Kaggle泰坦尼克-Python
Posted Rango
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kaggle泰坦尼克-Python相关的知识,希望对你有一定的参考价值。
参考Kernels里面评论较高的一篇文章,整理作者解决整个问题的过程,梳理该篇是用以了解到整个完整的建模过程,如何思考问题,处理问题,过程中又为何下那样或者这样的结论等!
最后得分并不是特别高,只是到34%,更多是整理一个解决问题的思路,另外前面三个大步骤根据思维导图看即可,代码跟文字等从第四个步骤开始写起。
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
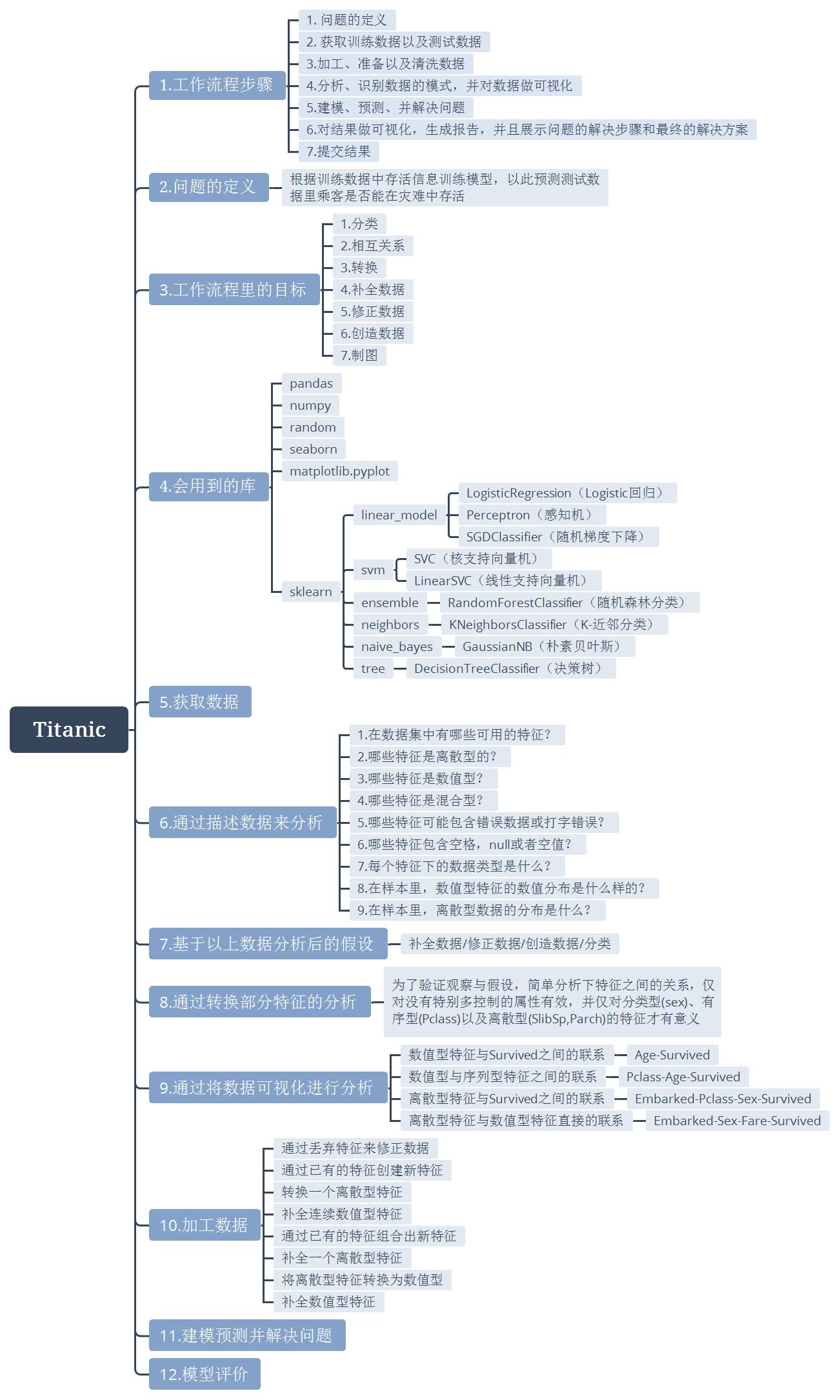
(4) 会用到的库:
以下是在接下来的实验里会用到的一些库:
# data analysis and wrangling import pandas as pd import numpy as np import random as rnd # visualization import seaborn as sns import matplotlib.pyplot as plt # machine learning from sklearn.linear_model import LogisticRegression from sklearn.svm import SVC, LinearSVC from sklearn.ensemble import RandomForestClassifier from sklearn.neighbors import KNeighborsClassifier from sklearn.naive_bayes import GaussianNB from sklearn.linear_model import Perceptron from sklearn.linear_model import SGDClassifier from sklearn.tree import DecisionTreeClassifier
(5)获取数据:
我们可以用python 的 Pandas 来帮助我们处理数据。首先可以将训练数据以及测试数据读入到Pandas 的 DataFrames 里。我们也会将这两个数据集结合起来,用于在两个数据集上同时做一些特定的操作。
# set pandas pd.set_option(\'display.width\', 1000) # use pandas to manage data train_df = pd.read_csv(\'data/train.csv\') test_df = pd.read_csv(\'data/test.csv\') combine = [train_df, test_df]
(6) 通过描述数据来分析:
Pandas 也可以帮助我们描述数据集。我们可以通过以下问答的方式来查看数据集:
1. 在数据集中有哪些可用的特征?
首先需要注意的是,数据集里特征的描述已经在问题描述里给出了,此次数据集里的特征描述如下:
https://www.kaggle.com/c/titanic/data
------------------------------------------------------------------------------------------------------
主要内容为:
Data Dictionary
|
Variable |
Definition |
Key |
|
survival |
Survival |
0 = No, 1 = Yes |
|
pclass |
Ticket class |
1 = 1st, 2 = 2nd, 3 = 3rd |
|
sex |
Sex |
|
|
Age |
Age in years |
|
|
sibsp |
# of siblings / spouses aboard the Titanic |
|
|
parch |
# of parents / children aboard the Titanic |
|
|
ticket |
Ticket number |
|
|
fare |
Passenger fare |
|
|
cabin |
Cabin number |
|
|
embarked |
Port of Embarkation |
C = Cherbourg, Q = Queenstown, S = Southampton |
Variable Notes
pclass: A proxy for socio-economic status (SES)
1st = Upper
2nd = Middle
3rd = Lower
age: Age is fractional if less than 1. If the age is estimated, is it in the form of xx.5
sibsp: The dataset defines family relations in this way...
Sibling = brother, sister, stepbrother, stepsister
Spouse = husband, wife (mistresses and fiancés were ignored)
parch: The dataset defines family relations in this way...
Parent = mother, father
Child = daughter, son, stepdaughter, stepson
Some children travelled only with a nanny, therefore parch=0 for them.
------------------------------------------------------------------------------------------------------
查看训练集里面各字段:
print(train_df.columns.values)
[\'PassengerId\' \'Survived\' \'Pclass\' \'Name\' \'Sex\' \'Age\' \'SibSp\' \'Parch\' \'Ticket\' \'Fare\' \'Cabin\' \'Embarked\']
PassengerId => 乘客ID
Pclass => 乘客等级(1/2/3等舱位)
Name => 乘客姓名
Sex => 性别
Age => 年龄
SibSp => 堂兄弟/妹个数
Parch => 父母与小孩个数
Ticket => 船票信息
Fare => 票价
Cabin => 客舱
Embarked => 登船港口
2. 哪些特征是离散型的?
这些离散型的数值可以将样本分类为一系列相似的样本。在离散型特征里,它们的数值是基于名词的?还是基于有序的?又或是基于比率的?还是基于间隔类的?除此之外,这个可以帮助我们为数据选择合适的图形做可视化。
在这个问题中,离散型的变量有:Survived,Sex 和 Embarked。基于序列的有:Pclass
3. 哪些特征是数值型?
哪些特征是数值型的?这些数据的值随着样本的不同而不同。在数值型特征里,它们的值是离散的还是连续的?又或者是基于时间序列?除此之外,这个可以帮助我们为数据选择合适的图形做可视化。
在这个问题中,连续型的数值特征有:Age,Fare。离散型数值有:SibSp,Parch
train_df.head()

4. 哪些特征是混合型数据?
数值型、字母数值型数据在同一特征下面。这些有可能是我们需要修正的目标数据。
在这个问题中,Ticket是混合了数值型以及字母数值型的数据类型,Cabin是字母数值型数据
5. 哪些特征可能包含错误数据或打字错误?
在大型数据集里要发现这些可能比较困难,然而通过观察小型的数据集里少量的样本,可能也可以完全告诉我们哪些特征需要修正。
在这个问题中,Name的特征可能包含错误或者打字错误,因为会有好几种方法来描述名字
#默认倒数5行 train_df.tail()

6. 哪些特征包含空格,null或者空值
这些空格,null值或者空值很可能需要修正。
在这个问题中:
- 这些特征包含null值的数量大小为:Cabin > Age > Embarked
- 在训练集里有不完整数据的数量的大小为:Cabin > Age
7.每个特征下的数据类型是什么?
这个可以在我们做数据转换时起到较大的帮助。
在这个问题中:
- 有7个特征是int型或float 型。在测试数据集里有6个
- 有5个特征是string(object)类型
train_df.info()

test_df.info()
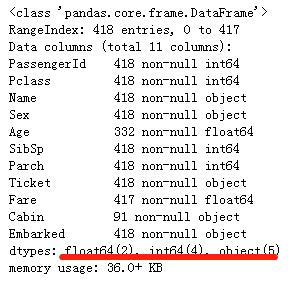
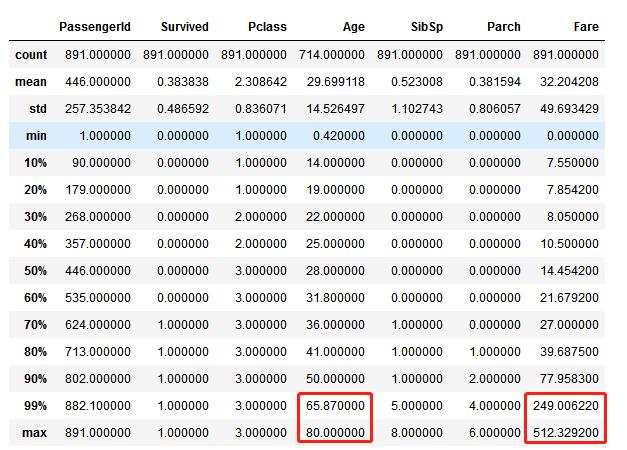
8. 在样本里,数值型特征的数值分布是什么样的?
这个可以帮助我们初步了解:训练数据集如何体现了实际问题。
在这个问题中:
- 一共有891个样本
- Survived的标签是通过0或1来区分
- 大概38%的样本是survived
- 大多数乘客(>76%)没有与父母或是孩子一起旅行
- 大约30%的乘客有亲属和/或配偶一起登船
- 票价的差别非常大,少量的乘客(<1%)付了高达$512的费用
- 很少的乘客(<1%)年纪在64-80之间
我们可以通过以下方式获取上述信息:
train_df.describe()
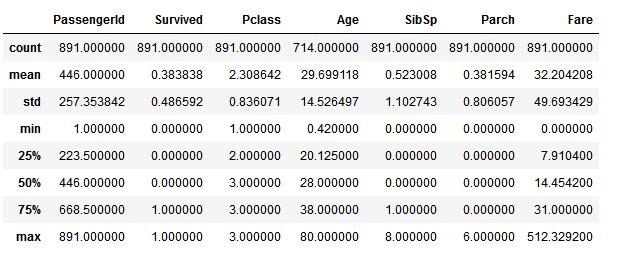
# 通过使用 percentiles=[.61, .62] 来查看数据集可以了解到生存率为 38%
train_df.describe(percentiles=[.61, .62])

# 通过使用 percentiles=[.76, .77] 来查看Parch的分布 train_df.describe(percentiles=[.76, .77])
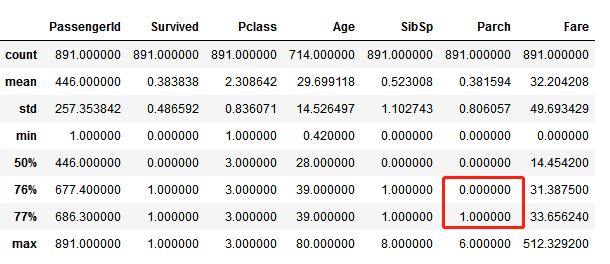
# 通过使用 percentile=[.68, .69] 来查看SibSp的分布 train_df.describe(percentiles=[.68, .69])

#通过使用 percentile=[.1, .2, .3, .4, .5, .6, .7, .8, .9, .99] 来查看Age和Fare的分布 train_df.describe(percentiles=[.1, .2, .3, .4, .5, .6, .7, .8, .9, .99])
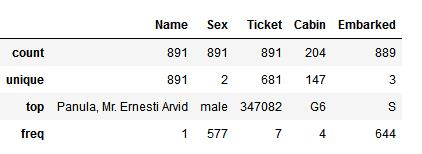
8. 在样本里,离散型数据的分布是什么?
在这个问题中:
- 各个乘客的Name 属性完全是唯一的(count=unique=891)
- Sex特征里65%为男性(top=male,fre=577/count=891)
- Cabin的count与unique并不相等,即说明有些乘客会共享一个cabin
- Embarked一共有种取值,其中从S港口登船的人最多
- Ticket的特征下,有22%左右的重复值(unique=681)
可以通过以下方法获得以上信息:
train_df.describe(include=[\'O\'])
(7)基于以上数据分析后的假设
根据以上的数据分析步骤后,我们可以暂时得出以下假设。当然,我们也可以在之后验证这些假设。
相互关系:
我们想知道每个特征与Survival的相关性如何。我们希望能够今早的做这一步,并且将这些相关性特征匹配到建模后的相关性特征上。
补全数据:
- 我们可能会去补全Age特征下的数据,因为它一定是与存活率是相关的
- 我们可能会去补全Embarked特征下的数据,因为它可能与存活率或者其他重要的特征之间存在相关性
修正数据:
- Ticket特征可能需要从我们的分析中丢弃,因为它的数值重复率高达22%,并且Ticket与survival之间很可能并没有联系
- Cabin特征可能也需要丢弃,因为它的数值非常不完整,并且在训练集以及测试集里均包含较多的null值
- PassengerId特征可能也需要被丢弃,因为它对survival没任何作用
- Name特征相对来说不是特别规范,并且很有可能与survival之间没有直接联系,所以可能也应该被丢弃
创造数据:
- 我们可以根据Parch和SibSp的特征来创建一个新的Family特征,以此得到每个乘客有多少家庭成员登了船
- 我们可以对Name特征做进一步加工,提取出名字里的Title作为一个新的特征
- 我们可以为Age特征创建一个新的特征,将它原本的连续型数值特征转换为有序的离散型特征
- 我们也可以创建一个票价(Fare)范围的特征,如果它对我们的分析有帮助的话
分类:
根据之前的问题描述或者已有的数据,我们也可以提出以下假设:
- 女人(Sex=female)更有可能存活
- 孩子(Age<?)也更有可能存活
- 上等仓的乘客(Pclass=1)有更大的存活率
(8)通过转换部分特征后的分析
为了验证之前的观察与假设,我们可以通过pivoting feature的方法简单的分析一下特征之间的相关性。
这种方法仅仅对那些没有特别多空值的属性有效,并且仅仅对那些分类型的(Sex)、有序型的(Pclass)以及离散型(SibSp,Parch)的特征才有意义。
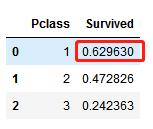
1. Pclass:我们观察到Pclass=1与Survived的相关性较大(>0.5),所以可以考虑将此特征放入到之后的模型里
2. Sex:我们可以确认Sex=female有着高达74%的生存率
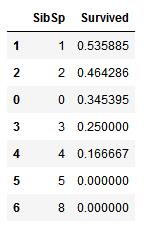
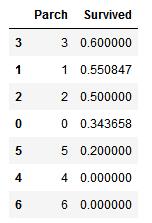
3. SibSp 和 Parch:这些特征下有些值与survived有相关性,但是有些又毫无相关性。所以我们可能需要基于这些单独的特征或一系列特征创建一个新特征,以做进一步分析
以上结论可以通过下面的操作获取:
train_df[[\'Pclass\', \'Survived\']].groupby([\'Pclass\'], as_index=False).mean().sort_values(by=\'Survived\', ascending=False)
train_df[[\'Sex\', \'Survived\']].groupby([\'Sex\'], as_index=False).mean().sort_values(by=\'Survived\', ascending=False)

train_df[[\'SibSp\', \'Survived\']].groupby([\'SibSp\'], as_index=False).mean().sort_values(by=\'Survived\', ascending=False)
train_df[[\'Parch\', \'Survived\']].groupby([\'Parch\'], as_index=False).mean().sort_values(by=\'Survived\', ascending=False)
(9)通过将数据可视化进行分析
现在我们可以通过将数据可视化对数据做进一步分析,并继续验证我们之前的假设是否正确
数值型特征与Survived之间的联系:
柱状图在用于分析连续型的数值特征时非常有用,如特征Age,它的柱状图数值范围(不同的年龄范围)可以帮助我们识别一些有用的模式。
通过使用默认或自定的数值范围(年龄范围),柱状图可以帮助我们描绘出样本所遵循的分布。
它可以帮助我们发现是否某些特定的年龄范围(如婴儿)有更高的存活率。
我们可以通过以下代码来画出Age的柱状图:
g = sns.FacetGrid(train_df, col=\'Survived\') g.map(plt.hist, \'Age\', bins=20) plt.show()
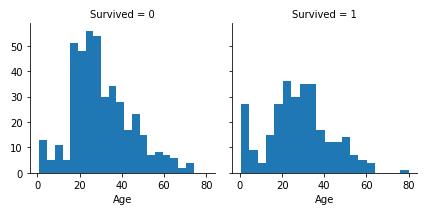
观察:
- 婴儿(Age<=4)有较高的生存率(20个bin,每个bin为4岁)
- 老人(Age=80)全部生还
- 大量的15-25年纪的乘客没有生还
- 乘客主要在15-35的年纪范围内
结论:
以上简单的分析验证了我们之前的假设:
- 我们需要将Age考虑到训练模型里
- 为Age特征补全null值
- 我们应该划分不同的年龄层
数值型与序列型特征之间的联系:
我们可以将多个特征组合,然后通过一个简单的图来识别它们之间的关系。这种方法可以应用在数值型以及分类型(Pclass)的特征里,因为它们的值都是数值型。
我们可以通过以下代码来画出Pclass的柱状图:
grid = sns.FacetGrid(train_df, col=\'Survived\', row=\'Pclass\', size=2.2, aspect=1.6) grid.map(plt.hist, \'Age\', alpha=.5, bins=20) grid.add_legend() plt.show()

观察:
- Pclass=3 有着最多的乘客,但是他们大多数却没有存活。这也验证了我们之前在“分类”里的假设
- 在Pclass=2和Pclass=3中,大多数婴儿活了下来,进一步验证了我们之前在“分类”里的假设
- 大多数Pclass=1的乘客存活,验证我们之前在“分类”里的假设
- 不同Pclass中Age的分布不同
结论:
考虑将Pclass特征加入模型训练
离散型特征与Survived之间的联系:
现在我们可以查看离散型特征与survived之间的关系
我们可以通过以下方式将数据可视化:
grid = sns.FacetGrid(train_df, row=\'Embarked\', size=2.2, aspect=1.6) grid.map(sns.pointplot, \'Pclass\', \'Survived\', \'Sex\',order=[1,2,3],hue_order=train_df.Sex.unique(),palette=\'deep\') grid.add_legend() plt.show() #原作者代码没有加入order、hue_order因此图示会有错误,并得出了错误的结论,不过那个结论没有应用到后续的特征选择。。建议代码完成后结果可执行但是会提示有可能引起错误提示的话,还是修改下代码比较好
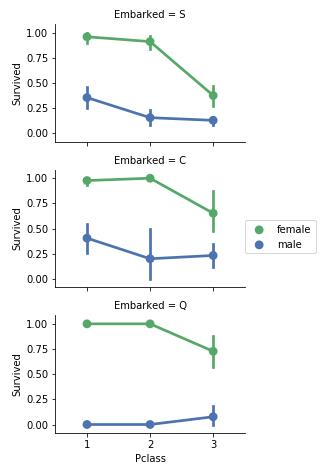
观察:
- 女性乘客相对于男性乘客有着更高的存活率
- Embarked和Survived之间可能并没有直接的联系。
- 对于Pclass=3以及男性乘客来说,Embarked的港口不同会导致存活率的不同
结论:
- 将Sex特征加入训练模型
- 补全Embarked特征下的数据并将此特征加入训练模型
离散型特征与数值型特征之间的联系:
我们可能也想找出离散型与数值型特征之间的关系。
我们可以考虑查看Embarked(离散非数值型),Sex(离散非数值型),Fare(连续数值型)与Survived(离散数值型)之间的关系
grid = sns.FacetGrid(train_df, row=\'Embarked\', col=\'Survived\', size=2.2, aspect=1.6) grid.map(sns.barplot, \'Sex\', \'Fare\', order=train_df.Sex.unique(),alpha=.5, ci=None) grid.add_legend() plt.show()
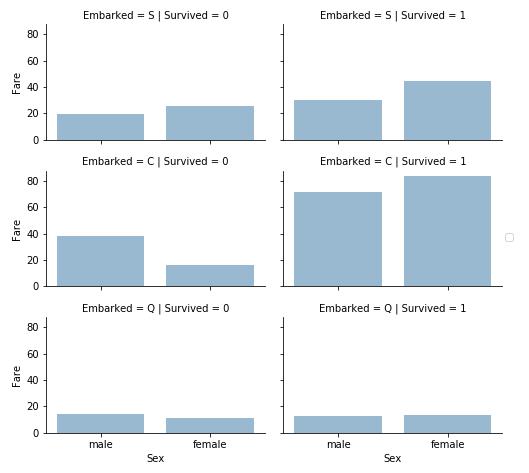
观察:
- 1. 付了高票价的乘客有着更高的生存率,验证了我们之前的假设
- 2. Embarked与生存率相关,验证了我们之前所做的假设
结论:
- 1. 考虑将Fare特征做不同的区间
(10)加工数据
我们根据数据集以及题目的要求已经收集了一些假设与结论。到现在为止,我们暂时还没有对任何特征或数据进行处理。
接下来我们会根据之前做的假设与结论,以“修正数据”、“创造数据”以及“补全数据”为目标,对数据进行处理。
通过丢弃特征来修正数据:
这个步骤比较好的一个开始。通过丢弃某些特征,可以让我们处理更少的数据点,并让分析更简单。
根据我们之前的假设和结论,我
们希望丢弃Cabin和Ticket这两个特征。
在这里需要注意的是,为了保持数据的一致,我们需要同时将训练集与测试集里的这两个特征均丢弃。
具体步骤如下:
print("Before", train_df.shape, test_df.shape, combine[0].shape, combine[1].shape)
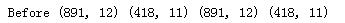
train_df = train_df.drop([\'Ticket\', \'Cabin\'], axis=1) test_df = test_df.drop([\'Ticket\', \'Cabin\'], axis=1) combine = [train_df, test_df] print(\'After\', train_df.shape, test_df.shape, combine[0].shape, combine[1].shape)

通过已有的特征创建新特征:
我们在丢弃Name与PassengerId这两个特征之前,希望从Name特征里提取出Titles的特征,并测试Titles与survival之间的关系。
在下面的代码中,我们通过正则提取了Title特征,正则表达式为(\\w+\\.),它会在Name特征里匹配第一个以“.”号为结束的单词。同时,指定expand=False的参数会返回一个DataFrame。
for dataset in combine: dataset[\'Title\'] = dataset.Name.str.extract(\'([A-Za-z]+)\\.\', expand=False) pd.crosstab(train_df[\'Title\'], train_df[\'Sex\']) #西方姓名中间会加入称呼,比如小男童会在名字中间加入Master,女性根据年龄段及婚姻状况不同也会使用Miss 或 Mrs 等,这算是基于业务的理解做的衍生特征,原作者应该是考虑可以用作区分人的特征因此在此尝试清洗数据后加入

我们可以使用高一些更常见的名字或“Rare”来代替一些Title,如:
for dataset in combine: dataset[\'Title\'] = dataset[\'Title\'].replace([\'Lady\', \'Countess\', \'Capt\', \'Col\', \'Don\', \'Dr\', \'Major\', \'Rev\', \'Sir\', \'Jonkheer\', \'Dona\'], \'Rare\') dataset[\'Title\'] = dataset[\'Title\'].replace(\'Mlle\', \'Miss\') dataset[\'Title\'] = dataset[\'Title\'].replace(\'Ms\', \'Miss\') dataset[\'Title\'] = dataset[\'Title\'].replace(\'Mme\', \'Mrs\') train_df[[\'Title\', \'Survived\']].groupby([\'Title\'], as_index=False).mean()

进一步的,我们可以将这些离散型的Title转换为有序的数值型:
title_mapping = {"Mr":1, "Miss":2, "Mrs":3, "Master":4, "Rare":5}
for dataset in combine:
dataset[\'Title\'] = dataset[\'Title\'].map(title_mapping)
dataset[\'Title\'] = dataset[\'Title\'].fillna(0)
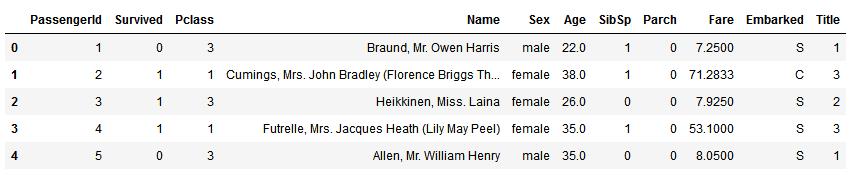
train_df.head()
现在我们可以放心的从训练集与测试集里丢弃Name特征。同时,我们也不再需要训练集里的PassengerId特征:
train_df = train_df.drop([\'Name\', \'PassengerId\'], axis=1) test_df = test_df.drop([\'Name\'], axis=1) combine = [train_df, test_df] train_df.shape, test_df.shape
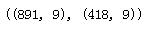
train_df.head()
train_df[[\'Title\', \'Survived\']].groupby([\'Title\'], as_index=False).mean()

新的发现:
当我们画出Title,Age和Survived的图后,我们有了以下新的发现:
- 大多数Title分段与年龄字段对应准确,比如,Title为Master平均年龄为5岁
- 不同组别Title与生产率有一定的区分度。
- 某些特定的title如Mme,Lady,Sir的乘客存活率较高,但某些title如Don,Rev,Jonkheer的乘客存活率不高
结论:
- 我们决定保留这个新的Title特征并加入到训练模型
转换一个离散型的特征
现在我们可以将一些包含字符串数据的特征转换为数值型特征,因为在很多建模算法里,输入的参数要求为数值型。
这个步骤可以让我们达到补全数据的目标。
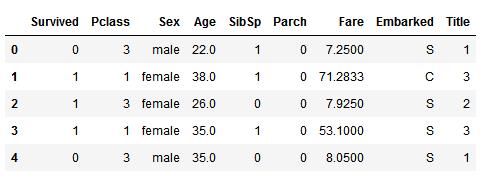
我们可以从转换Sex特征开始,将female转换为1,male转换为0。我们可以将新的特征命名为Gender:
for dataset in combine: dataset[\'Sex\'] = dataset[\'Sex\'].map({\'female\':1, \'male\':0}).astype(int)
train_df.head()
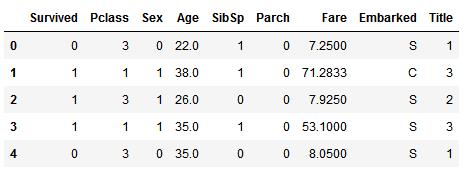
补全连续数值型特征
现在我们可以开始为那些含null值或者丢失值的特征补全数据。我们首先会为Age特征补全数据。
现在我们总结一下三种补全连续数值型特征数据的方法:
1. 一个简单的方法是产生一个随机数,这个随机数的范围在这个特征的平均值以及标准差之间
2. 更精准的一个做法是使用与它相关的特征来做一个猜测。在这个案例中,我们发现Age,Gender和Pclass之间有关联。
所以我们会使用一系列Pclass和Gender特征组合后的中值,作为猜测的Age值。
所以我们会有一系列的猜测值如:当Pclass=1且Gender=0时,当Pclass=1且Gender=1时,等等…
3. 第三种方法是结合以上两种方法。我们可以根据一系列Pclass与Gender的组合,并使用第一种方法里提到的随机数来猜测缺失的Age值
方法1与方法3会在模型里引入随机噪音,多次的结果可能会有所不同。所以我们在这更倾向于使用方法2:
grid = sns.FacetGrid(train_df, row=\'Pclass\', col=\'Sex\', size=2.2, aspect=1.6) grid.map(plt.hist, \'Age\', alpha=.5, bins=20) grid.add_legend() plt.show()
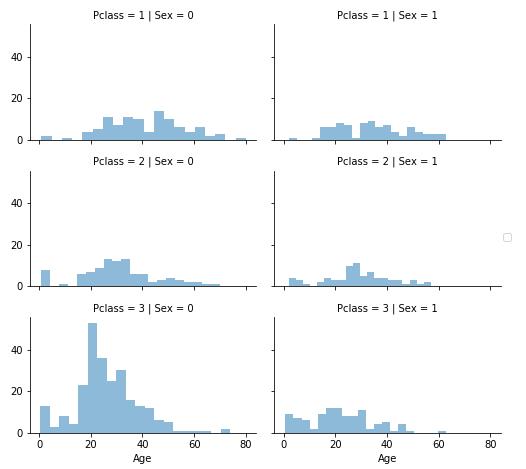
我们先准备一个空的数组来存储猜测的年龄,因为是Pclass与Gender的组合,所以数组大小为2x3:
guess_ages = np.zeros((2, 3))
然后我们可以对Sex(0或1)和Pclass(1,2,3)进行迭代,并计算出在6中组合下所得到的猜测(Age)值:
for dataset in combine: for i in range(0, 2): for j in range(0, 3): guess_df = dataset[(dataset[\'Sex\'] == i) & (dataset[\'Pclass\'] == j+1)][\'Age\'].dropna() age_guess = guess_df.median() # Convert random age float to nearest .5 age guess_ages[i, j] = int(age_guess / 0.5 + 0.5) * 0.5 for i in range(0, 2): for j in range(0, 3): dataset.loc[ (dataset.Age.isnull()) & (dataset.Sex == i) & (dataset.Pclass == j+1), \'Age\'] = guess_ages[i,j] dataset[\'Age\'] = dataset[\'Age\'].astype(int) train_df.head()

现在我们对Age分段,并查看每段与Survived之间的相关性:
train_df[\'AgeBand\'] = pd.cut(train_df[\'Age\'], 5) train_df[[\'AgeBand\', \'Survived\']].groupby([\'AgeBand\'], as_index=False).mean().sort_values(by=\'AgeBand\', ascending=True)
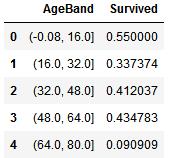
然后我们根据上面的分段,使用有序的数值来替换Age里的值:
for dataset in combine: dataset.loc[ dataset[\'Age\'] <= 16, \'Age\'] = 0 dataset.loc[(dataset[\'Age\'] > 16) & (dataset[\'Age\'] <= 32), \'Age\'] = 1 dataset.loc[(dataset[\'Age