深入理解TCP协议及其源代码
Posted liwj57csseblog
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入理解TCP协议及其源代码相关的知识,希望对你有一定的参考价值。
本次实验是在X86 64环境下Ubuntu18.04.3以及Linux5.0以上的内核中进行。通过理论分析、源代码阅读和运行跟踪深入理解TCP协议connect及bind、listen、accept背后的三次握手。
Socket
socket起源于Unix,而Unix/Linux基本哲学之一就是“一切皆文件”,都可以用“打开open –> 读写write/read –> 关闭close”模式来操作。Socket就是该模式的一个实现,socket即是一种特殊的文件,一些socket函数就是对其进行的操作(读/写IO、打开、关闭). 说白了Socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。在设计模式中,Socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部,让Socket去组织数据,以符合指定的协议。
注意:其实socket也没有层的概念,它只是一个facade设计模式的应用,让编程变的更简单。是一个软件抽象层。在网络编程中,我们大量用的都是通过socket实现的。
套接字是通信端点的抽象,其英文socket,即为插座,孔的意思。如果两个机子要通信,中间要通过一条线,这条线的两端要连接通信的双方,这条线在每一台机子上的接入点则为socket,即为插孔,所以在通信前,我们在通信的两端必须要建立好这个插孔,同时为了保证通信的正确,端和端之间的插孔必须要一一对应,这样两端便可以正确的进行通信了,而这个插孔对应到我们实际的操作系统中,就是socket文件,我们再创建它之后,就会得到一个操作系统返回的对于该文件的描述符,然后应用程序可以通过使用套接字描述符访问套接字,向其写入输入,读出数据。
站在更贴近系统的层级去看,两个机器间的通信方式,无非是要通过运输层的TCP/UDP,网络层IP,因此socket本质是编程接口(API),对TCP/UDP/IP的封装,TCP/UDP/IP也要提供可供程序员做网络开发所用的接口,这就是Socket编程接口。
socket通信过程:
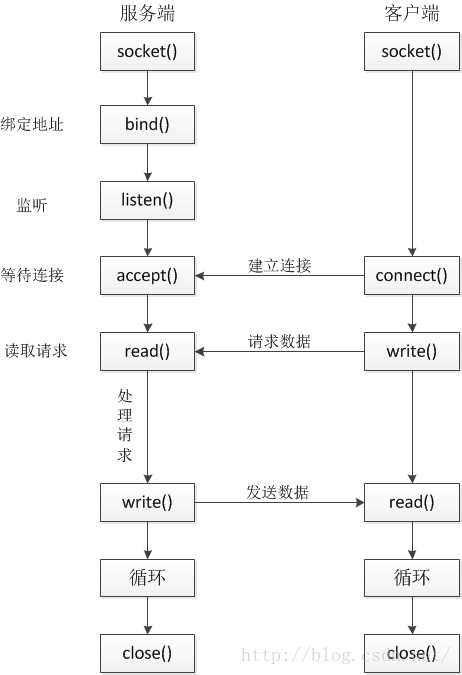
TCP通信
定义:
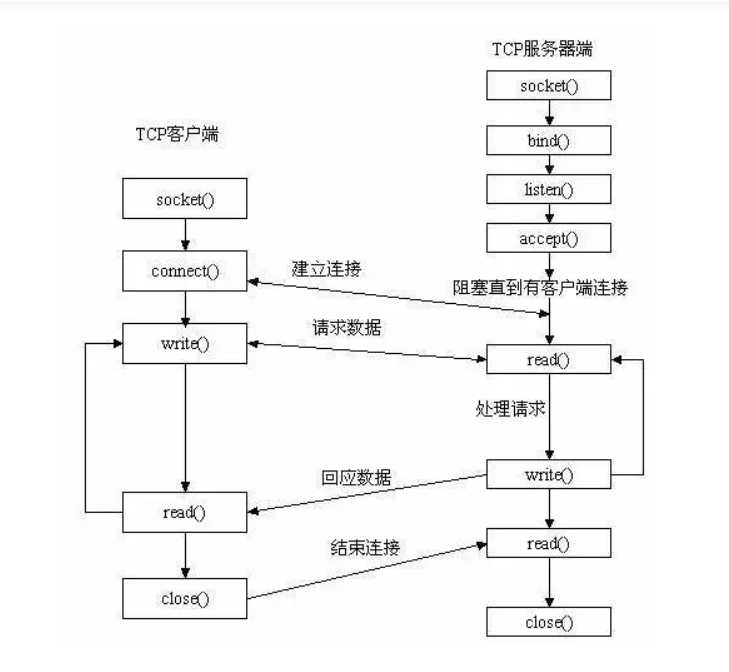

客户端
(1)创建客户端 Socket 对象
(2)获取 Socket 的输出流对象
(3)写数据到服务器
(4)获取 Socket 的输入流对象
(5)使用输入流,读取反馈信息
(6) 关闭流资源
服务器端
(1)创建服务器端ServerSocket 对象,指定端口号
(2)开启服务器,等待着客户端Socket对象的连接,如有客户端连接,返回客户端的 Socket对象
(3)通过客户端的 Socket 对象,获取客户端的输入流,为了实现获取客户端发来的数据
(4)通过客户端的输入流,获取流中的数据
(5)通过客户端的 Socket 对象,获取客户端的输出流,为了实现给客户端的信息反馈
(6)通过客户端的输出流,写数据到流中
(7)关闭流资源
实验过程:
运行qemu:进入menu文件夹下,打开MenuOS
make rootfs

此时切不可关闭该终端和QEMU,返回到目录../linux-5.0.1下,打开另一个终端,输入如下命令:
gdb file ./vmlinux target remote:1234
然后根据连接过程的所用到的系统调用函数进行设置断点:
b __sys_socket
b __sys_connect
b __sys_bind
b __sys_listen
b __sys_accept4
info breakpoints
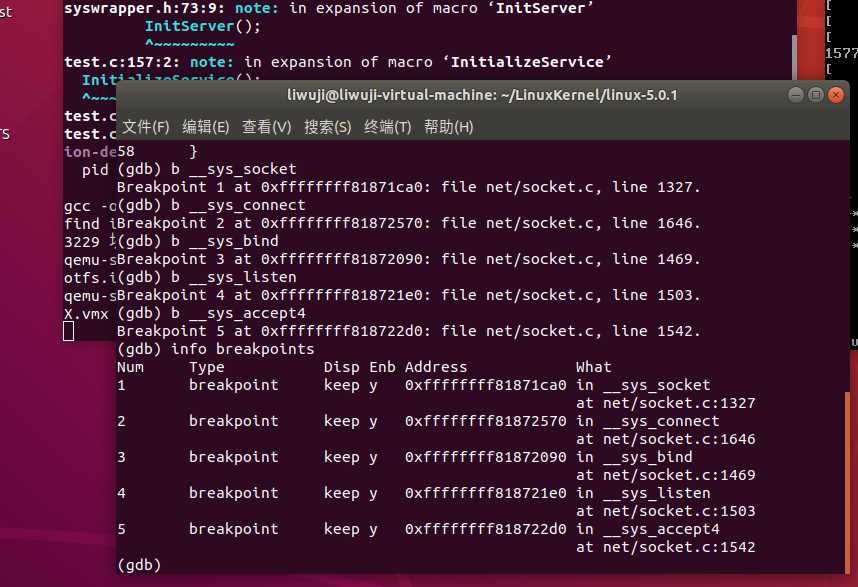
然后根据提示找到socket函数,connect函数,bind函数,listen函数和accept函数。
int __sys_socket(int family, int type, int protocol)
{
int retval;
struct socket *sock;
int flags;
/* Check the SOCK_* constants for consistency. */
BUILD_BUG_ON(SOCK_CLOEXEC != O_CLOEXEC);
BUILD_BUG_ON((SOCK_MAX | SOCK_TYPE_MASK) != SOCK_TYPE_MASK);
BUILD_BUG_ON(SOCK_CLOEXEC & SOCK_TYPE_MASK);
BUILD_BUG_ON(SOCK_NONBLOCK & SOCK_TYPE_MASK);
flags = type & ~SOCK_TYPE_MASK;
if (flags & ~(SOCK_CLOEXEC | SOCK_NONBLOCK))
return -EINVAL;
type &= SOCK_TYPE_MASK;
if (SOCK_NONBLOCK != O_NONBLOCK && (flags & SOCK_NONBLOCK))
flags = (flags & ~SOCK_NONBLOCK) | O_NONBLOCK;
retval = sock_create(family, type, protocol, &sock);
if (retval < 0)
return retval;
return sock_map_fd(sock, flags & (O_CLOEXEC | O_NONBLOCK));
}
SYSCALL_DEFINE3(socket, int, family, int, type, int, protocol)
{
return __sys_socket(family, type, protocol);
}
socket函数就是生成一个用于通信的套接字文件描述符sock_map_fd(sock,flags & (O_CLOEXEC | O_NONBOLCK))。这个套接字描述符可以作为稍后bind()函数的绑定对象。
socket函数对应于普通文件的打开操作。普通文件的打开操作返回一个文件描述字,而socket()用于创建一个socket描述符(socket descriptor),它唯一标识一个socket。这个socket描述字跟文件描述字一样,后续的操作都有用到它,把它作为参数,通过它来进行一些读写操作。
创建socket的时候,也可以指定不同的参数创建不同的socket描述符,socket函数的三个参数分别为:
- family:即协议族(family)。常用的协议族有,AF_INET、AF_INET6、AF_LOCAL(或称AF_UNIX,Unix域socket)、AF_ROUTE等等。协议族决定了socket的地址类型,在通信中必须采用对应的地址,如AF_INET决定了要用ipv4地址(32位的)与端口号(16位的)的组合、AF_UNIX决定了要用一个绝对路径名作为地址。
- type:指定socket类型。常用的socket类型有,SOCK_STREAM、SOCK_DGRAM、SOCK_RAW、SOCK_PACKET、SOCK_SEQPACKET等等。
- protocol:故名思义,就是指定协议。常用的协议有,IPPROTO_TCP、IPPTOTO_UDP、IPPROTO_SCTP、IPPROTO_TIPC等,它们分别对应TCP传输协议、UDP传输协议、STCP传输协议、TIPC传输协议。
当我们调用socket创建一个socket时,返回的socket描述字它存在于协议族(address family,AF_XXX)空间中,但没有一个具体的地址。如果想要给它赋值一个地址,就必须调用bind()函数,否则就当调用connect()、listen()时系统会自动随机分配一个端口。
int __sys_connect(int fd, struct sockaddr __user *uservaddr, int addrlen)
{
struct socket *sock;
struct sockaddr_storage address;
int err, fput_needed;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (!sock)
goto out;
err = move_addr_to_kernel(uservaddr, addrlen, &address);
if (err < 0)
goto out_put;
err =
security_socket_connect(sock, (struct sockaddr *)&address, addrlen);
if (err)
goto out_put;
err = sock->ops->connect(sock, (struct sockaddr *)&address, addrlen,
sock->file->f_flags);
out_put:
fput_light(sock->file, fput_needed);
out:
return err;
}
SYSCALL_DEFINE3(connect, int, fd, struct sockaddr __user *, uservaddr,
int, addrlen)
{
return __sys_connect(fd, uservaddr, addrlen);
}
connect函数的第一个参数即为客户端的socket描述字,第二参数为服务器的socket地址,第三个参数为socket地址的长度。客户端通过调用connect函数来建立与TCP服务器的连接。
int __sys_bind(int fd, struct sockaddr __user *umyaddr, int addrlen) { struct socket *sock; struct sockaddr_storage address; int err, fput_needed; sock = sockfd_lookup_light(fd, &err, &fput_needed); if (sock) { err = move_addr_to_kernel(umyaddr, addrlen, &address); if (!err) { err = security_socket_bind(sock, (struct sockaddr *)&address, addrlen); if (!err) err = sock->ops->bind(sock, (struct sockaddr *) &address, addrlen); } fput_light(sock->file, fput_needed); } return err; } SYSCALL_DEFINE3(bind, int, fd, struct sockaddr __user *, umyaddr, int, addrlen) { return __sys_bind(fd, umyaddr, addrlen); }
bind()函数把一个地址族中的特定地址赋给socket。
函数的三个参数分别为:
- fd:即socket描述字,它是通过socket()函数创建了,唯一标识一个socket。bind()函数就是将给这个描述字绑定一个名字。
- umyaaddr:一个const struct sockaddr *指针,指向要绑定给sockfd的协议地址。这个地址结构根据地址创建socket时的地址协议族的不同而不同
- addrlen:对应的是地址的长度。
通常服务器在启动的时候都会绑定一个众所周知的地址(如ip地址+端口号),用于提供服务,客户就可以通过它来接连服务器;而客户端就不用指定,有系统自动分配一个端口号和自身的ip地址组合。
int __sys_listen(int fd, int backlog) { struct socket *sock; int err, fput_needed; int somaxconn; sock = sockfd_lookup_light(fd, &err, &fput_needed); if (sock) { somaxconn = sock_net(sock->sk)->core.sysctl_somaxconn; if ((unsigned int)backlog > somaxconn) backlog = somaxconn; err = security_socket_listen(sock, backlog); if (!err) err = sock->ops->listen(sock, backlog); fput_light(sock->file, fput_needed); } return err; } SYSCALL_DEFINE2(listen, int, fd, int, backlog) { return __sys_listen(fd, backlog); }
服务器在调用socket()、bind()之后就会调用listen()来监听这个socket,如果客户端这时调用connect()发出连接请求,服务器端就会接收到这个请求。listen函数的第一个参数即为要监听的socket描述字,第二个参数为相应socket可以排队的最大连接个数。socket()函数创建的socket默认是一个主动类型的,listen函数将socket变为被动类型的,等待客户的连接请求。
int __sys_accept4(int fd, struct sockaddr __user *upeer_sockaddr, int __user *upeer_addrlen, int flags) { struct socket *sock, *newsock; struct file *newfile; int err, len, newfd, fput_needed; struct sockaddr_storage address; if (flags & ~(SOCK_CLOEXEC | SOCK_NONBLOCK)) return -EINVAL; if (SOCK_NONBLOCK != O_NONBLOCK && (flags & SOCK_NONBLOCK)) flags = (flags & ~SOCK_NONBLOCK) | O_NONBLOCK; sock = sockfd_lookup_light(fd, &err, &fput_needed); if (!sock) goto out; err = -ENFILE; newsock = sock_alloc(); if (!newsock) goto out_put; newsock->type = sock->type; newsock->ops = sock->ops; /* * We don‘t need try_module_get here, as the listening socket (sock) * has the protocol module (sock->ops->owner) held. */ __module_get(newsock->ops->owner); newfd = get_unused_fd_flags(flags); if (unlikely(newfd < 0)) { err = newfd; sock_release(newsock); goto out_put; } newfile = sock_alloc_file(newsock, flags, sock->sk->sk_prot_creator->name); if (IS_ERR(newfile)) { err = PTR_ERR(newfile); put_unused_fd(newfd); goto out_put; } err = security_socket_accept(sock, newsock); if (err) goto out_fd; err = sock->ops->accept(sock, newsock, sock->file->f_flags, false); if (err < 0) goto out_fd; if (upeer_sockaddr) { len = newsock->ops->getname(newsock, (struct sockaddr *)&address, 2); if (len < 0) { err = -ECONNABORTED; goto out_fd; } err = move_addr_to_user(&address, len, upeer_sockaddr, upeer_addrlen); if (err < 0) goto out_fd; } /* File flags are not inherited via accept() unlike another OSes. */ fd_install(newfd, newfile); err = newfd; out_put: fput_light(sock->file, fput_needed); out: return err; out_fd: fput(newfile); put_unused_fd(newfd); goto out_put; } SYSCALL_DEFINE4(accept4, int, fd, struct sockaddr __user *, upeer_sockaddr, int __user *, upeer_addrlen, int, flags) { return __sys_accept4(fd, upeer_sockaddr, upeer_addrlen, flags); } SYSCALL_DEFINE3(accept, int, fd, struct sockaddr __user *, upeer_sockaddr, int __user *, upeer_addrlen) { return __sys_accept4(fd, upeer_sockaddr, upeer_addrlen, 0); }
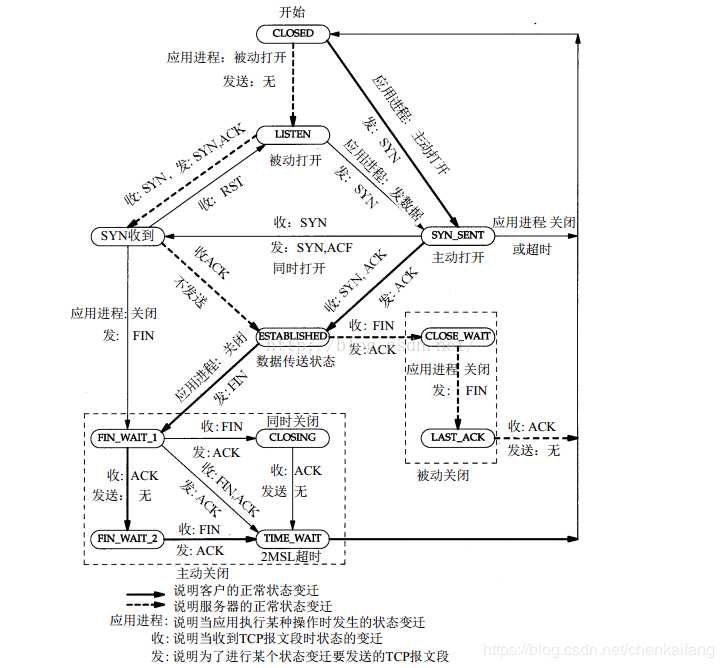
TCP服务器端依次调用socket()、bind()、listen()之后,就会监听指定的socket地址了。TCP客户端依次调用socket()、connect()之后就想TCP服务器发送了一个连接请求。TCP服务器监听到这个请求之后,就会调用accept()函数取接收请求,这样连接就建立好了。之后就可以开始网络I/O操作了,即类同于普通文件的读写I/O操作。
accept函数的第一个参数为服务器的socket描述字,第二个参数为指向struct sockaddr *的指针,用于返回客户端的协议地址,第三个参数为协议地址的长度。如果accpet成功,那么其返回值是由内核自动生成的一个全新的描述字,代表与返回客户的TCP连接。
以上五个系统调用函数阐述了TCP协议建立连接的过程。
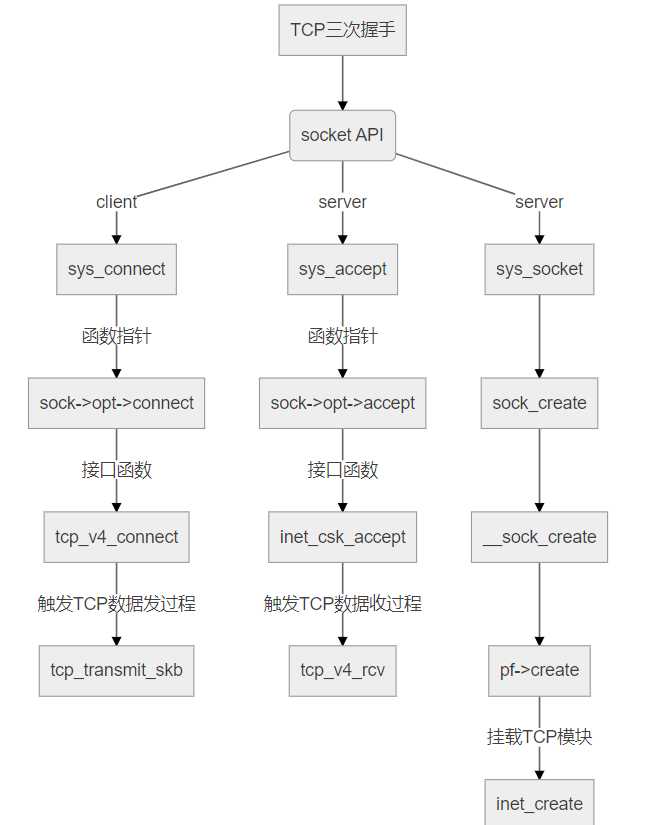
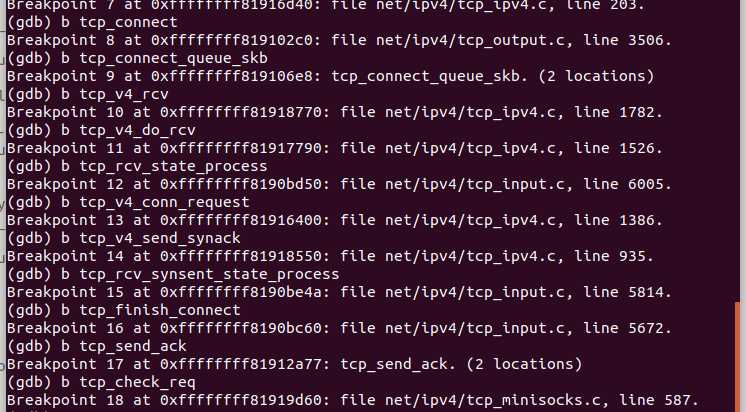
进一步分析TCP过程,可以通过对tcp_v4_connect,tcp_connect,tcp_transmit_skb,ip_queue_xmit,inet_csk_accept,tcp_v4_rcv,tcp_v4_do_rcv ,tcp_v4_conn_request,tcp_conn_request,tcp_rcv_state_process,tcp_rcv_synsent_state_process,tcp_send_ack,tcp_child_process以及tcp_set_state函数打上断点进行跟踪,找到这些函数源码所在的文件
实验总结:
通过本次实验,我对TCP协议连接过程的三次握手有了更深一步的了解。使用gdb调试代码,更进一步理解系统调用的原理,对Linux内核有了更加深刻的了解。同时也加深了对Linux Socket API的了解。尤其对TCP三次握手过程中socket,connect,bind,listen和accept函数有了更深刻的认识。总而言之,这次实验让我受益匪浅
参考资料:
https://baike.baidu.com/item/TCP/33012?fr=aladdin
https://www.cnblogs.com/cy568searchx/p/4211124.html
https://blog.csdn.net/u010073981/article/details/50734484
https://www.jianshu.com/p/ca0bbd8700ce
以上是关于深入理解TCP协议及其源代码的主要内容,如果未能解决你的问题,请参考以下文章