R语言泰坦尼克号随机森林模型案例数据分析|附代码数据
Posted 大数据部落
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言泰坦尼克号随机森林模型案例数据分析|附代码数据相关的知识,希望对你有一定的参考价值。
原文链接:http://tecdat.cn/?p=4281
最近我们被客户要求撰写关于随机森林模型的研究报告,包括一些图形和统计输出。
如果我们对所有这些模型的结果进行平均,我们有时可以从它们的组合中找到比任何单个部分更好的模型。这就是集成模型的工作方式
让我们构建一个由三个简单决策树组成的非常小的集合来说明:
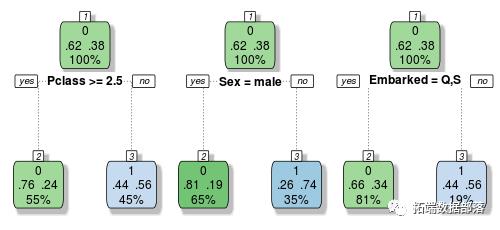
这些树中的每一个都根据不同的变量做出分类决策。
随机森林模型比上面的决策树更深地生长树木,实际上默认是尽可能地将每棵树生长出来。随机森林以两种方式做到这一点。
第一个技巧是使用套袋。Bagging会对您的训练集中的行进行随机抽样。使用样本函数很容易在R中进行模拟。假设我们想在10行的训练集上进行装袋。
> sample(1:10, replace = TRUE)
[1] 3 1 9 1 7 10 10 2 2 9
在此模拟中,如果再次运行此命令,则每次都会获得不同的行样本。平均而言,大约37%的行将被排除在自举样本之外。通过这些重复和省略的行,每个使用装袋生长的决策树将略有不同。
第二个随机来源超越了这个限制。随机森林不是查看整个可用变量池,而是仅采用它们的一部分,通常是可用数量的平方根。在我们的例子中,我们有10个变量,因此使用三个变量的子集是合理的。
通过这两个随机性来源,整体包含一系列完全独特的树木,这些树木的分类都不同。与我们的简单示例一样,每个树都被调用以对给定乘客进行分类,对投票进行统计(可能有数百或数千棵树)并且选择多数决策。
R的随机森林算法对我们的决策树没有一些限制。我们必须清理数据集中的缺失值。rpart它有一个很大的优点,它可以在遇到一个NA值时使用替代变量。在我们的数据集中,缺少很多年龄值。如果我们的任何决策树按年龄分割,那么树将搜索另一个以与年龄相似的方式分割的变量,并使用它们代替。随机森林无法做到这一点,因此我们需要找到一种手动替换这些值的方法。
看一下合并后的数据框的年龄变量:
> summary(combi$Age)
Min. 1st Qu. Median Mean 3rd Qu. Max. NA\'s
0.17 21.00 28.00 29.88 39.00 80.00 263
1309个中有263个值丢失了,这个数字高达20%!此子集是否缺少值。我们现在也想使用method="anova"决策树的版本,因为我们不是要再预测某个类别,而是连续变量。因此,让我们使用可用的年龄值在数据子集上生成一个树,然后替换缺少的那些样本:
> combi$Age[is.na(combi$Age)] <- predict(Agefit, combi[is.na(combi$Age),])
您可以继续检查摘要,所有这些NA值都消失了。
现在让我们看看整个数据集的摘要,看看是否还有其他我们以前没有注意到的问题变量:
> summary(combi)
> summary(combi$Embarked)
C Q S
2 270 123 914
两名乘客的空白。首先,我们需要找出他们是谁!我们可以which用于此:
> which(combi$Embarked == \'\')
[1] 62 830
然后我们简单地替换这两个,并将其编码为一个因素:
> combi$Embarked <- factor(combi$Embarked)
另一个变量是Fare,让我们来看看:
> summary(combi$Fare)
Min. 1st Qu. Median Mean 3rd Qu. Max. NA\'s
0.000 7.896 14.450 33.300 31.280 512.300 1
它只有一个乘客NA,所以让我们找出它是哪一个并用中位数票价取而代之:
> which(is.na(combi$Fare))
[1] 1044
好的。我们的数据框现已被清理。现在进入第二个限制:R中的随机森林只能消化多达32个等级的因子。我们的FamilyID变量几乎翻了一倍。我们可以在这里采用两条路径,或者将这些级别更改为它们的基础整数(使用unclass()函数)并让树将它们视为连续变量,或者手动减少级别数以使其保持在阈值之下。
我们采取第二种方法。然后我们将它转换回一个因素:
> combi$FamilyID2 <- combi$FamilyID
> combi$FamilyID2 <- factor(combi$FamilyID2)
我们已经降到了22级,所以我们很好地将测试和训练集分开,安装并加载包
randomForest:
> install.packages(\'randomForest\')
设置随机种子。
> set.seed(415)
内部数字并不重要,您只需确保每次使用相同的种子编号,以便在随机森林函数内生成相同的随机数。
现在我们准备运行我们的模型了。语法类似于决策树。
> fit <- randomForest( )
我们强制模型通过暂时将目标变量更改为仅使用两个级别的因子来预测我们的分类,而不是method="class"像使用那样指定。
如果您正在使用更大的数据集,您可能希望减少树的数量,至少在初始探索时,使用限制每个树的复杂性nodesize以及减少采样的行数sampsize
那么让我们来看看哪些变量很重要:
> varImpPlot(fit)

点击标题查阅往期内容

PYTHON链家租房数据分析:岭回归、LASSO、随机森林、XGBOOST、KERAS神经网络、KMEANS聚类、地理可视化

左右滑动查看更多

01

02
03

04

我们的Title变量在这两个指标中都处于领先地位。我们应该非常高兴地看到剩下的工程变量也做得非常好。
预测函数与决策树的工作方式类似,我们可以完全相同的方式构建提交文件。
> Prediction <- predict(fit, test)
> write.csv(submit, file = "firstforest.csv", row.names = FALSE)
让我们尝试一下条件推理树的森林。
所以继续安装并加载party包。
> install.packages(\'party\')
> library(party)
以与我们的随机森林类似的方式构建模型:
> set.seed(415)
> fit <- cforest( )
条件推理树能够处理比Random Forests更多级别的因子。让我们做另一个预测:
> Prediction <- predict(fit, test, OOB=TRUE, type = "response")

有问题欢迎下方留言!

点击文末 “阅读原文”
获取全文完整代码数据资料。
本文选自《R语言泰坦尼克号随机森林模型案例数据分析》。
点击标题查阅往期内容
R语言贝叶斯广义线性混合(多层次/水平/嵌套)模型GLMM、逻辑回归分析教育留级影响因素数据
Python中的Lasso回归之最小角算法LARS
高维数据惩罚回归方法:主成分回归PCR、岭回归、lasso、弹性网络elastic net分析基因数据
Python高维变量选择:SCAD平滑剪切绝对偏差惩罚、Lasso惩罚函数比较
R语言惩罚logistic逻辑回归(LASSO,岭回归)高维变量选择的分类模型案例
R使用LASSO回归预测股票收益
广义线性模型glm泊松回归的lasso、弹性网络分类预测学生考试成绩数据和交叉验证
贝叶斯分位数回归、lasso和自适应lasso贝叶斯分位数回归分析免疫球蛋白、前列腺癌数据
R语言RSTAN MCMC:NUTS采样算法用LASSO 构建贝叶斯线性回归模型分析职业声望数据
r语言中对LASSO回归,Ridge岭回归和弹性网络Elastic Net模型实现
R语言高维数据惩罚回归方法:主成分回归PCR、岭回归、lasso、弹性网络elastic net分析基因数据(含练习题)
Python中LARS和Lasso回归之最小角算法Lars分析波士顿住房数据实例
R语言Bootstrap的岭回归和自适应LASSO回归可视化
R语言Lasso回归模型变量选择和糖尿病发展预测模型R语言实现贝叶斯分位数回归、lasso和自适应lasso贝叶斯分位数回归分析
基于R语言实现LASSO回归分析
R语言用LASSO,adaptive LASSO预测通货膨胀时间序列
R语言自适应LASSO 多项式回归、二元逻辑回归和岭回归应用分析
R语言惩罚logistic逻辑回归(LASSO,岭回归)高维变量选择的分类模型案例
Python中的Lasso回归之最小角算法LARS
r语言中对LASSO回归,Ridge岭回归和弹性网络Elastic Net模型实现
r语言中对LASSO回归,Ridge岭回归和Elastic Net模型实现
R语言实现LASSO回归——自己编写LASSO回归算法
R使用LASSO回归预测股票收益
python使用LASSO回归预测股票收益Python中LARS和Lasso回归之最小角算法Lars分析波士顿住房数据实例
R语言Bootstrap的岭回归和自适应LASSO回归可视化
R语言Lasso回归模型变量选择和糖尿病发展预测模型R语言实现贝叶斯分位数回归、lasso和自适应lasso贝叶斯分位数回归分析
基于R语言实现LASSO回归分析
R语言用LASSO,adaptive LASSO预测通货膨胀时间序列
R语言自适应LASSO 多项式回归、二元逻辑回归和岭回归应用分析
R语言惩罚logistic逻辑回归(LASSO,岭回归)高维变量选择的分类模型案例
Python中的Lasso回归之最小角算法LARS
r语言中对LASSO回归,Ridge岭回归和弹性网络Elastic Net模型实现
r语言中对LASSO回归,Ridge岭回归和Elastic Net模型实现
R语言实现LASSO回归——自己编写LASSO回归算法
R使用LASSO回归预测股票收益
python使用LASSO回归预测股票收益R语言随机森林RandomForest、逻辑回归Logisitc预测心脏病数据和可视化分析
数据分享|R语言逻辑回归、线性判别分析LDA、GAM、MARS、KNN、QDA、决策树、随机森林、SVM分类葡萄酒交叉验证ROC
MATLAB随机森林优化贝叶斯预测分析汽车燃油经济性
R语言用Rcpp加速Metropolis-Hastings抽样估计贝叶斯逻辑回归模型的参数
R语言逻辑回归、Naive Bayes贝叶斯、决策树、随机森林算法预测心脏病
R语言中贝叶斯网络(BN)、动态贝叶斯网络、线性模型分析错颌畸形数据
R语言中的block Gibbs吉布斯采样贝叶斯多元线性回归
Python贝叶斯回归分析住房负担能力数据集
R语言实现贝叶斯分位数回归、lasso和自适应lasso贝叶斯分位数回归分析
Python用PyMC3实现贝叶斯线性回归模型
R语言用WinBUGS 软件对学术能力测验建立层次(分层)贝叶斯模型
R语言Gibbs抽样的贝叶斯简单线性回归仿真分析
R语言和STAN,JAGS:用RSTAN,RJAG建立贝叶斯多元线性回归预测选举数据
R语言基于copula的贝叶斯分层混合模型的诊断准确性研究
R语言贝叶斯线性回归和多元线性回归构建工资预测模型
R语言贝叶斯推断与MCMC:实现Metropolis-Hastings 采样算法示例
R语言stan进行基于贝叶斯推断的回归模型
R语言中RStan贝叶斯层次模型分析示例
R语言使用Metropolis-Hastings采样算法自适应贝叶斯估计与可视化
R语言随机搜索变量选择SSVS估计贝叶斯向量自回归(BVAR)模型
WinBUGS对多元随机波动率模型:贝叶斯估计与模型比较
R语言实现MCMC中的Metropolis–Hastings算法与吉布斯采样
R语言贝叶斯推断与MCMC:实现Metropolis-Hastings 采样算法示例
R语言使用Metropolis-Hastings采样算法自适应贝叶斯估计与可视化
视频:R语言中的Stan概率编程MCMC采样的贝叶斯模型
R语言MCMC:Metropolis-Hastings采样用于回归的贝叶斯估计R语言用lme4多层次(混合效应)广义线性模型(GLM),逻辑回归分析教育留级调查数据
R语言随机森林RandomForest、逻辑回归Logisitc预测心脏病数据和可视化分析
R语言基于Bagging分类的逻辑回归(Logistic Regression)、决策树、森林分析心脏病患者
R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化
以上是关于R语言泰坦尼克号随机森林模型案例数据分析|附代码数据的主要内容,如果未能解决你的问题,请参考以下文章
R语言逻辑回归(Logistic Regression)回归决策树随机森林信用卡违约分析信贷数据集|附代码数据
R语言随机森林RandomForest逻辑回归Logisitc预测心脏病数据和可视化分析|附代码数据
数据分享|R语言逻辑回归Naive Bayes贝叶斯决策树随机森林算法预测心脏病|附代码数据
数据分享|R语言逻辑回归Naive Bayes贝叶斯决策树随机森林算法预测心脏病|附代码数据