论文阅读总结:UniLM(Unified Language Model Pre-training for Natural Language Understanding and Generation)(
Posted gczr
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文阅读总结:UniLM(Unified Language Model Pre-training for Natural Language Understanding and Generation)(相关的知识,希望对你有一定的参考价值。
概述:
UniLM是微软研究院在Bert的基础上,最新产出的预训练语言模型,被称为统一预训练语言模型。它可以完成单向、序列到序列和双向预测任务,可以说是结合了AR和AE两种语言模型的优点,Unilm在抽象摘要、生成式问题回答和语言生成数据集的抽样领域取得了最优秀的成绩。
一、AR与AE语言模型
AR: Aotoregressive Lanuage Modeling,又叫自回归语言模型。它指的是,依据前面(或后面)出现的tokens来预测当前时刻的token,代表模型有ELMO、GTP等。
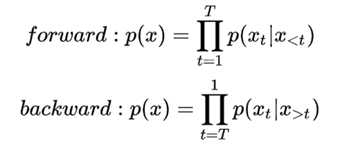
AE:Autoencoding Language Modeling,又叫自编码语言。通过上下文信息来预测当前被mask的token,代表有BERT ,Word2Vec(CBOW)。
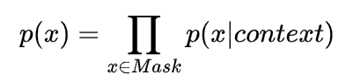
AR 语言模型:
- 缺点:它只能利用单向语义而不能同时利用上下文信息。 ELMO 通过双向都做AR 模型,然后进行拼接,但从结果来看,效果并不是太好。
- 优点: 对自然语言生成模型(NLG)友好,天然符合生成式任务的生成过程。这也是为什么 GPT 能够编故事的原因。
AE 语言模型:
- 缺点: 由于训练中采用了 [MASK] 标记,导致预训练与微调阶段不一致的问题。 此外对于生成式问题, AE 模型也显得捉襟见肘,这也是目前 BERT 为数不多实现大的突破的领域。
- 优点: 能够很好的编码上下文语义信息, 在自然语言理解(NLU)相关的下游任务上表现突出。
以上是关于论文阅读总结:UniLM(Unified Language Model Pre-training for Natural Language Understanding and Generation)(的主要内容,如果未能解决你的问题,请参考以下文章
论文阅读:You Only Look Once: Unified, Real-Time Object Detection
论文阅读Unified Pre-training for Program Understanding and Generation
论文阅读Unified Pre-training for Program Understanding and Generation
论文阅读Unified Pre-training for Program Understanding and Generation
论文阅读Unified Pre-training for Program Understanding and Generation
论文阅读CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding