论文阅读Unified Pre-training for Program Understanding and Generation
Posted 知识的芬芳和温柔的力量全都拥有的小王同学
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文阅读Unified Pre-training for Program Understanding and Generation相关的知识,希望对你有一定的参考价值。
目录

发表于NAACL 2021
paper地址:https://arxiv.org/pdf/2103.06333v2.pdf
代码地址:https://github.com/wasiahmad/PLBART
一、简介
文章提出的PLBART是一种序列到序列模型,能够执行广泛的程序和语言理解和生成任务。 PLBART 通过denoising autoencoding对大量 Java 和 Python 函数以及相关的 NL 文本进行了预训练。代码摘要、代码生成和七种编程语言代码翻译的实验表明,PLBART 优于或与最先进的模型相媲美。此外,在判别任务上的实验,例如程序修复、克隆检测和易受攻击的代码检测,证明了 PLBART 在程序理解方面的有效性。此外,分析表明 PLBART 学习程序语法、样式(例如,标识符命名约定)、逻辑流程(例如,else 块内的 if 块等效于 else if 块)对程序语义至关重要,因此即使在有限的注释下也表现的很好。
二、方法
PLBART基于BARTbase架构,使用seq2seq去噪预训练来利用PL和NL中的未标记数据,这里有三种噪声策略:标记屏蔽、标记删除和标记填充,将有噪音的序列输入encoder,原始序列加上位置偏移输入decoder,目标是去除噪声恢复原序列。
核心:denoising autoencoding
下游任务:Sequence Generation(source code summarization、generation 、translation)和Sequence Classification(克隆检测、检测代码是否易受攻击)
三、实验
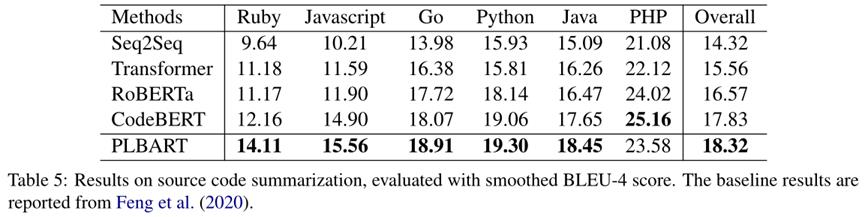
文中展示了一个PLBART生成的代码示例,虽然和参考代码不匹配,但是该代码在语法和语义上都是有效的,在语义上等同于参考代码:

然后作者还做了一个消融实验来研究PLBART在预训练或微调期间是否学习代码语法和逻辑流,结果表明(表6),PLBART能通过预训练学习到关键的程序特征,如语法、标识符命名约定、数据流,即使对少量示例进行微调,也能有效地执行下游任务。作者推测,PLBART的大规模序列到序列去噪预处理有助于理解程序语法和逻辑流程,从而使PLBART能够生成语法和逻辑上有效的代码。
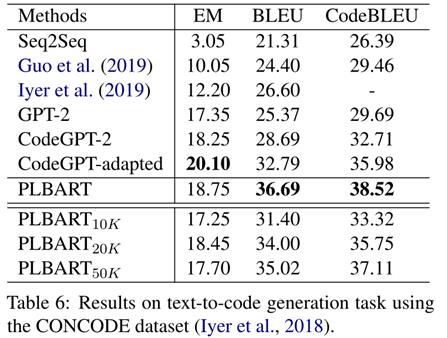

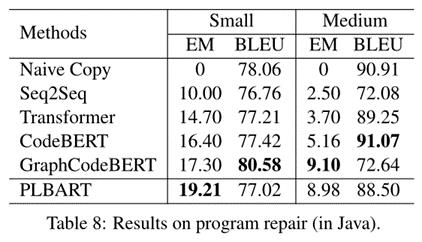
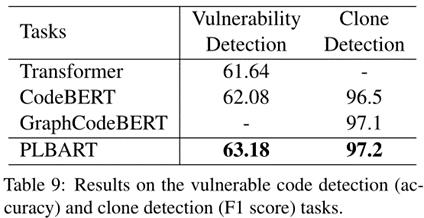
感觉文章整体思路不难,主要在预训练过程中加入了数据增强的方法,之后在各种下游任务上的性能都表现很好,验证了PLBART在程序理解上的有效性,还展示了一些样例来证明PLBART能通过预训练学习到关键的程序特征,如语法、标识符命名约定、数据流。
以上是关于论文阅读Unified Pre-training for Program Understanding and Generation的主要内容,如果未能解决你的问题,请参考以下文章