Temporal Fusion Transformersfor Interpretable Multi-horizon Time Series Forecasting代码解读(tensoreflow)
Posted hxtyy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Temporal Fusion Transformersfor Interpretable Multi-horizon Time Series Forecasting代码解读(tensoreflow)相关的知识,希望对你有一定的参考价值。
论文来源:https://arxiv.org/pdf/1912.09363.pdf
代码来源:google-research/tft at master · google-research/google-research · GitHub
目录
5、def gated_residual_network()
7、class ScaledDotProductAttention()
8、 class InterpretableMultiHeadAttention()
9、class TemporalFusionTransformer()
15、……接下来的诸如predict函数都是一般神经网络的基本步骤,没什么特殊(我也写不动了)。
2.5 script_train_fixed_params.py
1、框架介绍
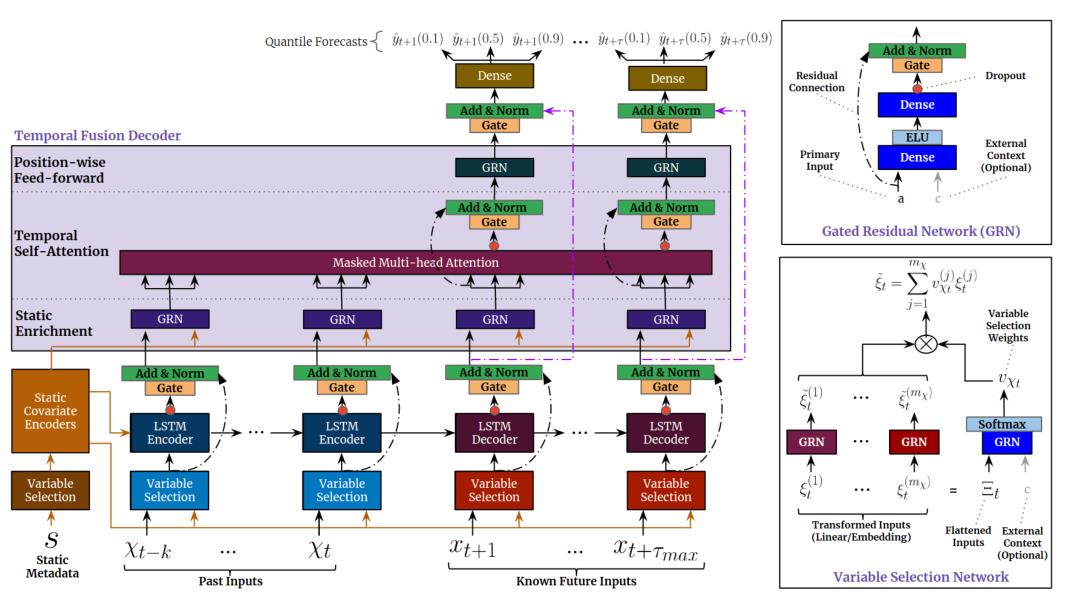
框架的话,我直接粘了论文的原图。
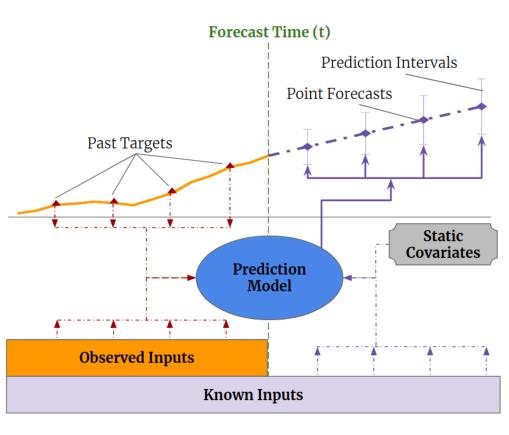
TFT用于时序预测,也有异常预测等具体应用。
如上图,TFT将原始的时序数据分解为三部分:Observed_Inputs、Known_Inputs、Static_inputs。其中Observed_Inputs(已观测输入)即历史KPI数据,且已知这些数据的Target(输出);Known_Inputs指所有条目都已知的数据(包括历史的以及接下来需要预测的),例如时间戳;Static_Inputs指静态输入,本人理解为离散输入,对预测结果的影响不大的输入,比如CPU占用率数据中的计算机类别ID。
简单地介绍一下用上述三个数据完成异常预测:首先将数据集分割为上述三部分,其次分别训练历史已观测输入、历史已知数据与历史静态输入 学习得到 目标输出(异常标签),测试过程中输入已知数据,通过已学习得的静态输入与已观测输入的特征矩阵,预测相应输出。
看到这里,相信大家一定也有很多具体实现的疑惑,下面将通过代码介绍具体框架介绍。
2、代码详解
打开script_download_data.py与script_train_fixed_params.py,将其中add_argument函数中expt_name的default设置为electricity(或其他),运行script_download_data.py下载数据集,运行script_train_fixed_params.py实现TFT。
2.1 tensorflow环境要求
因为这里的代码是由tensorflow1版本完成的,而现在大部分使用的都是tensorflow2。因此,需要对调用的tensorflow代码进行相应更改。
(1)更改 import tensorflow as tf
import tensorflow.compat.v1 as tf
(2)model文件头添加:
tf.compat.v1.experimental.output_all_intermediates(True)
说实话,这是代码报错后要求的,我也不知道什么原理,有机会再调研一下。
2.2 文件夹框架
data_formatters文件夹主要完成文件的下载与预处理
expt_settings文件夹完成各种参数的配置,前期不需要太关注
libs文件夹中tft_model.py文件实现神经网络框架的搭建
script_download_data.py 下载原始数据集,script_train_fixed_params.py 运行默认参数的TFT,script_hyperparam_opt.py是具体调参的TFT实现。
script_download_data.py较简单,不做详解,具体介绍script_train_fixed_params.py中TFT的实现流程。
2.3 数据结构
传统数据集由时间戳、KPI具体值与输出值等组成。data_formatters文件夹的favorita.py等实现原始数据集的预处理。
去除时间戳与序号后的数据列可分为以下几类:
列为输入类型,行为数据类型
| observed_input | known_input | target | static | |
| real_value | ||||
| category |
2.4 tft_model.py框架搭建
这里,我们一个函数一个函数讲。
1、def linear_layer()
定义Dense线性层。但相比Dense,增加了一个TimeDistributed层,在每个时间步上均操作Dense。
2、apply_mlp()
定义两层Dense,MLP多层感知器。
3、def apply_gating_layer()
定义GLU门限单元,这个在论文中有提到:
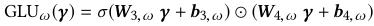
具体操作即Dropout后,分别定义激活函数为sigmoid与无激活函数的Dense层,将两Dense层的输出矩阵相乘即获得门限单元。
门限单元的作用即门限,相当于给变量加一个阀门,乘以一个系数(非线性)。
4、def add_and_norm()
残差与归一化网络。防止过拟合。
5、def gated_residual_network()
定义GRN门限残差网络,属于门限装置。
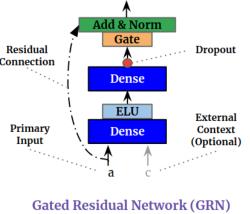
输入先通过 linear_layer()函数定义的Dense层,使用ELU指数激活函数后,再通过linear_layer()函数定义的Dense层,apply_gating_layer()函数定义的门限层,最后经过残差与归一化网络输出。其作用相当于主成分分析,提取有效特征。
如果还输入了上下文特征矩阵c,a、c同时通过Dense层得到两个特征矩阵后相加。其作用大致相当于同时提取有效(对输出有影响)的上下文特征。
6、def get_decoder_mask()
相当与大名鼎鼎的Transformer中的looking_ahead_masking层。因为在实际情况中,一条数据的数据只受历史与当前数据的影响,而与未来状态无影响。因此,我们需要一个矩阵用来盖住下文特征。而该函数创建了一个上三角为1的矩阵,乘以负无穷,加在特征矩阵上后,使第i条数据输出,只受前i-1条数据的影响,之后数据的影响为0,参数为负无穷。

7、class ScaledDotProductAttention()
实现自注意力机制。
self_attention的实现这里不细讲。主要流程为:
- Q(uary)、K(ey)、V(alue)取相同值
- Q、K矩阵相乘,再除以维度的根号,得到序列内部子注意力系数矩阵
- 子注意力系数与V相乘,得到自注意力矩阵
8、 class InterpretableMultiHeadAttention()
可解释的多头自注意力机制的实现。
在我看来,这里的可解释值的是多头的可解释:在传统的多头自注意力机制中,我们将多维的数据切割为单维,每维的数据都投入神经网络,得到各自自注意力矩阵,再将多个矩阵合成单个矩阵,但问题是,我们无法解释每维数据得到的矩阵代表着什么,因为输入的仅是矩阵的一维,我们无法将输出作为数据整体的子注意力的一部分,这是不可解释的。而论文的创新点在于不再将矩阵切成n维后分别投入,而是通过Dense层得到单维的特征矩阵,再投入自注意力机制。
这个方法使矩阵的输入变得合理,有一定的解释性。本来,我想专门调研以下可解释性的Transformer的,但导师说神经网络可解释性的水太深,不是我一个本科生能把握住的~-~。
9、class TemporalFusionTransformer()
这里是TFT的具体搭建。
(1)__init__函数
实现各种参数的初始化与赋值。
(2)def get_tft_embeddings(self, all_inputs)函数
目的在于规范化各项输入,嵌入相同的维度。all_inputs格式为(None, 192, 5)。
首先,检查预处理数据,可观测数据中不含输出,可观测数据不是静态量,以及输入格式相符。
其次,创建embeddings层,处理每个category列(None,192,1)->(None, 192, 5)。
再次,生成静态输入,取每个滑动窗口每个static列的第一个数据(None,1),以Dense层转化为(None,5),与上述category列[:, 0, :]相加,得到静态输入[None,5]。reshape为[None,1,5]
再次,处理输出格式,取每个滑动窗口每个target列(None, 192, 1),通过Dense层生成
(None, 192, 5) ,reshape为(None, 192, 5,1) 。
再次,生成可观测输入,取每个滑动窗口中的category列中的observed列(None,192,1),embedding为(None,192,5);取每个滑动窗口中的real_value列中的observed列(None,192,1),embedding为(None,192,5),将两者连接reshape(None,192,5,1)。
再次,生成已知输入,分别取每个滑动窗口中real_value与category列的known_input列(None,192,1)embedding为(None,192,5);数组连接将两者reshape(None,192,5,1)。
最后,返回可观测输入,已知输入,输出,静态输入。
10、def _batch_sampled_data()等
将预处理数据切割为batch,具体不做详解。
inputs = np.zeros((max_samples, self.time_steps, self.input_size))
outputs = np.zeros((max_samples, self.time_steps, self.output_size))
time = np.empty((max_samples, self.time_steps, 1), dtype=object)
identifiers = np.empty((max_samples, self.time_steps, 1), dtype=object)11、def _build_base_graph()
构建TFT的神经网络框架。
首先,规定输入格式: all_inputs = (None,time_steps,combined_input_size)(None,192,5)。
其次,调用get_tft_embedding函数生成各种输入。
再次,将未知输入,已知输入,输出连接为known_combined_layer:(None,192,5,1) -> (None,192,5,3)。
再次,取known_combined_layer与obs_inputs每个滑动窗口的前encoder_steps个数据historical_inputs 作为编码器的输入,取known_combined_layer每个滑动窗口的剩余数据future_inputs 作为解码器的输入。
11.1 def static_combine_and_mask(embedding)
该函数用于静态协变量的变量选择,选择对输出造成影响的协变量。
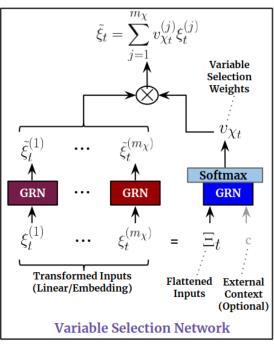
其中参数embedding为生成的静态输入,格式为[None,1,5],即每个滑动窗口用一个五维的特征矩阵表示静态特征。
首先,调用Flatten函数展开静态输入[None,1,5]->[None,5]。
其次,调用gated_residual_network函数,提取Flattened_Inputs中的有效输入,并以softmax作为激活函数,输出[None,1],再expand_dims为sparse_weights[None,num_static,1]。
再次,对embedding[:, i:i + 1, :]即每个滑动窗口的每行静态特征,取其第三维调用 gated_residual_network函数,输出[None,1,5]后重新组合为原来格式transformed_embedding[None,num_static,feature]。
最后,sparse_weights与transformed_embedding矩阵相乘取和,提取出有效静态变量。
static_inputs 调用 static_combine_and_mask 函数获得静态编码与静态权重static_encoder, static_weights。
最后,对静态编码调用gated_residual_network函数,获得静态变量选择器static_context_variable_selection。[None,5]->[None,5]
11.2 def lstm_combine_and_mask(embedding)
该函数是框架利用LSTM层提取局部上下文特征的前置工作。其中embedding为历史合成输入historical_inputs。
首先,reshape historical_inputs为flatten:
[None,time_steps,embedding_dim,num_inputs]->[None,time_steps,embedding_dim*num_inputs]
[Noen,192,5,4]->[None,192,20]
其次,对静态变量选择器static_context_variable_selection调用expand_dims函数:
[None,5]->[None,1,5]
再次,对flatten调用Variable selection weights框架,其中additional_context = expanded_static_context,旨在提取flatten中的静态有效变量,最终得到temporal_ctx[None,5]。
分别对historical_inputs与future_inputs调用lstm_combine_and_mask函数,得到historical_features与future_features。
11.3 get_lstm(return_state)
该函数旨在用LSTM提取局部的上下文特征。
函数基本方式为调用 tf.keras.layers.LSTM()函数,通过设置不同参数,实现LSTM。
分别对historical_features与future_features调用get_lstm函数。historical_features_LSTM的初始状态为静态变量选择器,return_state=True;future_features_LSTM的初始状态为historical_features_LSTM的输出状态,return_state=False。连接history_lstm与future_lstm为lstm_layer。
连接history_feature与future_feature为input_embeddings,调用apply_gating_layer与add_and_norm函数,生成跳过LSTM的输出temporal_feature_layer。
对temporal_feature_layer调用gated_residual_network函数,实现静态变量的富集 ,其中additional_context为expand_dims的静态变量选择器[None,5]->[None,1,5]。
提取mask层后,对输出调用可解释的多头自注意力机制,再分别调用apply_gating_layer与add_and_norm函数解码。
最后,根据结构图,经过GRN、Gate、add&norm,获得最终输出层transformer_layer。
12、def build_model(self)
这是构建TFT的主函数。
_build_base_graph函数搭建神经网络,生成输出层transformer_layer,再通过Dense函数生成相应格式输出。再设置Adam优化器,最后建立model:
model = tf.keras.Model(inputs=all_inputs, outputs=outputs)
调用utils.tensorflow_quantile_loss函数建立损失,compile函数编译模型。
model.compile(
loss=quantile_loss, optimizer=adam, sample_weight_mode='temporal')13、def fit(self)
这里不作细讲,大概就是预处理原始数据后调用fit函数拟合模型。
14、def evaluate(self)
用于评估预测的结果,因与大部分模型大致相同,这里也不作细讲。
15、……接下来的诸如predict函数都是一般神经网络的基本步骤,没什么特殊(我也写不动了)。
2.5 script_train_fixed_params.py
该文件主要调用tft.model中的各种函数实现流程,大致相当于一个调用的主函数。
3、总结
说是时序预测,但在我看来,TFT的设计天生就是为了异常预测。
而TFT的优势,主要体现在其GRN类似主成分分析的特征筛选以及可解释的多头自注意力机制。可解释性还没完全搞懂,而其GRN作为门限装置,在TFT更似于代替了Dense层,但相比Dense层,提取了有效成分,提高了模型的性能和学习效率。
总的来说,TFT就是应用了GRN的LSTM-Transformer编码器-解码器模型。能够有效提取KPI中的重要成分,分析局部与总体上下文关系,并一定程度上避免了梯度消失问题,以及多头自注意力机制的可解释性问题(虽然他说的挺有道理,但我无论怎么看,Self-Attention还是不可解释的)
以上是关于Temporal Fusion Transformersfor Interpretable Multi-horizon Time Series Forecasting代码解读(tensoreflow)的主要内容,如果未能解决你的问题,请参考以下文章
论文精读Temporal Fusion Transformers for Interpretable Multi-horizon Time Series Forecasting
Temporal Fusion Transformersfor Interpretable Multi-horizon Time Series Forecasting代码解读(tensoreflow)