字典树 && 例题 Xor Sum HDU - 4825 (板子)
Posted kongbursi-2292702937
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了字典树 && 例题 Xor Sum HDU - 4825 (板子)相关的知识,希望对你有一定的参考价值。
Trie树,即字典树,又称单词查找树或键树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计
和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:最大
限度地减少无谓的字符串比较,查询效率比哈希表高。
它有3个基本性质:
2、从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
3、每个节点的所有子节点包含的字符都不相同。
问题:
有一个存放英文单词的文本文件,现在需要知道某些给定的单词是否在该文件中存在,若存在,它又出现了多少次?
解法一:
如果将所有的单词都存放在一个map中,每次查找的时间复杂度则降为O(log(n))。
假设所有字符串长度之和为n,构建字典树的时间复杂度为O(n)。假设要查找的字符串长度为k,查找的时间复杂度为:
O(k)(也相当于O(1))。
题目:给你100000个长度不超过10的单词。对于每一个单词,我们要判断他出没出现过,如果出现了,求第一次出现在第几个位置。
分析:这题当然可以用hash来解决,但是本文重点介绍的是trie树,因为在某些方面它的用途更大。比如说对于某一个单词,我们要询问它的前缀是否出现过。这样hash就不好搞了,而用trie还是很简单。
现在回到例子中,如果我们用最傻的方法,对于每一个单词,我们都要去查找它前面的单词中是否有它。那么这个算法的复杂度就是O(n^2)。显然对于100000的范围难以接受。现在我们换个思路想。假设我要查询的单词是abcd,那么在他前面的单词中,以b,c,d,f之类开头的我显然不必考虑。而只要找以a开头的中是否存在abcd就可以了。同样的,在以a开头中的单词中,我们只要考虑以b作为第二个字母的,一次次缩小范围和提高针对性,这样一个树的模型就渐渐清晰了。
好比假设有b,abc,abd,bcd,abcd,efg,hii 这6个单词,我们构建的树就是如下图这样的:
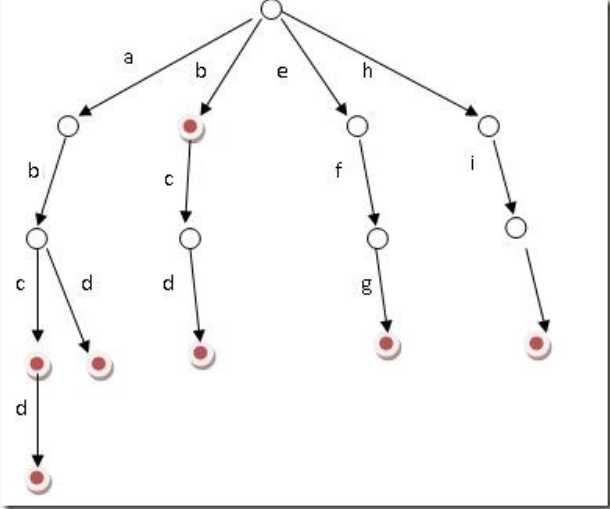
如上图所示,对于每一个节点,从根遍历到他的过程就是一个单词,如果这个节点被标记为红色,就表示这个单词存在,否则不存在。
那么,对于一个单词,我只要顺着他从根走到对应的节点,再看这个节点是否被标记为红色就可以知道它是否出现过了。把这个节点标记为红色,就相当于插入了这个单词。
这样一来我们查询和插入可以一起完成(重点体会这个查询和插入是如何一起完成的,稍后,下文具体解释),所用时间仅仅为单词长度,在这一个样例,便是10。
我们可以看到,trie树每一层的节点数是26^i级别的。所以为了节省空间。我们用动态链表,或者用数组来模拟动态。空间的花费,不会超过单词数×单词长度。
四、Trie树应用:
除了本文引言处所述的问题能应用Trie树解决之外,Trie树还能解决下述问题(节选自此文:海量数据处理面试题集锦与Bit-map详解):
- 3、有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。
- 9、1000万字符串,其中有些是重复的,需要把重复的全部去掉,保留没有重复的字符串。请怎么设计和实现?
- 10、 一个文本文件,大约有一万行,每行一个词,要求统计出其中最频繁出现的前10个词,请给出思想,给出时间复杂度分析。
- 13、寻找热门查询:搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。假设目前有一千万个记录,这些查询串的重复读比较高,虽然总数是1千万,但是如果去除重复和,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就越热门。请你统计最热门的10个查询串,要求使用的内存不能超过1G。
(1) 请描述你解决这个问题的思路;
(2) 请给出主要的处理流程,算法,以及算法的复杂度。
对于不同的题目可以改变字典树节点维护的信息来完成求解
五、例题讲解
Input
输入包含若干组测试数据,每组测试数据包含若干行。
输入的第一行是一个整数T(T < 10),表示共有T组数据。
每组数据的第一行输入两个正整数N,M(<1=N,M<=100000),接下来一行,包含N个正整数,代表 Zeus 的获得的集合,之后M行,每行一个正整数S,代表 Prometheus 询问的正整数。所有正整数均不超过2^32。
Output
对于每组数据,首先需要输出单独一行”Case #?:”,其中问号处应填入当前的数据组数,组数从1开始计算。
对于每个询问,输出一个正整数K,使得K与S异或值最大。Sample Input
2 3 2 3 4 5 1 5 4 1 4 6 5 6 3
Sample Output
Case #1: 4 3 Case #2: 4
题解:
对于先输入的n个数,先用他们的二进制构建一颗字典树。然后对于m次询问的数x,每一次尽量走与x那一个二进制位相反值的节点(走的时候是从二进制高位向低位走)
代码有解释
代码:
1 #include <iostream> 2 #include <cstdio> 3 #include <cstring> 4 #include <cstdlib> 5 #include <algorithm> 6 using namespace std; 7 typedef struct Trie* TrieNode; //注意这一行,下面如果用TrieNode声明的变量都是Trie类型的指针变量 8 struct Trie 9 { 10 int val; 11 TrieNode next[2]; 12 Trie() 13 { 14 val = 0; 15 memset(next,NULL,sizeof(next)); 16 } 17 }; 18 19 void inserts(TrieNode root,int x) //按照x这个数的二进制位从高位向低位建树 20 { 21 TrieNode p = root; 22 for(int i=31 ; i>=0 ; i--) 23 { 24 int t = (x>>i)&1; 25 if(p->next[t] == NULL)p->next[t] = new struct Trie(); 26 p = p->next[t]; 27 } 28 p->val = x; 29 } 30 31 int query(TrieNode root,int x) 32 { 33 TrieNode p = root; 34 for(int i=31 ; i>=0 ; i--) 35 { 36 int t = ((x>>i)&1)^1; //因为我们要让最后异或的答案尽可能地大,又因为异或运算是:“相同为0,不同为1” 37 //又因为我们是从高位开始搜索,二进制数(10000)要大于二进制数(01111),所以我们要尽量走(!(x>>i)&1)那一个 38 //节点。只有这一个节点不能走才会去走((x>>i)&1)这个节点 39 //((x>>i)&1)代表的就是x的二进制中第i位的值 40 if(p->next[t] == NULL)t = (x>>i)&1; 41 if(p->next[t])p = p->next[t]; 42 else return -1; //走到了尽头就可以结束了 43 } 44 return p->val; 45 } 46 47 void Del(TrieNode root) //用完要删除树的每一个节点 48 { 49 for(int i=0 ; i<2 ; ++i) 50 { 51 if(root->next[i])Del(root->next[i]); 52 } 53 delete(root); 54 } 55 56 int main() 57 { 58 int t,n,m,p=0; 59 scanf("%d",&t); 60 while(t--) 61 { 62 printf("Case #%d: ",++p); 63 TrieNode root = new struct Trie(); 64 scanf("%d %d",&n,&m); 65 for(int i=0 ; i<n ; ++i) 66 { 67 int t; 68 scanf("%d",&t); 69 inserts(root,t); 70 } 71 for(int i=0 ; i<m ; ++i) 72 { 73 int t; 74 scanf("%d",&t); 75 int m = query(root,t); 76 printf("%d ",m); 77 } 78 Del(root); 79 } 80 return 0; 81 }
以上是关于字典树 && 例题 Xor Sum HDU - 4825 (板子)的主要内容,如果未能解决你的问题,请参考以下文章