深入理解TCP协议及其源代码
Posted hmyaa
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入理解TCP协议及其源代码相关的知识,希望对你有一定的参考价值。
深入理解TCP协议及其源代码
实验环境:Linux-5.0.1 内核 32位系统的MenuOS
本次主要分析理解TCP三次握手,和跟踪三次握手的基本过程
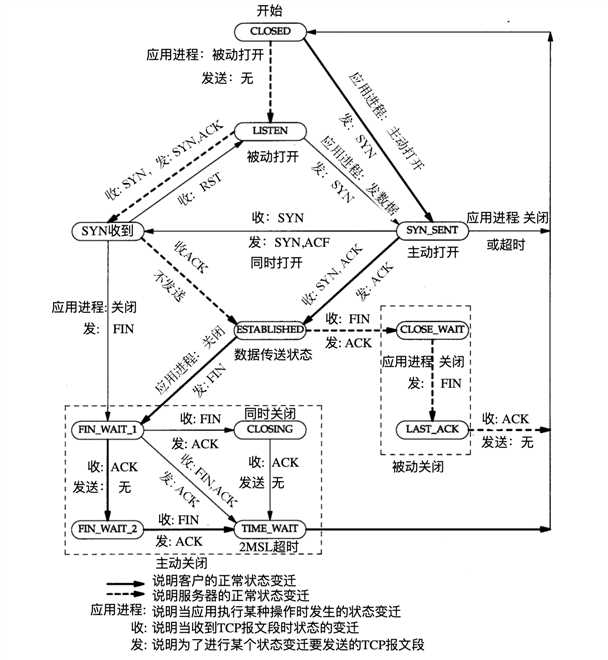
该TCP协议的状态转换图,完整的描述了TCP状态的变化:
从中可以清楚的了解到整个TCP状态转移的过程。总共有11个状态。
先说明下图中每个字段的含义:
- LISTEN:服务器打开一个socket进行监听
- SYN_SENT:当socket执行CONNECT连接时,客户端发送了SYN报文,并等待服务器发送三次握手中的第2个报文。SYN_SENT 状态表示客户端已发送SYN报文。
- SYN_RCVD:表示接受到了SYN报到,该状态是SOCKET建立TCP的连接时的三次握手会话过程的一个中间状态,很短暂,基本上很难通过netstat观察到。
- ESTABLISHED:表示客户端和服务器连接建立。
- FIN_WAIT_1:该状态与FIN_WAIT_2状态都是表示等待对方的FIN报文。但是FIN_WAIT_1状态是ESTABLISHED状态时,它想主动关闭连接,向对方发送了FIN报文,此时该SOCKET即进入FIN_WAIT_1状态。而FIN_WAIT_2状态是服务器回应ACK报文进入的状态。
- FIN_WAIT_2:是socket的半连接状态,也就是一方要求close连接,但另外自己还有数据要传送给对方。
- TIME_WAIT:表示收到了FIN报文,并放松ACK报文,接着就等待2MSL后进入CLOSED可用状态。如果FIN_WAIT_1状态下,收到了FIN和ACK,那将直接进入TIME_WAIT状态,而无须经过FIN_WAIT_2状态。
- CLOSING:这种比较特殊,实际情况很少出现,一方发送一一个FIN,同时另外一方也发送了一个FIN,而没有中间的ACK报文的发送。这种一般发生在双方同时关闭的情况下。
- CLOSE_WAIT:等待关闭,表示对方close一个socket后放松FIN报文给自己,你发送一个ACK就进入了这个状态。如果你有数据发送那么就传送给对方,直到发送FIN给对方,进入关闭状态。所以在该状态下,需要完成的事情是等待你去关闭连接。
- LAST_ACK:被动关闭的一方在发送FIN报文后,最后等待对方的ACK报文,当收到ACK报文,也就进入了CLOSED状态。
- CLOSED:初始状态,也是结束状态。
前面第一次作业已经通过用netstat观察过TCP的状态的变化,现在通过源代码来理解协议的
/net/socket.c
SYSCALL_DEFINE2(socketcall, int, call, unsigned long __user *, args)
{
// ...
switch (call) {
case SYS_SOCKET:
err = __sys_socket(a0, a1, a[2]);
break;
case SYS_BIND:
err = __sys_bind(a0, (struct sockaddr __user *)a1, a[2]);
break;
case SYS_CONNECT:
err = __sys_connect(a0, (struct sockaddr __user *)a1, a[2]);
break;
case SYS_LISTEN:
err = __sys_listen(a0, a1);
break;
case SYS_ACCEPT:
err = __sys_accept4(a0, (struct sockaddr __user *)a1,
(int __user *)a[2], 0);
break;
//...
}这是上次分析到了,系统调用根据相应的标志,访问相应的系统调用。现在深入系统调用__sys_bind里面
int __sys_bind(int fd, struct sockaddr __user *umyaddr, int addrlen)
struct socket *sock;
struct sockaddr_storage address;
int err, fput_needed;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (sock) {
err = move_addr_to_kernel(umyaddr, addrlen, &address);
if (!err) {
err = security_socket_bind(sock,
(struct sockaddr *)&address,
addrlen);
if (!err)
err = sock->ops->bind(sock, //******
(struct sockaddr *)
&address, addrlen);
}
fput_light(sock->file, fput_needed);
}
return err;
}
sock->ops->bind是执行相应功能的函数,类似的可以在__sys_connect中可以看到,sock->ops->connect,
sock是struct socket类型
struct socket {
socket_state state;
short type;
unsigned long flags;
struct socket_wq *wq;
struct file *file;
struct sock *sk;
const struct proto_ops *ops;
};查看ops对用在tcp_ipv4中的数据结构
//tcp_ipv4.c
struct proto tcp_prot = {
.name = "TCP",
.owner = THIS_MODULE,
.close = tcp_close,
.pre_connect = tcp_v4_pre_connect,
.connect = tcp_v4_connect,
.disconnect = tcp_disconnect,
.accept = inet_csk_accept,
.ioctl = tcp_ioctl,
.init = tcp_v4_init_sock,
.destroy = tcp_v4_destroy_sock,
//...
};tcp_ipv4中对数据进行了初始化,connect和accept分别对应的是tcp_v4_connect和inet_csk_accept,tcp中的conncet也是三次握手动作中的关键步骤,
int tcp_v4_connect(struct sock *sk, struct sockaddr *uaddr, int addr_len)
{
struct sockaddr_in *usin = (struct sockaddr_in *)uaddr;
struct inet_sock *inet = inet_sk(sk);
struct tcp_sock *tp = tcp_sk(sk);
__be16 orig_sport, orig_dport;
__be32 daddr, nexthop;
struct flowi4 *fl4;
struct rtable *rt;
int err;
struct ip_options_rcu *inet_opt;
struct inet_timewait_death_row *tcp_death_row = &sock_net(sk)->ipv4.tcp_death_row;
if (addr_len < sizeof(struct sockaddr_in))
return -EINVAL;
if (usin->sin_family != AF_INET)
return -EAFNOSUPPORT;
nexthop = daddr = usin->sin_addr.s_addr;
inet_opt = rcu_dereference_protected(inet->inet_opt,
lockdep_sock_is_held(sk));
if (inet_opt && inet_opt->opt.srr) {
if (!daddr)
return -EINVAL;
nexthop = inet_opt->opt.faddr;
}
orig_sport = inet->inet_sport;
orig_dport = usin->sin_port;
fl4 = &inet->cork.fl.u.ip4;
rt = ip_route_connect(fl4, nexthop, inet->inet_saddr,
RT_CONN_FLAGS(sk), sk->sk_bound_dev_if,
IPPROTO_TCP,
orig_sport, orig_dport, sk);
if (IS_ERR(rt)) {
err = PTR_ERR(rt);
if (err == -ENETUNREACH)
IP_INC_STATS(sock_net(sk), IPSTATS_MIB_OUTNOROUTES);
return err;
}
if (rt->rt_flags & (RTCF_MULTICAST | RTCF_BROADCAST)) {
ip_rt_put(rt);
return -ENETUNREACH;
}
if (!inet_opt || !inet_opt->opt.srr)
daddr = fl4->daddr;
if (!inet->inet_saddr)
inet->inet_saddr = fl4->saddr;
sk_rcv_saddr_set(sk, inet->inet_saddr);
if (tp->rx_opt.ts_recent_stamp && inet->inet_daddr != daddr) {
/* Reset inherited state */
tp->rx_opt.ts_recent = 0;
tp->rx_opt.ts_recent_stamp = 0;
if (likely(!tp->repair))
tp->write_seq = 0;
}
inet->inet_dport = usin->sin_port;
sk_daddr_set(sk, daddr);
inet_csk(sk)->icsk_ext_hdr_len = 0;
if (inet_opt)
inet_csk(sk)->icsk_ext_hdr_len = inet_opt->opt.optlen;
tp->rx_opt.mss_clamp = TCP_MSS_DEFAULT;
/* Socket identity is still unknown (sport may be zero).
* However we set state to SYN-SENT and not releasing socket
* lock select source port, enter ourselves into the hash tables and
* complete initialization after this.
*/
tcp_set_state(sk, TCP_SYN_SENT);
err = inet_hash_connect(tcp_death_row, sk);
if (err)
goto failure;
sk_set_txhash(sk);
rt = ip_route_newports(fl4, rt, orig_sport, orig_dport,
inet->inet_sport, inet->inet_dport, sk);
if (IS_ERR(rt)) {
err = PTR_ERR(rt);
rt = NULL;
goto failure;
}
/* OK, now commit destination to socket. */
sk->sk_gso_type = SKB_GSO_TCPV4;
sk_setup_caps(sk, &rt->dst);
rt = NULL;
if (likely(!tp->repair)) {
if (!tp->write_seq)
tp->write_seq = secure_tcp_seq(inet->inet_saddr,
inet->inet_daddr,
inet->inet_sport,
usin->sin_port);
tp->tsoffset = secure_tcp_ts_off(sock_net(sk),
inet->inet_saddr,
inet->inet_daddr);
}
inet->inet_id = tp->write_seq ^ jiffies;
if (tcp_fastopen_defer_connect(sk, &err))
return err;
if (err)
goto failure;
err = tcp_connect(sk); //负责进行connect工作
if (err)
goto failure;
return 0;
failure:
/*
* This unhashes the socket and releases the local port,
* if necessary.
*/
tcp_set_state(sk, TCP_CLOSE);
ip_rt_put(rt);
sk->sk_route_caps = 0;
inet->inet_dport = 0;
return err;
}
EXPORT_SYMBOL(tcp_v4_connect);接下来进入tcp_connect中,该函数进行封装报
/* Build a SYN and send it off. */
int tcp_connect(struct sock *sk)
{
struct tcp_sock *tp = tcp_sk(sk);
struct sk_buff *buff;
int err;
tcp_call_bpf(sk, BPF_SOCK_OPS_TCP_CONNECT_CB, 0, NULL);
if (inet_csk(sk)->icsk_af_ops->rebuild_header(sk))
return -EHOSTUNREACH; /* Routing failure or similar. */
tcp_connect_init(sk);
if (unlikely(tp->repair)) {
tcp_finish_connect(sk, NULL);
return 0;
}
buff = sk_stream_alloc_skb(sk, 0, sk->sk_allocation, true);
if (unlikely(!buff))
return -ENOBUFS;
tcp_init_nondata_skb(buff, tp->write_seq++, TCPHDR_SYN);
tcp_mstamp_refresh(tp);
tp->retrans_stamp = tcp_time_stamp(tp);
tcp_connect_queue_skb(sk, buff);
tcp_ecn_send_syn(sk, buff);
tcp_rbtree_insert(&sk->tcp_rtx_queue, buff);
/* Send off SYN; include data in Fast Open. */
err = tp->fastopen_req ? tcp_send_syn_data(sk, buff) :
tcp_transmit_skb(sk, buff, 1, sk->sk_allocation);//发送tcp报文
if (err == -ECONNREFUSED)
return err;
/* We change tp->snd_nxt after the tcp_transmit_skb() call
* in order to make this packet get counted in tcpOutSegs.
*/
tp->snd_nxt = tp->write_seq;
tp->pushed_seq = tp->write_seq;
buff = tcp_send_head(sk);
if (unlikely(buff)) {
tp->snd_nxt = TCP_SKB_CB(buff)->seq;
tp->pushed_seq = TCP_SKB_CB(buff)->seq;
}
TCP_INC_STATS(sock_net(sk), TCP_MIB_ACTIVEOPENS);
/* Timer for repeating the SYN until an answer. */
inet_csk_reset_xmit_timer(sk, ICSK_TIME_RETRANS,
inet_csk(sk)->icsk_rto, TCP_RTO_MAX);
return 0;
}
从tcp_v4_connect中调用tcp_connect负责制作SYN包和发送报文,也可以说这个函数与底层的ip进行了对接,接受ip层的数据。
接下来看看负责accept的函数指针调用的函数,inet_csk_accept
struct sock *inet_csk_accept(struct sock *sk, int flags, int *err, bool kern)
{
struct inet_connection_sock *icsk = inet_csk(sk);
struct request_sock_queue *queue = &icsk->icsk_accept_queue;
struct request_sock *req;
struct sock *newsk;
int error;
lock_sock(sk);
/* We need to make sure that this socket is listening,
* and that it has something pending.
*/
error = -EINVAL;
if (sk->sk_state != TCP_LISTEN)
goto out_err;
/* Find already established connection */
if (reqsk_queue_empty(queue)) {
long timeo = sock_rcvtimeo(sk, flags & O_NONBLOCK);
/* If this is a non blocking socket don't sleep */
error = -EAGAIN;
if (!timeo)
goto out_err;
error = inet_csk_wait_for_connect(sk, timeo); //循环
if (error)
goto out_err;
}
req = reqsk_queue_remove(queue, sk);
newsk = req->sk;
if (sk->sk_protocol == IPPROTO_TCP &&
tcp_rsk(req)->tfo_listener) {
spin_lock_bh(&queue->fastopenq.lock);
if (tcp_rsk(req)->tfo_listener) {
/* We are still waiting for the final ACK from 3WHS
* so can't free req now. Instead, we set req->sk to
* NULL to signify that the child socket is taken
* so reqsk_fastopen_remove() will free the req
* when 3WHS finishes (or is aborted).
*/
req->sk = NULL;
req = NULL;
}
spin_unlock_bh(&queue->fastopenq.lock);
}
out:
release_sock(sk);
if (req)
reqsk_put(req);
return newsk;
out_err:
newsk = NULL;
req = NULL;
*err = error;
goto out;
}那么accept实现不断的接受请求的,可以进入inet_csk_wait_for_connect中了解到
static int inet_csk_wait_for_connect(struct sock *sk, long timeo)
{
struct inet_connection_sock *icsk = inet_csk(sk);
DEFINE_WAIT(wait);
int err;
/*
* True wake-one mechanism for incoming connections: only
* one process gets woken up, not the 'whole herd'.
* Since we do not 'race & poll' for established sockets
* anymore, the common case will execute the loop only once.
*
* Subtle issue: "add_wait_queue_exclusive()" will be added
* after any current non-exclusive waiters, and we know that
* it will always _stay_ after any new non-exclusive waiters
* because all non-exclusive waiters are added at the
* beginning of the wait-queue. As such, it's ok to "drop"
* our exclusiveness temporarily when we get woken up without
* having to remove and re-insert us on the wait queue.
*/
for (;;) {
prepare_to_wait_exclusive(sk_sleep(sk), &wait,
TASK_INTERRUPTIBLE);
release_sock(sk);
if (reqsk_queue_empty(&icsk->icsk_accept_queue))
timeo = schedule_timeout(timeo);
sched_annotate_sleep();
lock_sock(sk);
err = 0;
if (!reqsk_queue_empty(&icsk->icsk_accept_queue))
break;
err = -EINVAL;
if (sk->sk_state != TCP_LISTEN)
break;
err = sock_intr_errno(timeo);
if (signal_pending(current))
break;
err = -EAGAIN;
if (!timeo)
break;
}
finish_wait(sk_sleep(sk), &wait);
return err;
}该函数是一个无限的for循环,只要有连接请求,那么就跳出循环。
接下可我们可以通过在MeunOS的内核调试环境下设置断点来跟踪,由前面我们可以设置断点在tcp_v4_connect,和inet_csk_accept中来验证三次握手。
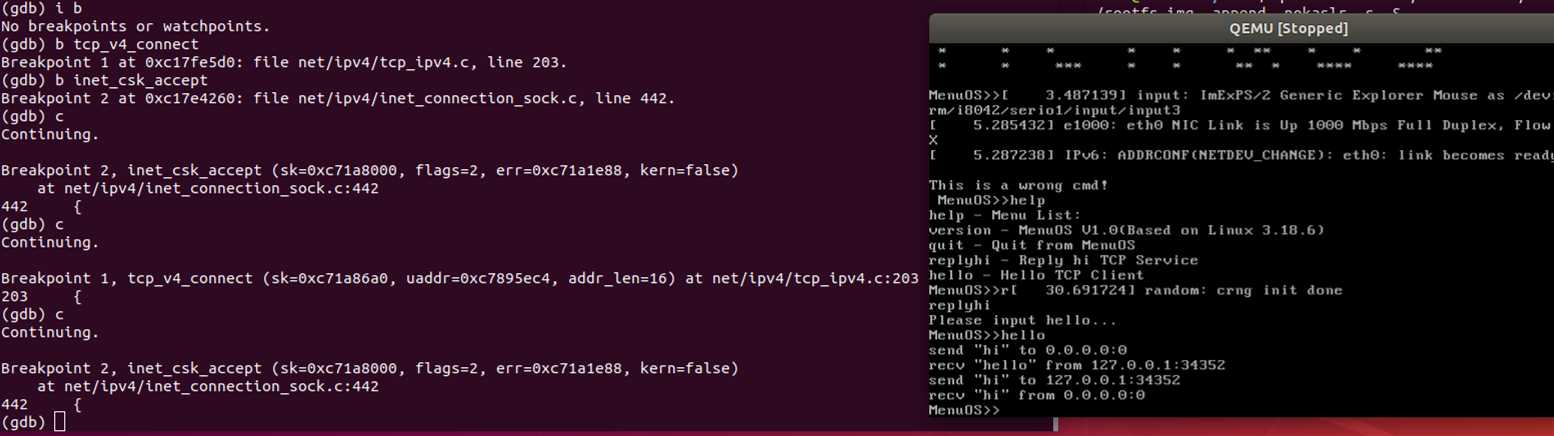
可以看到accpet出现了两次,一次是server启动时等待接受,第二次是server接受了client的connect请求,和我们之前的理论相一致。
以上是关于深入理解TCP协议及其源代码的主要内容,如果未能解决你的问题,请参考以下文章