泰坦尼克号问题
Posted cmybky
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了泰坦尼克号问题相关的知识,希望对你有一定的参考价值。
学习了机器学习这么久,第一次真正用机器学习中的方法解决一个实际问题,一步步探索,虽然最后结果不是很准确,仅仅达到了0.78647,但是真是收获很多,为了防止以后我的记忆虫上脑,我决定还是记录下来好了。
1,看到样本是,查看样本的分布和统计情况
#查看数据的统计信息
print(data_train.info())
#查看数据关于数值的统计信息
print(data_train.describe())
通常遇到缺值的情况,我们会有几种常见的处理方式
- 如果缺值的样本占总数比例极高,我们可能就直接舍弃了,作为特征加入的话,可能反倒带入noise,影响最后的结果了,或者考虑有值的是一类,没有值的是一类,
- 如果缺值的样本适中,而该属性非连续值特征属性(比如说类目属性),那就把NaN作为一个新类别,加到类别特征中
- 如果缺值的样本适中,而该属性为连续值特征属性,有时候我们会考虑给定一个step(比如这里的age,我们可以考虑每隔2/3岁为一个步长),然后把它离散化,之后把NaN作为一个type加到属性类目中。
- 有些情况下,缺失的值个数并不是特别多,那我们也可以试着根据已有的值,拟合一下数据,补充上。
随机森林的方法用来填充数据

from sklearn.ensemble import RandomForestRegressor
### 使用 RandomForestClassifier 填补缺失的年龄属性
def set_missing_ages(df):
# 把已有的数值型特征取出来丢进Random Forest Regressor中
age_df = df[[‘Age‘,‘Fare‘, ‘Parch‘, ‘SibSp‘, ‘Pclass‘]]
# 乘客分成已知年龄和未知年龄两部分
known_age = age_df[age_df.Age.notnull()].as_matrix()
unknown_age = age_df[age_df.Age.isnull()].as_matrix()
# y即目标年龄
y = known_age[:, 0]
# X即特征属性值
X = known_age[:, 1:]
# fit到RandomForestRegressor之中
rfr = RandomForestRegressor(random_state=0, n_estimators=2000, n_jobs=-1)
rfr.fit(X, y)
# 用得到的模型进行未知年龄结果预测
predictedAges = rfr.predict(unknown_age[:, 1::])
# 用得到的预测结果填补原缺失数据
df.loc[ (df.Age.isnull()), ‘Age‘ ] = predictedAges
return df, rfr
def set_Cabin_type(df):
df.loc[ (df.Cabin.notnull()), ‘Cabin‘ ] = "Yes"
df.loc[ (df.Cabin.isnull()), ‘Cabin‘ ] = "No"
return df
data_train, rfr = set_missing_ages(data_train)
data_train = set_Cabin_type(data_train)
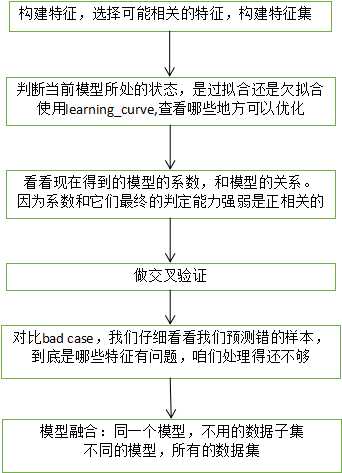
2,接下来就是特征工程了,这一步比较复杂,就是选择特征,
特征工程的处理方法包括很多种,可以在我的特征工程的博客中找到。
随机森林特征选择方法:通过加入噪音值前后的错误率的差值来判断特征值的重要程度。
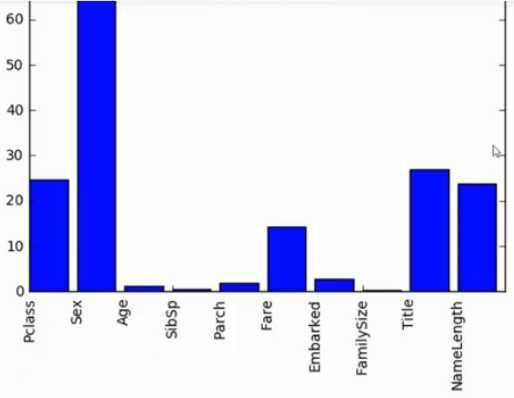
import numpy as np from sklearn.feature_selection import SelectKBest,f_classif import matplotlib.pyplot as plt predictors = ["Pclass","Sex","Age","SibSp","Parch","Fare","Embarked","FamilySize","Title","NameLength"] #Perform feature selection selector=SelectKBest(f_classif,k=5) selector.fit(titanic[predictors],titanic["Survived"]) #Plot the raw p-values for each feature,and transform from p-values into scores scores=-np.log10(selector.pvalues_) #Plot the scores. See how "Pclass","Sex","Title",and "Fare" are the best? plt.bar(range(len(predictors)).scores) plt.xticks(range(len(predictors)).predictors,rotation=‘vertical‘) plt.show() #Pick only the four best features. predictors=["Pclass","Sex","Fare","Title"] alg=RandomForestClassifier(random_state=1,n_estimators=50,min_samples_split=8,min_samples_leaf=4)
然后就是模型选择了,
不能找到一个在所有数据上都表现好的模型,这就需要一步一步的验证了,而且同一个模型的不同参数,对结果影响也很大,在解决这个问题中我主要用了n折交叉验证来验证模型的准确率,选择准确率高的模型,然后通过曲线来模拟这些过程,还有一个可以考虑的点就是boosting方法,把许多个弱分类器的结果整合起来,还可以给每个弱分类器一定的权值。
//集成多种算法求平均的方法来进行机器学习求解
from sklearn.ensemble import GradientBoostingClassifier
import numpy as np
#The algorithms we want to ensemble.
#We‘re using the more linear predictors for the logistic regression,and everything with the gradient boosting classifier
algorithms=[
[GradientBoostingClassifier(random_state=1,n_estimators=25,max_depth=3, ["Pclass","Sex","Age","Fare","FamilySize","Title","Age","Embarked"]]
[LogisticRegression(random_state=1),["Pclass","Sex","Fare","FamilySize","Title","Age","Embarked"]]
]
#Initialize the cross validation folds
kf=KFold(titanic.shape[0],n_folds=3,random_state=1)
predictions=[]
for train,test in kf:
train_target=titanic["Survived"].iloc[train]
full_test_predictions=[]
#Make predictions for each algorithm on each fold
for alg,predictors in algorithms:
#Fit the algorithm on the training data
alg.fit(titanic[predictors].iloc[train,:],train_targegt)
#Select and predict on the test fold
#The .astype(float) is necessary to convert the dataframe to all floats and sklearn error.
test_predictions=alg.predict_proba(titanic[predictors].iloc[test,:].astype(float))[:,1]
#Use a simple ensembling scheme -- just average the predictions to get the final classification.
test_predictions=(full_test_predictions[0]+full_test_predictions[1])/2
#Any value over .5 is assumed to be a 1 prediction,and below .5 is a 0 prediction.
test_predictions[test_predictions<=0.5]=0
test_predictions[test_predictions>0.5]=1
predictions.append(test_predictions)
#Put all the predictions together into one array.
predictions=np.concatenate(predictions,axis=0)
#Compute accuracy by comparing to the training data
accuracy=sum(predictions[predictions==titanic["Survived"]])/len(predictions)
print(accuracy)
#The gradient boosting classifier generates better predictions,so we weight it higher
predictions=(full_predictions[0]*3+full_predictions[1]*1)/4
predictions
这个问题参考了很多的博客或教材:
使用sklearn进行kaggle案例泰坦尼克Titanic船员获救预测
数据科学工程师面试宝典系列之二---Python机器学习kaggle案例:泰坦尼克号船员获救预测
我的代码已经上传至 github
以上是关于泰坦尼克号问题的主要内容,如果未能解决你的问题,请参考以下文章