Kafka:ZK+Kafka+Spark Streaming集群环境搭建安装zookeeper-3.4.12
Posted yy3b2007com
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka:ZK+Kafka+Spark Streaming集群环境搭建安装zookeeper-3.4.12相关的知识,希望对你有一定的参考价值。
如何搭建配置centos虚拟机请参考《Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网。》
如何安装hadoop2.9.0请参考《Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二)安装hadoop2.9.0》
如何安装spark2.2.1请参考《Kafka:ZK+Kafka+Spark Streaming集群环境搭建(三)安装spark2.2.1》
安装zookeeper的服务器:
192.168.0.120 master
192.168.0.121 slave1
192.168.0.122 slave2
192.168.0.123 slave3
备注:只在master,slave1,slave2三个节店上安装zookeeper,slave3节店不安装(其实前边hadoop中master不作为datanode节店,spark中master不作为worker节店)。关于zk只允许安装奇数节点的原因这里不写。
1. 简介
Kafka 依赖 Zookeeper 管理自身集群(Broker、Offset、Producer、Consumer等),所以先要安装 Zookeeper。
为了达到高可用的目的,Zookeeper 自身也不能是单点,接下来就介绍如何搭建一个最小的 Zookeeper 集群(3个 zk 节点)。
2.下载解压zk
从官网找到下载地址,并下载zookeeper-3.4.12
上传zookeeper-3.4.12.tar.gz在master节点上,并解压:
[[email protected] ~]$ cd /opt/ [[email protected] opt]$ su root Password: [[email protected] opt]# tar -zxvf zookeeper-3.4.12.tar.gz [[email protected] opt]# ls hadoop-2.9.0 jdk1.8.0_171 scala-2.11.0 spark-2.2.1-bin-hadoop2.7 zookeeper-3.4.12 hadoop-2.9.0.tar.gz jdk-8u171-linux-x64.tar.gz scala-2.11.0.tgz spark-2.2.1-bin-hadoop2.7.tgz zookeeper-3.4.12.tar.gz [[email protected] opt]#
3.配置zk
1)配置文件位置
路径:/opt/zookeeper-3.4.12/conf/
[[email protected] conf]# cd /opt/zookeeper-3.4.12/conf/ [[email protected] conf]# ls configuration.xsl log4j.properties zoo_sample.cfg [[email protected] conf]#
2)生成配置文件
将 zoo_sample.cfg 复制一份,命名为 zoo.cfg,此即为Zookeeper的配置文件。
[[email protected] conf]# cd /opt/zookeeper-3.4.12/conf/ [[email protected] conf]# cp zoo_sample.cfg zoo.cfg
3)编辑配置文件zoo.cfg
# The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. dataDir=/opt/zookeeper-3.4.12/data dataLogDir=/opt/zookeeper-3.4.12/logs # the port at which the clients will connect clientPort=2181 # the maximum number of client connections. # increase this if you need to handle more clients #maxClientCnxns=60 # # Be sure to read the maintenance section of the # administrator guide before turning on autopurge. # # http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance # # The number of snapshots to retain in dataDir #autopurge.snapRetainCount=3 # Purge task interval in hours # Set to "0" to disable auto purge feature #autopurge.purgeInterval=1 server.1=192.168.0.120:4001:4002 server.2=192.168.0.121:4001:4002 server.3=192.168.0.122:4001:4002
说明:
- dataDir 和 dataLogDir 需要在启动前创建完成
[[email protected] conf]# mkdir /opt/zookeeper-3.4.12/data [[email protected] conf]# mkdir /opt/zookeeper-3.4.12/logs
- clientPort 为 zookeeper的服务端口
- server.0、server.1、server.2 为 zk 集群中三个 node 的信息,定义格式为 hostname:port1:port2,其中 port1 是 node 间通信使用的端口,port2 是node 选举使用的端口,需确保三台主机的这两个端口都是互通的。
4. 更改日志配置
Zookeeper 默认会将控制台信息输出到启动路径下的 zookeeper.out 中,通过如下方法,可以让 Zookeeper 输出按尺寸切分的日志文件:
1)修改/opt/zookeeper-3.4.12/conf/log4j.properties文件,将
zookeeper.root.logger=INFO, CONSOLE
改为
zookeeper.root.logger=INFO, ROLLINGFILE
2)修改/opt/zookeeper-3.4.12/bin/zkEnv.sh文件,将
ZOO_LOG4J_PROP="INFO,CONSOLE"
改为
ZOO_LOG4J_PROP="INFO,ROLLINGFILE"
5.在master主机的 dataDir 路径下创建一个文件名为 myid 的文件
文件内容为该 zk 节点的编号。
在master上操作:
[[email protected] zookeeper-3.4.12]# echo 0 >>/opt/zookeeper-3.4.12/data/myid [[email protected] zookeeper-3.4.12]# cd /opt/zookeeper-3.4.12/data/ [[email protected] data]# ls myid [[email protected] data]# more myid 1 [[email protected] data]#
备注:
1、在第一台master主机上建立的 myid 文件内容是 1,第二台slave1主机上建立的myid文件内容是 2,第三台slave2主机上建立的myid文件内容是 3。myid文件内容需要与/opt/zookeeper-3.4.12/conf/zoo.cfg中的配置的server.id的编号对应。
2、可以先把zk文件拷贝到其他节点后,再在各自的节点上手动修改myid编号。
6.将master主机上配置好的zookeeper文件拷贝到slave1,slave2上,并修改各自的myid编号。
1)将master主机上配置好的zookeeper文件拷贝到slave1,slave2上
此时直接拷贝,会提示权限不足问题:
[[email protected] opt]# scp -r /opt/zookeeper-3.4.12 [email protected]:/opt/ [email protected]‘s password: scp: /opt/zookeeper-3.4.12: Permission denied
需要现在slave1,slave2上创建/opt/zookeeper-3.4.12目录,并分配777操作权限。
Last login: Sat Jun 30 22:29:45 2018 from 192.168.0.103 [[email protected] ~]$ su root Password: [[email protected] spark]# mkdir /opt/zookeeper-3.4.12 [[email protected] spark]# cd /opt/ [[email protected] opt]# chmod 777 zookeeper-3.4.12
拷贝master上的zk到slave1,slave2节点
[[email protected] opt]$ scp -r /opt/zookeeper-3.4.12 [email protected]:/opt/ [[email protected] opt]$ scp -r /opt/zookeeper-3.4.12 [email protected]:/opt/
2)并修改各自的myid编号
slave1
[[email protected] opt]# vi /opt/zookeeper-3.4.12/data/myid [[email protected] opt]# more /opt/zookeeper-3.4.12/data/myid 2 [[email protected] opt]#
slave2
[[email protected] opt]# vi /opt/zookeeper-3.4.12/data/myid [[email protected] opt]# more /opt/zookeeper-3.4.12/data/myid 3 [[email protected] opt]#
7. 启动
启动三台主机上的 zookeeper 服务
此时自己启动会抛出异常:
[[email protected] opt]$ cd /opt/zookeeper-3.4.12/bin [[email protected] bin]$ ls README.txt zkCleanup.sh zkCli.cmd zkCli.sh zkEnv.cmd zkEnv.sh zkServer.cmd zkServer.sh [[email protected] bin]$ ./zkServer.sh start ZooKeeper JMX enabled by default Using config: /opt/zookeeper-3.4.12/bin/../conf/zoo.cfg Starting zookeeper ... ./zkServer.sh: line 149: /opt/zookeeper-3.4.12/data/zookeeper_server.pid: Permission denied FAILED TO WRITE PID
原因,是dataDir无权限写入。
解决,分别在三个节点(master,slave1,slave2)上执行chmod分配写入权限
[[email protected] bin]$ su root Password: [[email protected] bin]# chmod a+xwr /opt/zookeeper-3.4.12/data [[email protected] bin]#
然后分别启动三个节点上的zk。
[[email protected] bin]# su spark [[email protected] bin]$ cd /opt/zookeeper-3.4.12/bin [[email protected] bin]$ ./zkServer.sh start ZooKeeper JMX enabled by default Using config: /opt/zookeeper-3.4.12/bin/../conf/zoo.cfg Starting zookeeper ... STARTED [[email protected] bin]$
8. 查看集群状态
3个节点启动完成后,可依次执行如下命令查看集群状态:
cd /opt/zookeeper-3.4.12/bin ./zkServer.sh status
master(192.168.0.120)返回:

slave1(192.168.0.121)返回:

slave2(192.168.0.122)返回:

9. 测试集群高可用性
1)停掉集群中的为 leader 的 zookeeper 服务,本文中的leader为 slave1(192.168.0.121)。
在slave1中执行:
cd /opt/zookeeper-3.4.12/bin ./zkServer.sh stop
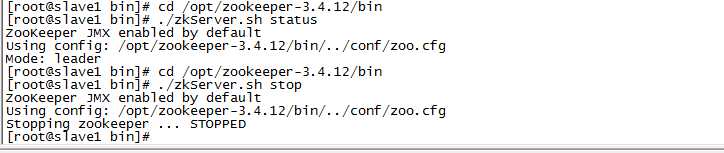
2)查看集群中 master(192.168.0.120)和 slave2(192.168.0.122)的的状态
master(192.168.0.120):

slave2(192.168.0.122)

此时,master(192.168.0.120)成为了集群中的 follower,slave2(192.168.0.122)依然为 leader。
3)启动 slave1(192.168.0.121)的 zookeeper 服务,并查看状态
cd /opt/zookeeper-3.4.12/bin ./zkServer.sh start ./zkServer.sh status

此时, slave1(192.168.0.121)成为了集群中的 follower。
此时,Zookeeper 集群的安装及高可用性验证已完成!
参考《https://www.cnblogs.com/RUReady/p/6479464.html》
以上是关于Kafka:ZK+Kafka+Spark Streaming集群环境搭建安装zookeeper-3.4.12的主要内容,如果未能解决你的问题,请参考以下文章
Kafka:ZK+Kafka+Spark Streaming集群环境搭建安装zookeeper-3.4.12
Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十七)待整理
Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十九)待整理
Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十一)NIFI1.7.1安装
Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十三)kafka+spark streaming打包好的程序提交时提示虚拟内存不足(Container is running
Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十二)Spark Streaming接收流数据及使用窗口函数