Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十二)Spark Streaming接收流数据及使用窗口函数
Posted yy3b2007com
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十二)Spark Streaming接收流数据及使用窗口函数相关的知识,希望对你有一定的参考价值。
官网文档:《http://spark.apache.org/docs/latest/streaming-programming-guide.html#a-quick-example》
Spark Streaming官网的例子reduceByKeyAndWindow
简单的介绍了spark streaming接收socket流的数据,并把接收到的数据进行windows窗口函数对数据进行批量处理。
import java.util.Arrays; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.streaming.Durations; import org.apache.spark.streaming.api.java.JavaDStream; import org.apache.spark.streaming.api.java.JavaPairDStream; import org.apache.spark.streaming.api.java.JavaReceiverInputDStream; import org.apache.spark.streaming.api.java.JavaStreamingContext; import scala.Tuple2; public class HelloWord { public static void main(String[] args) throws InterruptedException { // Create a local StreamingContext with two working thread and batch interval of 1 second SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("NetworkWordCount"); JavaSparkContext jsc=new JavaSparkContext(conf); jsc.setLogLevel("WARN"); JavaStreamingContext jssc = new JavaStreamingContext(jsc, Durations.seconds(1)); // Create a DStream that will connect to hostname:port, like localhost:9999 JavaReceiverInputDStream<String> lines = jssc.socketTextStream("xx.xx.xx.xx", 19999); // Split each line into words JavaDStream<String> words = lines.flatMap(x -> Arrays.asList(x.split(" ")).iterator()); // Count each word in each batch JavaPairDStream<String, Integer> pairs = words.mapToPair(s -> new Tuple2<>(s, 1)); // Reduce last 60 seconds of data, every 30 seconds JavaPairDStream<String, Integer> windowedWordCounts = pairs.reduceByKeyAndWindow((i1, i2) -> i1 + i2, Durations.seconds(60), Durations.seconds(30)); // Print the first ten elements of each RDD generated in this DStream to the console windowedWordCounts.print(); jssc.start(); // Start the computation jssc.awaitTermination(); // Wait for the computation to terminate } }
输入数据:
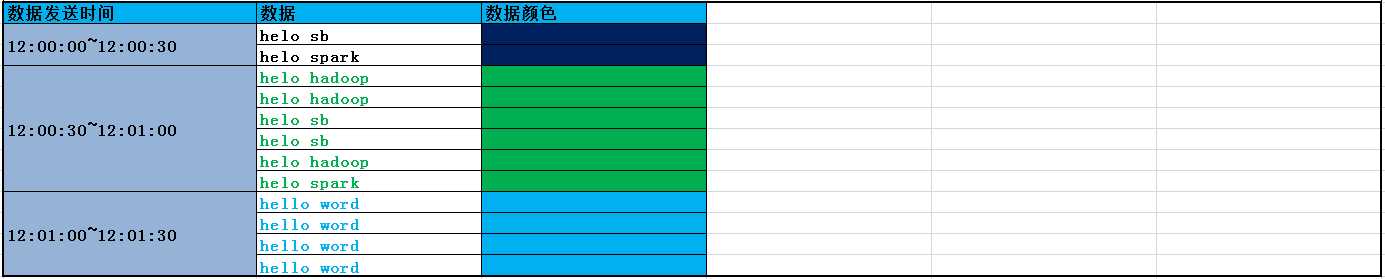
窗口中数据随着时间的变化:
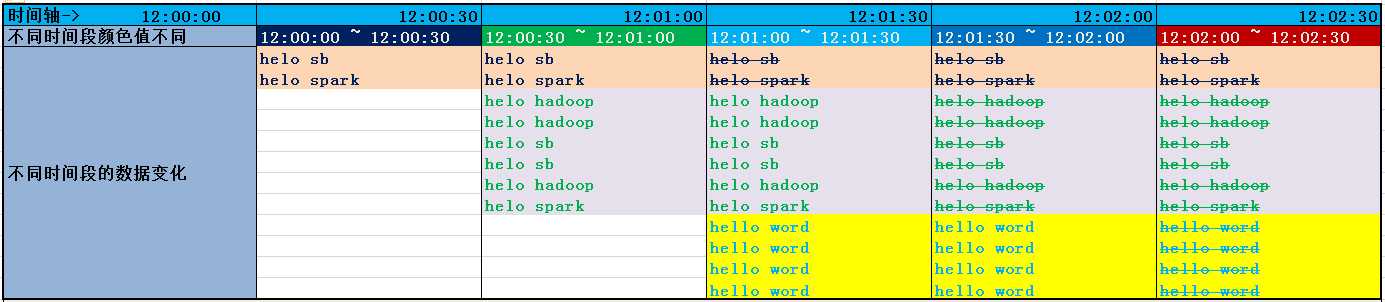
实际工作中上边的代码统计出的结果:

Window操作解读:
// Reduce last 60 seconds of data, every 30 seconds JavaPairDStream<String, Integer> windowedWordCounts = pairs.reduceByKeyAndWindow((i1, i2) -> i1 + i2, Durations.seconds(60), Durations.seconds(30));
上边代码的意义就是:按照key对value进行求count,数据处理范围是60s内的数据,每隔30s统计一次。
Spark Streaming提供了窗口计算,它允许你对滑动窗口上的数据使用变换(transformations)。下图说明了滑动窗口:
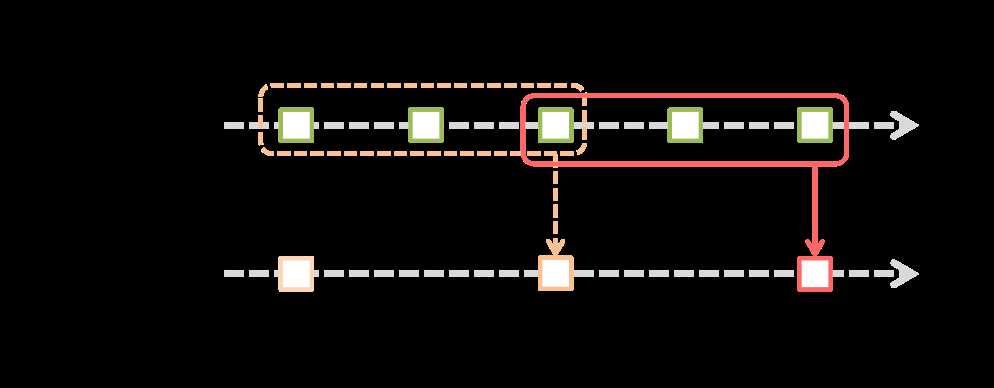
上图介绍了,两个信息:
1)original DStream:Spark Streaming是把一段时间接收到的流作为一个批数据“也就是图中上边绿色框框示意内容”;
2)windowed DStream:窗口每次滑动就是把“滑动长度(时间)”内的数据合并到一起进行一次运算,另外"‘滑动长度(时间)‘内的数据"受两个因素影响:“窗口时长”、“水印时长”。
上边的例子及图可以充分解释为什么每次窗口触发时参与计算的数据受“窗口时长”的影响。“窗口时长”实际上就是定义每次窗口事件处罚时,参与计算的数据长度(范围)。
以上是关于Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十二)Spark Streaming接收流数据及使用窗口函数的主要内容,如果未能解决你的问题,请参考以下文章
Kafka:ZK+Kafka+Spark Streaming集群环境搭建安装zookeeper-3.4.12
Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十七)待整理
Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十九)待整理
Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十一)NIFI1.7.1安装
Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十三)kafka+spark streaming打包好的程序提交时提示虚拟内存不足(Container is running
Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十二)Spark Streaming接收流数据及使用窗口函数