word2vec原理推导
Posted nxf-rabbit75
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了word2vec原理推导相关的知识,希望对你有一定的参考价值。
word2vec作为神经概率语言模型的输入,其本身其实是神经概率模型的副产品,是为了通过神经网络学习某个语言模型而产生的中间结果。具体来说,“某个语言模型”指的是“CBOW”和“Skip-gram”。具体学习过程会用到两个降低复杂度的近似方法——Hierarchical Softmax或Negative Sampling。两个模型乘以两种方法,一共有四种实现。
一、CBOW
1.一个单词上下文
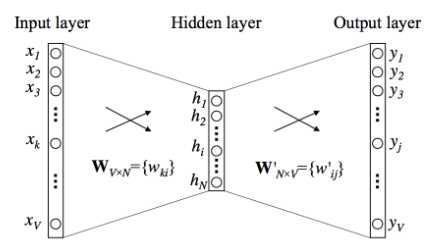
2.参数更新
3.多个单词上下文
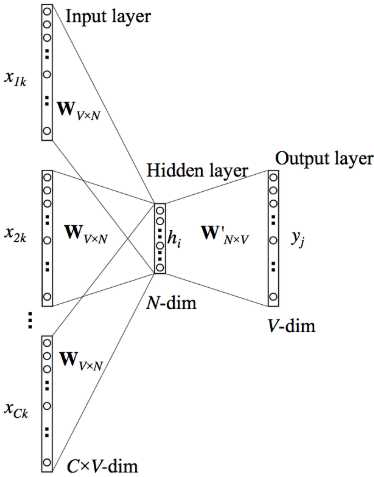
二、Skip-gram
1.网络结构
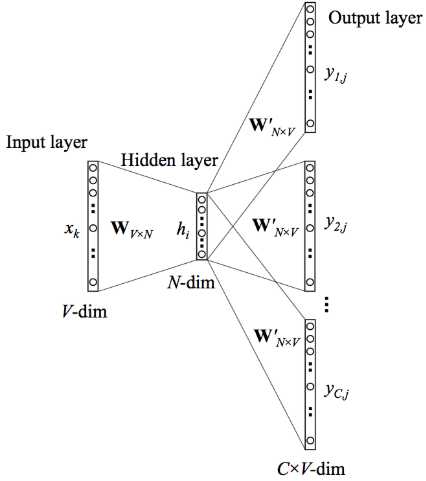
2.参数更新
三、优化
原始的CBOW模型和Skip-Gram 模型的计算量太大,非常难以计算。
- 模型在计算网络输出的时候,需要计算误差 。对于CBOW 模型,需要计算V个误差(词汇表的大小),对于 Skip-Gram 模型,需要计算CV个误差。 另外,每个误差的计算需要用到 softmax 函数,该 softmax 函数涉及到O(V)复杂度的运算:$sum _{j=1} ^ V exp(u_j)$ 。
- 每次梯度更新都需要计算网络输出。 如果词汇表有 100万 单词,模型迭代 100 次,则计算量超过 1 亿次。
虽然输入向量的维度也很高,但是由于输入向量只有一位为 1,其它位均为 0,因此输入的总体计算复杂度较小。
word2vec 优化的主要思想是:限制输出单元的数量。
事实上在上百万的输出单元中,仅有少量的输出单元对于参数更新比较重要,大部分的输出单元对于参数更新没有贡献。
有两种优化策略:
- 通过分层softmax来高效计算softmax函数。
- 通过负采样来缩减输出单元的数量。
1.分层softmax
分层 softmax 是一种高效计算 softmax 函数的算法。 经过分层 softmax 之后,计算 softmax 函数的算法复杂度从O(V)降低到O(logV) ,但是仍然要计算V-1个内部节点的向量表达 。
(1)CBOW
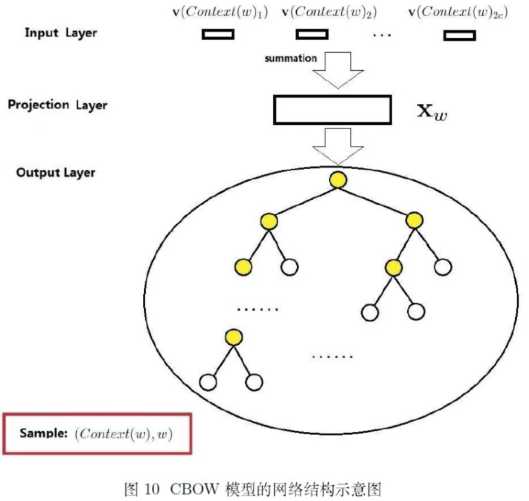
(2)Skip-gram
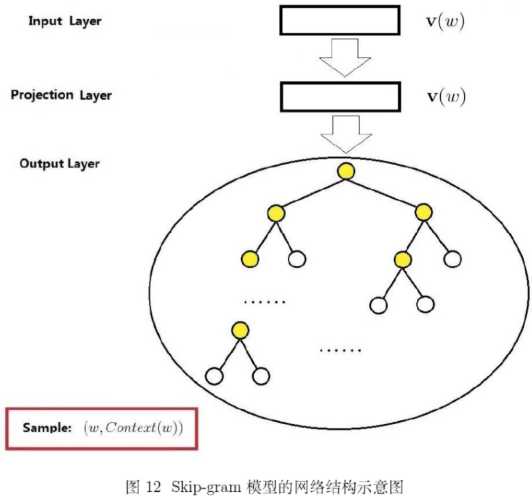
2.负采样
在网络的输出层,真实的输出单词对应的输出单元作为正向单元,其它所有单词对应的输出单元为负向单元。
- 正向单元的数量为1,毋庸置疑,正向单元必须输出。
- 负向单元的数量为V-1,其中V为词表的大小,通常为上万甚至百万级别。如果计算所有负向单元的输出概率,则计算量非常庞大。可以从所有负向单元中随机采样一批负向单元,仅仅利用这批负向单元来更新。这称作负采样。
负采样的核心思想是:利用负采样后的输出分布来模拟真实的输出分布。
参考链接:
【1】word2vec原理(一) CBOW与Skip-Gram模型基础
【3】Hierarchical Softmax(层次Softmax) - 知乎
以上是关于word2vec原理推导的主要内容,如果未能解决你的问题,请参考以下文章