word2vec算法原理
Posted AI算法攻城狮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了word2vec算法原理相关的知识,希望对你有一定的参考价值。
word2vec 是 Google 于 2013 年开源推出的一个用于获取词向量(word vector)的工具包,它简单、高效,因此引起了很多人的关注。
1.单词的向量化表示
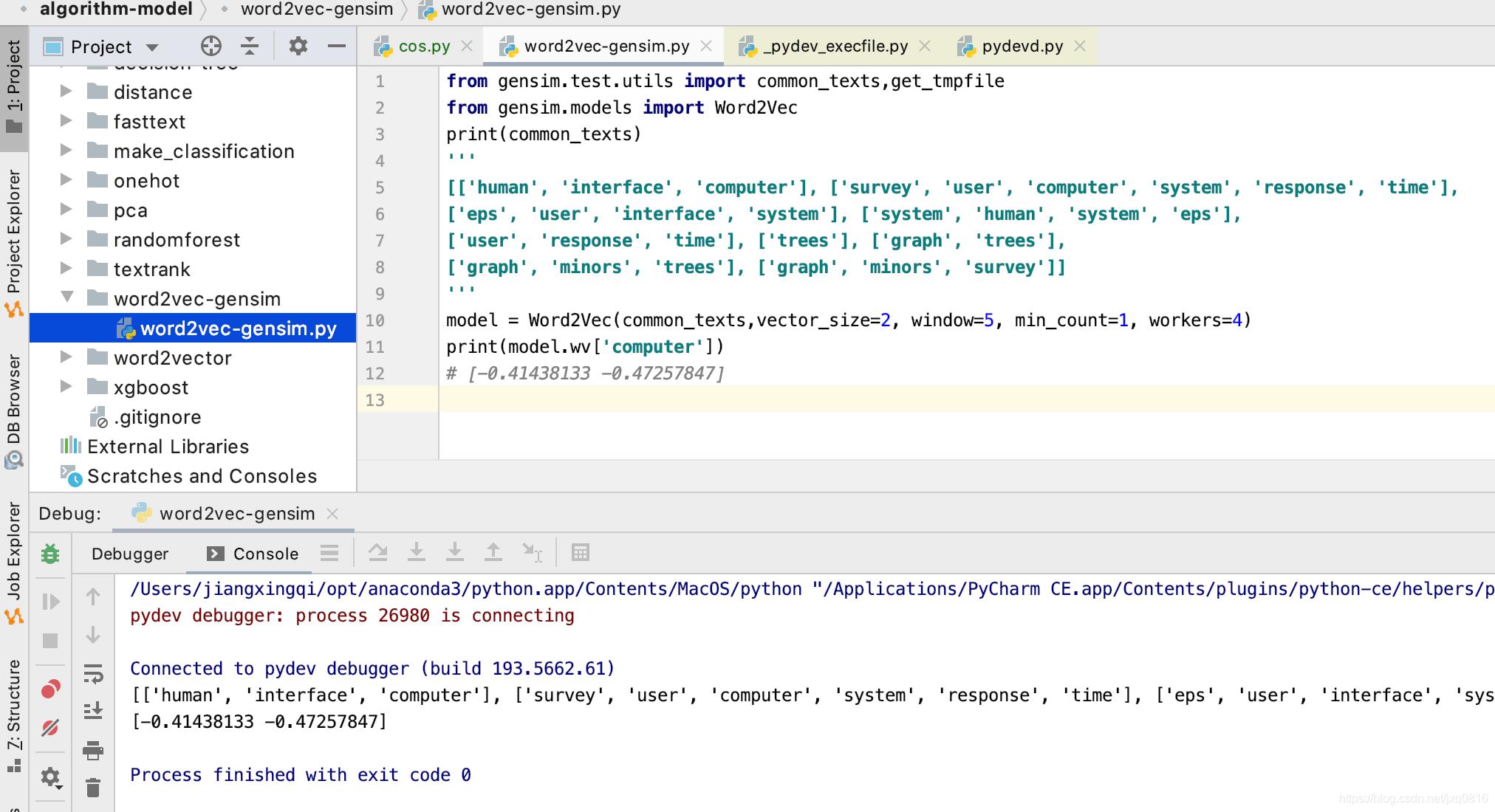
官方链接
https://radimrehurek.com/gensim/models/word2vec.html#gensim.models.word2vec.Text8Corpus
所谓的word vector,就是指将单词向量化,将某个单词用特定的向量来表示。将单词转化成对应的向量以后,就可以将其应用于各种机器学习的算法中去。一般来讲,词向量主要有两种形式,分别是稀疏向量和密集向量。
所谓稀疏向量,又称为one-hot representation,就是用一个很长的向量来表示一个词,向量的长度为词典的大小N,向量的分量只有一个1,其他全为0,1的位置对应该词在词典中的索引[1]。举例来说,如果有一个词典[“面条”,”方便面”,”狮子”],那么“面条”对应的词向量就是[1,0,0],“方便面”对应的词向量就是[0,1,0]。这种表示方法不需要繁琐的计算
以上是关于word2vec算法原理的主要内容,如果未能解决你的问题,请参考以下文章
深度学习方法(十七):word2vec算法原理:跳字模型(skip-gram) 和连续词袋模型(CBOW)