PP: Multi-Horizon Time Series Forecasting with Temporal Attention Learning
Posted dulun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PP: Multi-Horizon Time Series Forecasting with Temporal Attention Learning相关的知识,希望对你有一定的参考价值。
Problem:
multi-horizon probabilistic forecasting tasks;
Propose an end-to-end framework for multi-horizon time series forecasting, with temporal attention mechanisms to capture latent patterns.
Introduction:
forecasting ----- understanding demands.
traditional methods: arima, holt-winters methods.
recently: lstm
multi-step forecasting can be naturally formulated as sequence-to-sequence learning.
???? what is sequence-to-sequence learning
??? What is multi-horizon forecasting: forecasting on multiple steps in future time.
forecasting the overall distribution!!
quantile regression to make predictions of different quantiles to approximate the target distribution without making distributional assumptions;
mean regression/ least square method;
cite 29,31 produce quantile estimations with quantile loss functions.
RELATED WORK:
1. pre-assume underlying distribution
DeepAR makes probabilistic forecasts by assuming an underlying distribution for time series data, and could produce the probability density functions for target variables by estimating the distribution parameters on each point with multi-layer perceptrons.
2. quantile regressions: don‘t pre-assume underlying distribution, but generate quantile estimations for target variables.
Attention mechanism, cite 3.
APPROACH:
Use a LSTM-based encoder-decoder model;
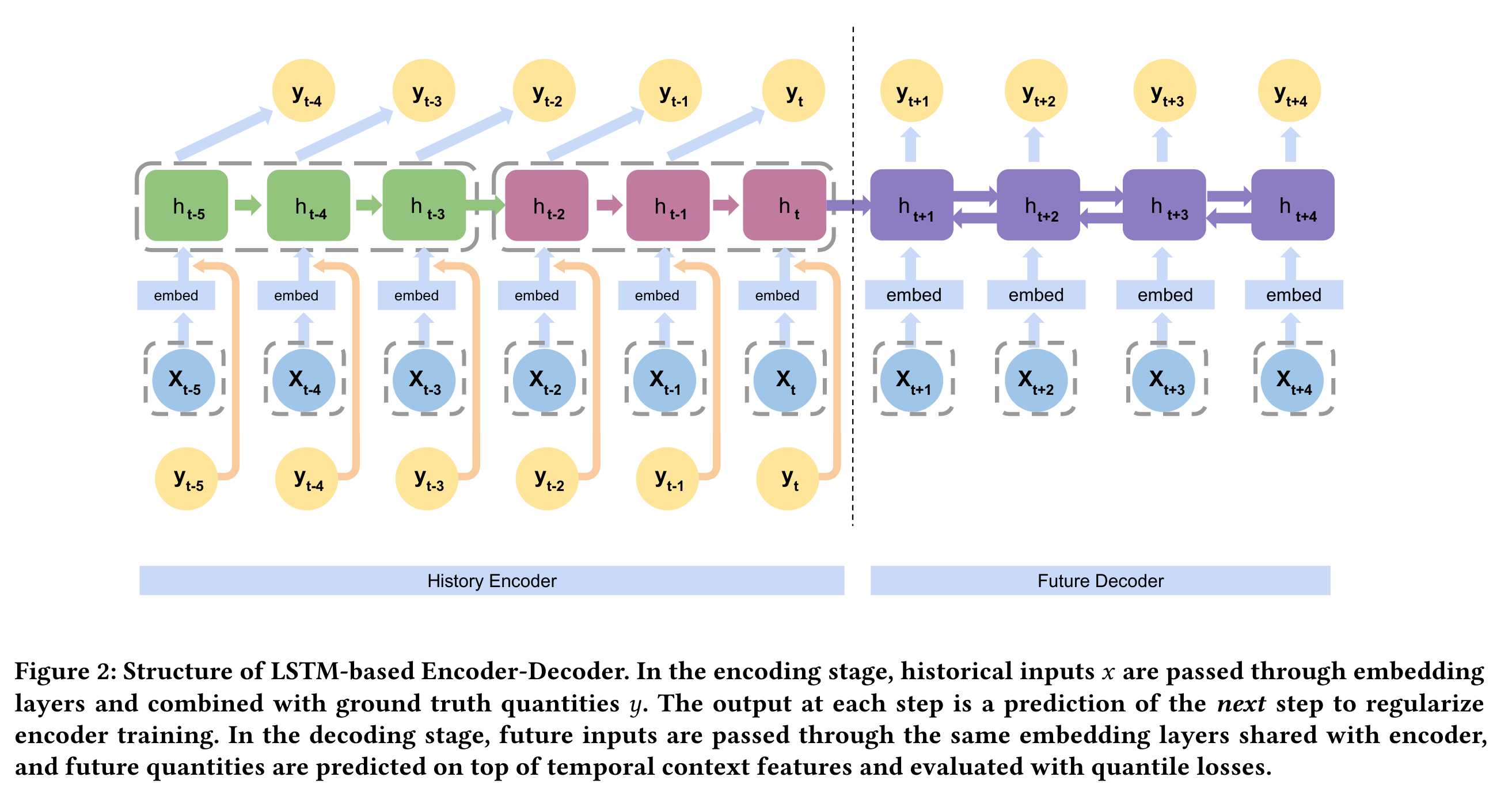
The decoder is another recurrent network which takes the encoded history as its initial state, and the future information as inputs to generate the future sequence as outputs. The decoder is bi-directional LSTM. Then the hidden states of BiLSTM are fed into a fully-connected layer/temporal convolution layer.
How to prevent error accumulation: we do not use prediction results of previous time steps to predict the current time step to prevent error accumulation.
???Hard to capture long-term dependency due to memory update. 为什么难以记录长期记忆,lstm本身就包含长期记忆啊,及时memory cell在不断的更新。
??How long the attention should be set? attending to a long history would lead to inaccurate attention as well as inefficient computation.
EXPERIMENTS
test on two datasets: public - GEFCom2014 electricity price forecasting dataset; JD50K sales dataset
multivariable time series: jd50k dataset include product region, category index, promotion type, and holiday event.
evaluate our algorithms with mean abosolute deviation平均绝对偏差, which is defined as the sum of standard quantile loss.
L(yip,?yi)?=?max[q(yip?−?yi),??(q?−?1)(yip?−?yi)]
Training and test Part: 时序数据是纵向切分的,时序数据的前时间段作为训练部分,后时间段作为测试部分。
结果: 和别的方法来比较quantile loss,提升了0.2-0.8,但是loss的最大尺度不知道,所以不知道这个0.2-0.8到底意味着多大的尺度。用MSE loss来评估,还不错,小了很多。如果是点预测的话,可以直接和真实值进行比较,但是quantile estimation就不好衡量准确性了,或者说我目前不知道对应的衡量方法。作者测试了temporal attention width, h = 1和3两个值,这个值的选取需要更多的justify.
me: 和modeling extreme event 那篇文章相比,二者同样添加了attention mechanism, 但二者的不同在与,extreme event那篇文章应用了fixed windows生成固定长度的extreme event 的attention,独立于hidden state 之外,输入是整个序列的extreme event发生与否,而本篇文章的attention是对过去数据h个hidden states的attention记录。相比之下本篇文章的网络设计技巧性更强。但如果说网络结构的创新性,如果biLSTM encoder-decoder本身存在的话,那么本文的贡献只有temporal attention mechanism. 另一个思考是,不同类型的time series,之间的自相关性不同,能不能根据它们的自相关性进行temporal attention width - h的选取标准。越自相关,越被之前的数值影响,因而更需要前面的temporal attention.
Supplementary knowledge:
?? what is temporal attention mechanism and multi-horizon time series.
以上是关于PP: Multi-Horizon Time Series Forecasting with Temporal Attention Learning的主要内容,如果未能解决你的问题,请参考以下文章
Temporal Fusion Transformersfor Interpretable Multi-horizon Time Series Forecasting代码解读(tensoreflow)
PP: Learning representations for time series clustering
PP: Modeling extreme events in time series prediction
PP: Imaging time-series to improve classification and imputation
PP: Toeplitz Inverse Covariance-Based Clustering of Multivariate Time Series Data
PP: Soft-DTW: a differentiable loss function for time-series