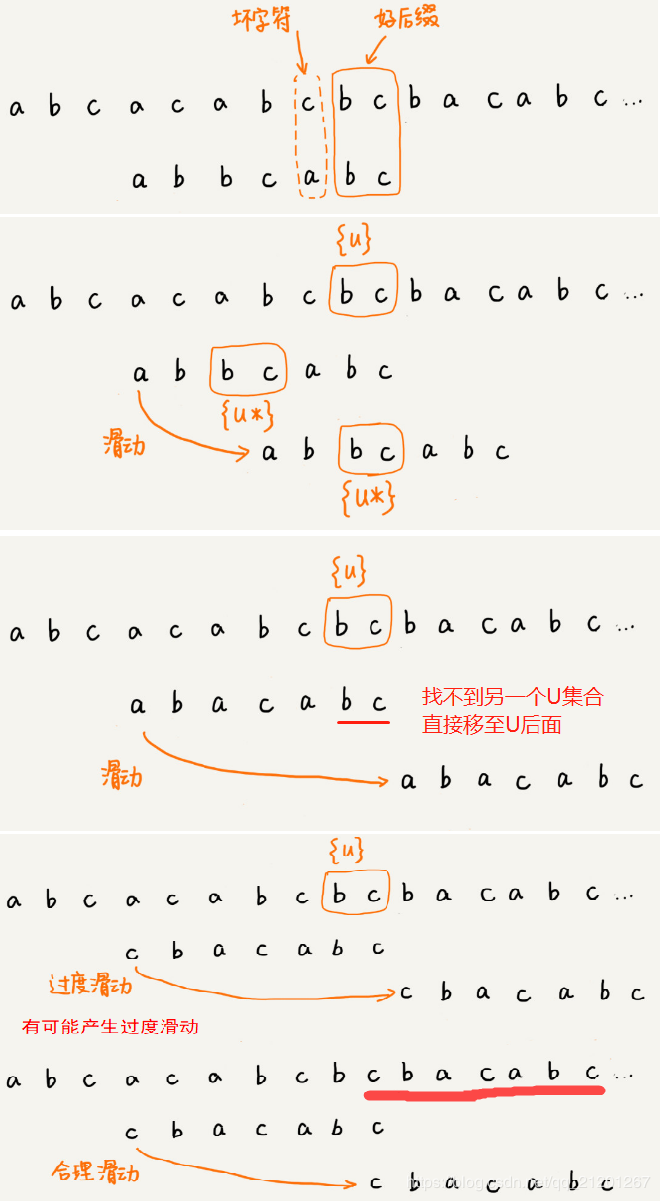
通过上图,我们可以总结出来,此规则是:
从好后缀中的所有后缀子串中,找一个最长的的后缀v,并且使得它在模式串中存在相同的子串v‘,v!=v‘,如图:
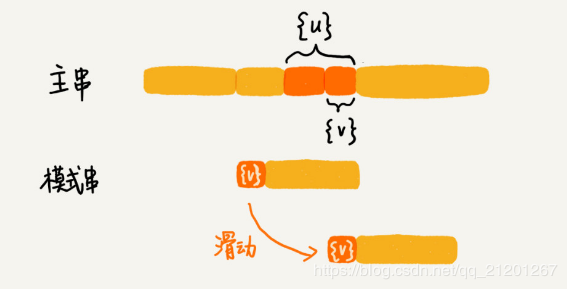
而后移位数,与坏字符规则类似,当字符失配时,后移位数=v‘的位置-v的位置
注意他和kmp的next不同,思路有相似之处
那么BM算法的核心来了,那么如何求好后缀中最长满足条件的子串嘞?
请看下面预处理部分
预处理
坏字符
坏字符,存每个字符出现在最右边的位置,后移步数可能算出来是负的,但是好规则取值一定是正的,取完max无影响
好字符
而好后缀的求解并不像KMP中next数组递推去求解,它求起来细节特别多
首先是暴力求解如下内容,这里复杂度要看模式串情况

for(int i=0;i<s.size()-1;i++)
{
int j=i,k=0;
while(j>=0&&s[j]==s[s.size()-k-1])
{
j--,k++;
suffix[k]=j+1;
}
}
注意这里,当好后缀有多个可行的前缀位置,我们从前往后找会产生覆盖,从而我们取的是这些位置当中最右的
很多情况下,好后缀不一定有对应前缀,但它的后缀子串有
所以为了跳转方便,我们不妨进一步再处理一下,suffix为-1的好后缀它们所包含的最长可行子后缀的情况
int curpos=-1;
for(int i=1;i<=s.size();i++)
{
if(suffix[i]!=-1){curpos=index[i]=i;continue;}
else
{
if(curpos!=-1)suffix[i]=suffix[curpos];
index[i]=curpos;
}
}
匹配
取好规则与坏规则最大者
注意一下suffix为-1的情况以及匹配成功该如何处理(详见代码)
不足
之前讲了最坏情况下找到模式所有出现的时间复杂度为O(mn),why?
比如说,一个最拉跨例子aaaaaaa匹配aaaaaa...复杂度起飞,不仅预处理会拉垮,而且匹配时也会拉垮
但是在正常文本匹配,如文章中找单词,BM效率优于KMP
代码
/*
BM算法
统计目标串中模式串的个数
*/
#include<iostream>
#include<cstring>
#include<string>
using namespace std;
#define maxn 10005
#define ll long long int
int suffix[maxn],index[maxn],Map[256];
void bad_char_deal(string s)//坏字符,建立哈希,映射位置是从左开始
{
memset(Map,-1,sizeof(Map));
for(int i=0;i<s.size();i++)
Map[(int)s[i]]=i;
}
void good_suffix_deal(string s)//好后缀
{
memset(suffix,-1,sizeof(suffix));
memset(index,-1,sizeof(index));
for(int i=0;i<s.size()-1;i++)//暴力处理
{
int j=i,k=0;
while(j>=0&&s[j]==s[s.size()-k-1])
{
j--,k++;
suffix[k]=j+1;//记录当前好后缀对应的前子串位置
}
}
int curpos=-1;
/*这里进行优化,如果好后缀无前对应的子串,
记录好后缀中最大的满足要求的后缀子串,方便后面的跳转
注意这里suffix下标指的是好后缀的长度
*/
for(int i=1;i<=s.size();i++)
{
if(suffix[i]!=-1){curpos=index[i]=i;continue;}
else
{
if(curpos!=-1)suffix[i]=suffix[curpos];
index[i]=curpos;
}
}
}
void prev_deal(string s)
{
//预处理两部分,坏字符,好后缀
bad_char_deal(s);
good_suffix_deal(s);
}
int check(string s,string p)//s为目标串,p为模式串
{
int sum=0,len=p.size();
int pos=len;//pos指的是当前目标串匹配区段末元素的下一位
while(pos<=s.size())
{
int suflen=0;//好后缀长度
while(s[pos-suflen-1]==p[len-suflen-1]&&(len-suflen))
{
//模式串与目标串匹配,每次匹配上,好后缀长度++
suflen++;
}
if(suflen==len)
{
sum++;//匹配成功,总数++,
if(suffix[suflen]!=-1)pos+=len-suffix[suflen]-index[suflen];
else pos+=len;//跳转
}
else
{
int x=len-suflen-1;//当前模式串中坏字符的位置
int mapp=Map[(int)s[pos-suflen-1]];//查找当前目标串坏字符的映射位置,若无则为-1
if(suffix[suflen]==-1)
{
//特判
if(suflen)pos+=len;
else pos+=x-mapp;
}
else
{
//两种移动规则中选较大的方案
pos+=max(x-mapp,len-suffix[suflen]-index[suflen]);
}
}
}
return sum;
}
int main()
{
string patt_str,targ_str;
cin>>patt_str>>targ_str;
prev_deal(patt_str);
cout<<check(targ_str,patt_str)<<endl;
return 0;
}以上是关于Boyer-Moore算法的主要内容,如果未能解决你的问题,请参考以下文章