机器学习-----1.线性回归模型理解证明实现
Posted xieviki650
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习-----1.线性回归模型理解证明实现相关的知识,希望对你有一定的参考价值。
一. 线性回归是什么?
线性回归就是线性的回归。线性是形容词,回归是本质。
我对于视觉记忆比较深刻,所以我们先上图。
这张图就是一个线性回归的实例,红色的点是实际的值,蓝色为估计的线性方程
我们回归的目的就是研究横坐标和纵坐标的关系,当然我们首先考虑这个关系是不是线性的,换句话说这些点关系可不可以用多项式表示
w, b 分别是直线的斜率和截据,也是线性回归最终需要获取的结果。
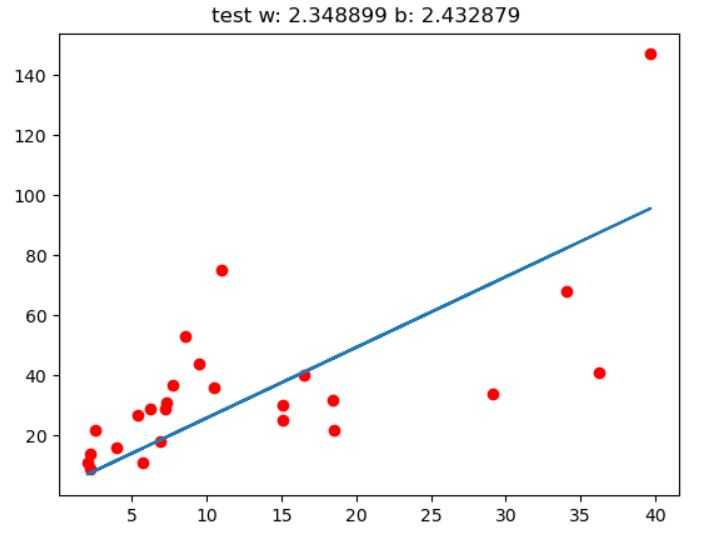
这张图是线性回归最简单的形式,一维,只有一个自变量,一个特征(Feature)
但是现实生活中,并不是所有的东西都只有一个特征,可能是好几个特征决定一个结果
例如,成绩总分是由所有学科的分数相加,各个学科就是不同的特征,总分就是最终想要的结果,并不能用单个成绩来预测总分
线性回归的公式是: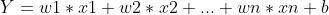
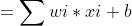 ???????
???????
用成绩来说,语文x1,数学x2,英语x3三门学科成绩为输入,总分y为输出
那么可以得到这样的模型 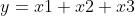 (w1, w2, w3 均为1)
(w1, w2, w3 均为1)
二. 线性回归模型评估
评估函数的建立
模型建立完成后,我们是不知道它是不是真的优秀。
想要知道模型是否优秀,就需要对模型进行评估度量。
评估是什么意思呢,就是预测值y_preddict和我们真实数据y的差距。通过这个值的大小来判断模型的好坏。
机器学习代码中经常看到的Loss损失值,就是我们的评估度量模型的函数,输入预测值和真实值,输出损失
在统计学中,有很多度量的方法,但是统计学几乎忘没了 T_T 要慢慢地多掌握些统计内容。
目前我接触到线性回归使用最多的是平方和误差
还是先通过直观的案例认识一下什么是平方和误差
平方和误差就是每个真实点到预测直线之间距离的平方之和,每个红点到蓝线的距离的平方 累加
平方和误差越大,那么真实值距离预测直线越远,那么这个模型就不好
所以我们希望这个平方和误差是越小越好的,这个思想就是最小二乘法
使用公式可以表示为
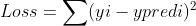
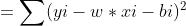 ???????
???????
基础的损失模型建立后,可以加入正则化部分(regularization)P(w)
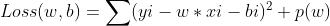 ???????
???????
P(w) 通常是w的第一范式或第二范式
第一范式为所有参数和
第二范式为所有参数平方和
为什么要加入正则化部分呢,主要是为了让预测曲线更加的平滑,让更多的参数接近于0
三. 线性回归模型求解
建立好模型,下一步我们就要找到最好的参数,使我们的损失函数Loss最小
这些参数的初始值是我们设定的,目前我看到的要么是设0要么是设1.
显然,0,1都不可能是我们真实数据的最佳参数
我们需要通过Loss(w,b)函数求使 Loss值最小时对应的 w 和 b 值
那么使用什么方法呢?
假如是高中的数学题,那么我们下意识就想要对w,b求导,然后令求导式为零,就得到w,b
但是,在真实数据中,我们不可能得到求导式,让它为0,那么该怎么操作呢?
GradientDescent!就是他,梯度下降!
梯度在一元线性回归中可简化为斜率
先给出一张图,假设它是损失值随参数w变化的曲线,我们来模拟一下梯度下降的过程。
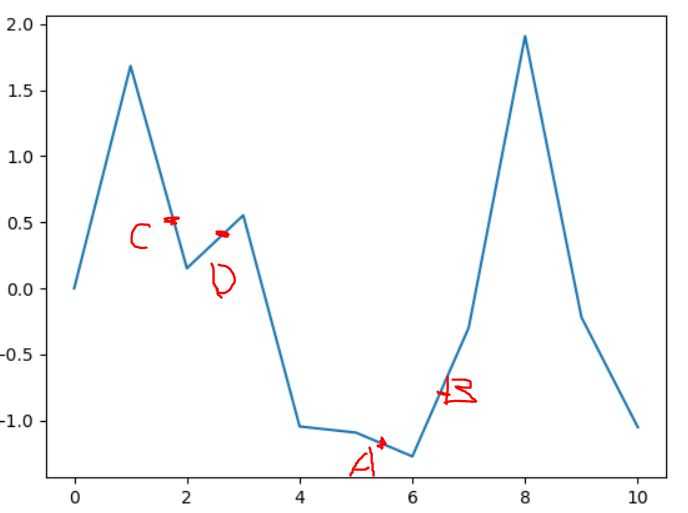
在点A处,斜率是小于零的,可知有更小值在A右侧。于是更新参数值,使它向更小值靠近。
参数更新按照下述公式,梯度小于零,乘一个负数就是使w值增大,即向右侧移动。
#更新函数 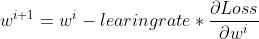
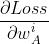 为Loss对w 在A点的偏微分
为Loss对w 在A点的偏微分
点B处,斜率是大于零,可知有更大值在B的左侧。于是更新参数值,按照更新函数,w减小,即向左移动
那按照上面这样的想法,是不是总能找到最小值呢?
我们来看看C,D两点,采用梯度下降只能找到极小值的位置,卡在极小值到达不了最小值
所以,使用梯度下降时,如果初始点没选好或是学习率设置太大,是根本找不到最佳解的
如果学习率过高,已A为例,有可能会跳过最低点,飞到很远
高中数学中令求导项为0,在计算机中可以通过大量的进行获得
更新关键就是获得Loss对w的偏微分。
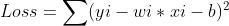
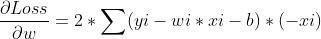
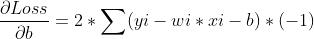
于是参数更新函数为,这里的参数2可以加也可以不加
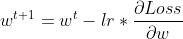
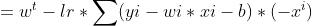
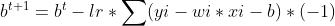
确定好参数更新函数后,接下来做的就是大量的循环,暴力求解啦
四:实际案例
一元线性回归
单纯的X,Y线性关系,画出的散点图就是上面做案例的图

回归效果:
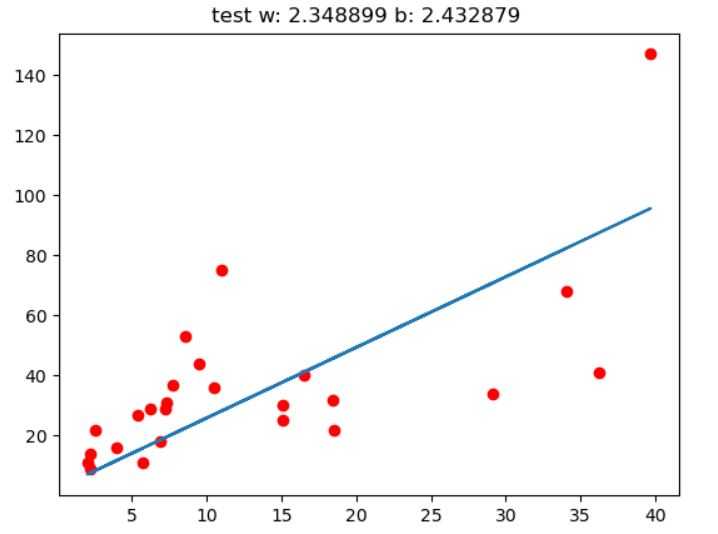
下面是w,b参数在训练中的变化情况
代码部分:
首先,将数据加载进来
#1.加载数据 data_source = "data/fire_theft.xls" #excel表形式 book = xlrd.open_workbook(data_source,encoding_override="utf-8") #通过索引获取内容 sheet = book.sheet_by_index(0) #print(sheet) #读取每一行,将每一行内容提取作为list,再将所有list作为np.array存储 data = np.asarray([sheet.row_values(i) for i in range(1,sheet.nrows)]) #print(data) x = [] y = [] for i in range(len(data)): [x_in,y_in] = data[i] x.append(x_in) y.append(y_in)
将数据分割成训练集,和测试集
#2.数据分割 #选择%数据进行训练,其中70%Training Set 30%Test Set train = int(len(x)*0.7) test = int(len(x)*0.3) x_train = x[0:train] y_train = y[0:train] #[train+valid:-1]无法读取最后一个数 a:b 读取到b-1位置停止,若a: 没有指定尾坐标,直接取到最后一个 x_test = x[train+valid:] y_test = y[train+valid:]
进行训练,这里使用的是SGD(Stochstic Gradient Descent), 不是获取全部数据后更新,而是获取一个数据就更新一次,这样计算时间更快
#3.1 使用Gradient Descent 求解 y = w*x + b #记录每次迭代的w,b值 w_history = [] b_history = [] lr_w = 0.0 lr_b = 0.0 for i in range(iteration): w_grad = 0.0 b_grad = 0.0 Loss = 0.0 for j in range(len(x_train)): #损失函数 y_pred = w*x_train[j] +b Loss = Loss + np.square(y_pred-y_train) #梯度下降 w(i+1) = w(i) - Loss偏微分 w_grad = w_grad - 2.0*(y_train[j] - y_pred)*1.0 b_grad = b_grad - 2.0*(y_train[j] - y_pred)*x_train[j] #adagram 更新 lr_w = lr_w + w_grad**2 #w = w - lr/np.sqrt(lr_w) * w_grad lr_b = lr_b + b_grad**2 w = w - lr * w_grad b = b - lr * b_grad w_history.append(w) b_history.append(b) #3.2.展示回归数据 y_end=[] for i in range(len(x_train)): y_end.append(x_train[i]*w + b) #print(‘w: %f , b: %f‘ %(w,b))
plt.plot(x_train,y_train,‘ro‘) plt.plot(x_train,y_end) plt.title("Self GD w:%f b:%f" %(w,b)) plt.show()
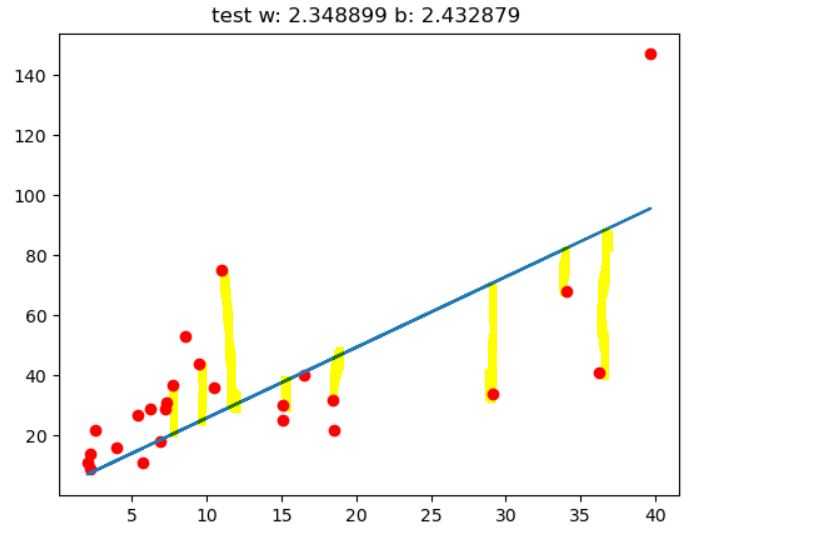
plt.plot(w_history,label = ‘w‘,color =‘r‘) plt.plot(b_history,label = ‘b‘,color = ‘b‘) plt.title("the run chart of w and b") plt.legend() #加入左上角显示框 plt.show() #3.3 测试数据 y_test_end=[] y_test_loss = 0.0 for i in range(len(x_test)): y_test_end.append(x_test[i]*w + b) y_test_loss += np.square(y_test[i] - y_test_end[i]) #print(‘w: %f , b: %f‘ %(w,b)) plt.plot(x_test,y_test,‘ro‘) plt.plot(x_test,y_test_end) plt.title("Self GD w:%f b:%f,loss:%f" %(w,b,y_test_loss/len(x_test))) plt.show()
多元线性回归
使用的是李宏毅老师的PM2.5预测
将不同的检测指标作为特征 xi ,预测值y 为PM2.5值
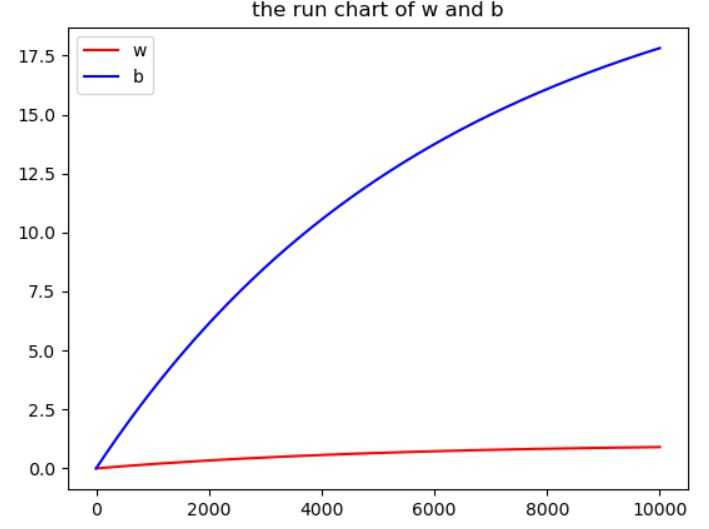
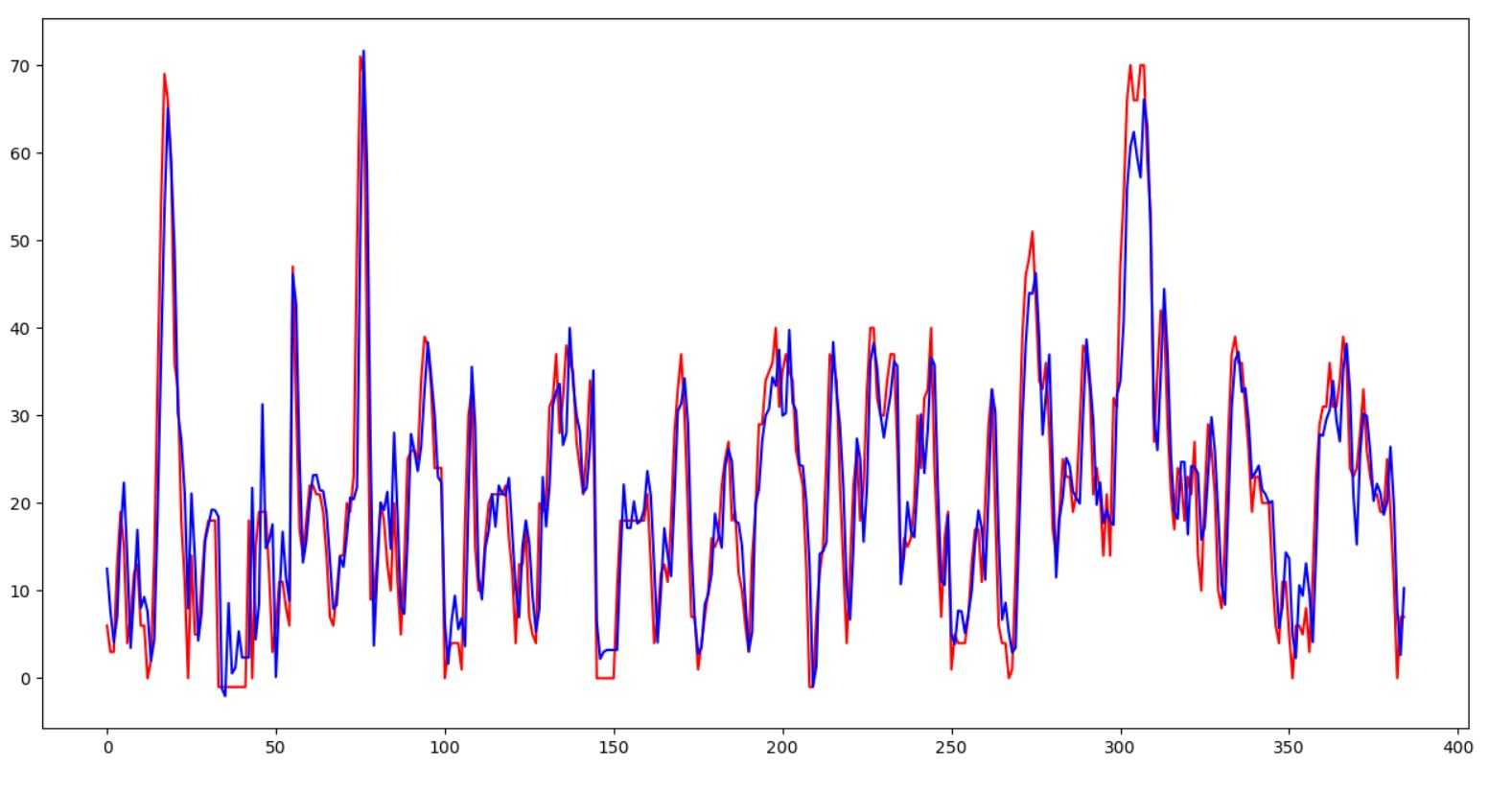
先看线性回归对PM2.5预测的效果
红色点:实际PM2.5值
红色曲线:真实PM2.5变化曲线
蓝色曲线:模型预测曲线
能看出,蓝色曲线能模拟基本的趋势,第二张图就能说明,大致趋势是相同的
测试集的损失值为39,效果并不是很好
代码:
import numpy as np import pandas as pd import matplotlib.pyplot as plt #------PM2.5线性回归预测-------------- #1.数据读取、处理 file = open(‘data/weather_train.csv‘,encoding = ‘gb18030‘) #‘gbk‘ codec can‘t decode byte 0xac in position 9: illegal multibyte sequence file = pd.read_csv(file, usecols=range(3, 27)) # usecols #变为函数 def get_data(file): f = file.replace([‘NR‘], [0.0]) data = f.values.astype(float) # 分析数据,提取数据 # 需要提取240天 每天24 - 9 = 15 个数据集 进行时间片的预测 # 首先取数据模块,18个数据为一组 x_list = [] y_list = [] for i in range(0, data.shape[0]-18, 18): # 取行 18 行 for j in range(24 - 9): # 循环取值 取15次 外围控制输入为3开始 temp_x = data[i:i + 18, j:j + 9] temp_y = data[i + 9, j + 9] x_list.append(temp_x) y_list.append(temp_y) x = np.array(x_list) y = np.array(y_list) return x,y #2.模型设计 不用tensorflow #使用SGD def train_model(x,y,learning_rate=1,epoch=1000): #设置初始参数 weight = np.ones(9) bias = 0.0 #正则参数 regu_rate = 0.001 w_sum = np.zeros(9) #所有训练综合,因此放在最外面 b_sum = 0.0 w_out = [] b_out = [] for ep in range(epoch): for i in range(len(x)): w_in = (y[i] - weight.dot(x[i, 9, :]) - bias) * (-x[i, 9, :]) b_in = (y[i] - weight.dot(x[i, 9, :]) - bias) * (-1) w_sum += w_in ** 2 b_sum += b_in ** 2 # 进行函数更新 weight += - learning_rate / w_sum ** 0.5 * (w_in + regu_rate*np.sum(weight)) #加入regu_rate 正则化函数 bias -= learning_rate / b_sum ** 0.5 * b_in w_out.append(weight[0]) b_out.append(bias) # 输出损失值 loss = 0.0 for m in range(len(x)): loss += (y[m] - weight.dot(x[m,9,:]) - bias)**2 print("Epoch:%d loss:%f"%(ep,loss/len(x))) plt.plot(w_out) plt.plot(b_out) plt.show() return weight,bias x,y = get_data(file) x_train = x[0:3200] y_train = y[0:3200] x_valid = x[3200:] y_valid = y[3200:] weight,bias=train_model(x_train,y_train,epoch=1000) #测试集训练 y_pred = [] loss_pred = 0.0 for i in range(len(x_valid)): y_pred.append( weight.dot(x_valid[i,9,:]) + bias) loss_pred+=(y_valid[i] - y_pred[i])**2 print("the cost of test:",loss_pred/len(x_valid)) plt.plot(range(len(y_valid)),y_valid,‘r‘) plt.plot(range(len(y_valid)),y_pred,‘b‘) plt.show()
第一次博客园发博成就 get
以上是关于机器学习-----1.线性回归模型理解证明实现的主要内容,如果未能解决你的问题,请参考以下文章