Kafka:ZK+Kafka+Spark Streaming集群环境搭建安装spark2.2.1
Posted yy3b2007com
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka:ZK+Kafka+Spark Streaming集群环境搭建安装spark2.2.1相关的知识,希望对你有一定的参考价值。
如何配置centos虚拟机请参考《Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网。》
如何安装hadoop2.9.0请参考《Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二)安装hadoop2.9.0》
安装spark的服务器:
192.168.0.120 master 192.168.0.121 slave1 192.168.0.122 slave2 192.168.0.123 slave3
从spark官网下载spark安装包:
官网地址:http://spark.apache.org/downloads.html
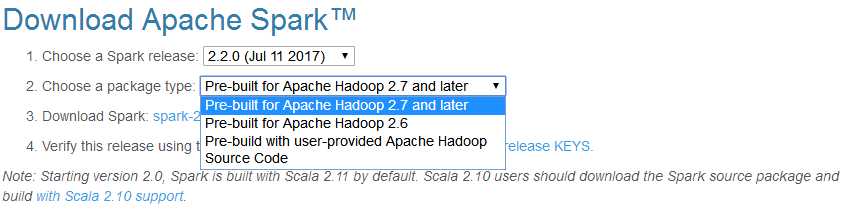
注意:上一篇文章中我们安装了hadoop2.9.0,但是这里没有发现待下载spark对应的hadoop版本可选项中发现hadoop2.9.0,因此也只能选择“Pre-built for Apache Hadoop 2.7 and later”。
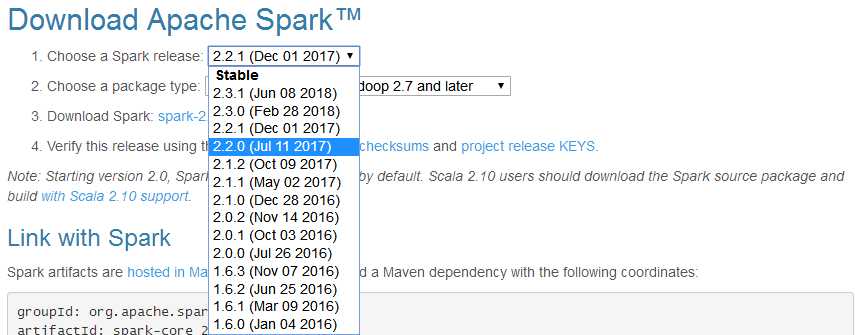
这spark可选版本比较多,就选择“2.2.1(Dec 01 2017)”。
选中后,此时带下来的spark安装包版本信息为:
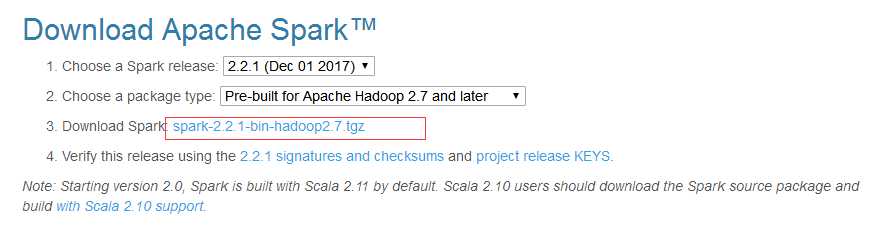
下载“spark-2.2.1-bin-hadoop2.7.tgz”,上传到master的/opt目录下,并解压:
[[email protected] opt]# tar -zxvf spark-2.2.1-bin-hadoop2.7.tgz [[email protected] opt]# ls hadoop-2.9.0 hadoop-2.9.0.tar.gz jdk1.8.0_171 jdk-8u171-linux-x64.tar.gz scala-2.11.0 scala-2.11.0.tgz spark-2.2.1-bin-hadoop2.7 spark-2.2.1-bin-hadoop2.7.tgz [[email protected] opt]#
配置Spark
[[email protected] opt]# ls hadoop-2.9.0 hadoop-2.9.0.tar.gz jdk1.8.0_171 jdk-8u171-linux-x64.tar.gz scala-2.11.0 scala-2.11.0.tgz spark-2.2.1-bin-hadoop2.7 spark-2.2.1-bin-hadoop2.7.tgz [[email protected] opt]# cd spark-2.2.1-bin-hadoop2.7/conf/ [[email protected] conf]# ls docker.properties.template metrics.properties.template spark-env.sh.template fairscheduler.xml.template slaves.template log4j.properties.template spark-defaults.conf.template [[email protected] conf]# scp spark-env.sh.template spark-env.sh [[email protected] conf]# ls docker.properties.template metrics.properties.template spark-env.sh fairscheduler.xml.template slaves.template spark-env.sh.template log4j.properties.template spark-defaults.conf.template [[email protected] conf]# vi spark-env.sh
在spark-env.sh末尾添加以下内容(这是我的配置,你需要根据自己安装的环境情况自行修改):
export SCALA_HOME=/opt/scala-2.11.0
export JAVA_HOME=/opt/jdk1.8.0_171
export HADOOP_HOME=/opt/hadoop-2.9.0
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
SPARK_MASTER_IP=master
SPARK_LOCAL_DIRS=/opt/spark-2.2.1-bin-hadoop2.7
SPARK_DRIVER_MEMORY=1G
注:在设置Worker进程的CPU个数和内存大小,要注意机器的实际硬件条件,如果配置的超过当前Worker节点的硬件条件,Worker进程会启动失败。
vi slaves在slaves文件下填上slave主机名:
[[email protected] conf]# scp slaves.template slaves [[email protected] conf]# vi slaves
配置内容为:
#localhost
slave1
slave2
slave3
将配置好的spark-2.2.1-bin-hadoop2.7文件夹分发给所有slaves吧
scp -r /opt/spark-2.2.1-bin-hadoop2.7 [email protected]:/opt/ scp -r /opt/spark-2.2.1-bin-hadoop2.7 [email protected]:/opt/ scp -r /opt/spark-2.2.1-bin-hadoop2.7 [email protected]:/opt/
注意:此时默认slave1,slave2,slave3上是没有/opt/spark-2.2.1-bin-hadoop2.7,因此直接拷贝可能会出现无权限操作 。
解决方案,分别在slave1,slave2,slave3的/opt下创建spark-2.2.1-bin-hadoop2.7,并分配777权限。
[[email protected] opt]# mkdir spark-2.2.1-bin-hadoop2.7 [[email protected] opt]# chmod 777 spark-2.2.1-bin-hadoop2.7 [[email protected] opt]#
之后,再次操作拷贝就有权限操作了。
启动Spark
在spark安装目录下执行下面命令才行 , 目前的master安装目录在/opt/spark-2.2.1-bin-hadoop2.7
sbin/start-all.sh
此时,我使用非root账户(spark用户名的用户)启动spark,出现master上spark无权限写日志的问题:
[[email protected] opt]$ cd /opt/spark-2.2.1-bin-hadoop2.7 [[email protected] spark-2.2.1-bin-hadoop2.7]$ sbin/start-all.sh mkdir: cannot create directory ‘/opt/spark-2.2.1-bin-hadoop2.7/logs’: Permission denied chown: cannot access ‘/opt/spark-2.2.1-bin-hadoop2.7/logs’: No such file or directory starting org.apache.spark.deploy.master.Master, logging to /opt/spark-2.2.1-bin-hadoop2.7/logs/spark-spark-org.apache.spark.deploy.master.Master-1-master.out /opt/spark-2.2.1-bin-hadoop2.7/sbin/spark-daemon.sh: line 128: /opt/spark-2.2.1-bin-hadoop2.7/logs/spark-spark-org.apache.spark.deploy.master.Master-1-master.out: No such file or directory failed to launch: nice -n 0 /opt/spark-2.2.1-bin-hadoop2.7/bin/spark-class org.apache.spark.deploy.master.Master --host master --port 7077 --webui-port 8080 tail: cannot open ‘/opt/spark-2.2.1-bin-hadoop2.7/logs/spark-spark-org.apache.spark.deploy.master.Master-1-master.out’ for reading: No such file or directory full log in /opt/spark-2.2.1-bin-hadoop2.7/logs/spark-spark-org.apache.spark.deploy.master.Master-1-master.out slave1: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark-2.2.1-bin-hadoop2.7/logs/spark-spark-org.apache.spark.deploy.worker.Worker-1-slave1.out slave3: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark-2.2.1-bin-hadoop2.7/logs/spark-spark-org.apache.spark.deploy.worker.Worker-1-slave3.out slave2: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark-2.2.1-bin-hadoop2.7/logs/spark-spark-org.apache.spark.deploy.worker.Worker-1-slave2.out [[email protected] spark-2.2.1-bin-hadoop2.7]$ cd .. [[email protected] opt]$ su root Password: [[email protected] opt]# chmod 777 spark-2.2.1-bin-hadoop2.7 [[email protected] opt]# su spark [[email protected] opt]$ cd spark-2.2.1-bin-hadoop2.7 [[email protected] spark-2.2.1-bin-hadoop2.7]$ sbin/start-all.sh starting org.apache.spark.deploy.master.Master, logging to /opt/spark-2.2.1-bin-hadoop2.7/logs/spark-spark-org.apache.spark.deploy.master.Master-1-master.out slave2: org.apache.spark.deploy.worker.Worker running as process 3153. Stop it first. slave3: org.apache.spark.deploy.worker.Worker running as process 3076. Stop it first. slave1: org.apache.spark.deploy.worker.Worker running as process 3241. Stop it first. [[email protected] spark-2.2.1-bin-hadoop2.7]$ sbin/stop-all.sh slave1: stopping org.apache.spark.deploy.worker.Worker slave3: stopping org.apache.spark.deploy.worker.Worker slave2: stopping org.apache.spark.deploy.worker.Worker stopping org.apache.spark.deploy.master.Master [[email protected] spark-2.2.1-bin-hadoop2.7]$ sbin/start-all.sh starting org.apache.spark.deploy.master.Master, logging to /opt/spark-2.2.1-bin-hadoop2.7/logs/spark-spark-org.apache.spark.deploy.master.Master-1-master.out slave1: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark-2.2.1-bin-hadoop2.7/logs/spark-spark-org.apache.spark.deploy.worker.Worker-1-slave1.out slave3: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark-2.2.1-bin-hadoop2.7/logs/spark-spark-org.apache.spark.deploy.worker.Worker-1-slave3.out slave2: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark-2.2.1-bin-hadoop2.7/logs/spark-spark-org.apache.spark.deploy.worker.Worker-1-slave2.out
解决方案:给master的spark安装目录也分配777操作权限。
验证 Spark 是否安装成功
用jps检查,在 master 上应该有以下几个进程:
$ jps 7949 Jps 7328 SecondaryNameNode 7805 Master 7137 NameNode 7475 ResourceManager
在 slave 上应该有以下几个进程:
$jps 3132 DataNode 3759 Worker 3858 Jps 3231 NodeManager
进入Spark的Web管理页面: http://192.168.0.120:8080
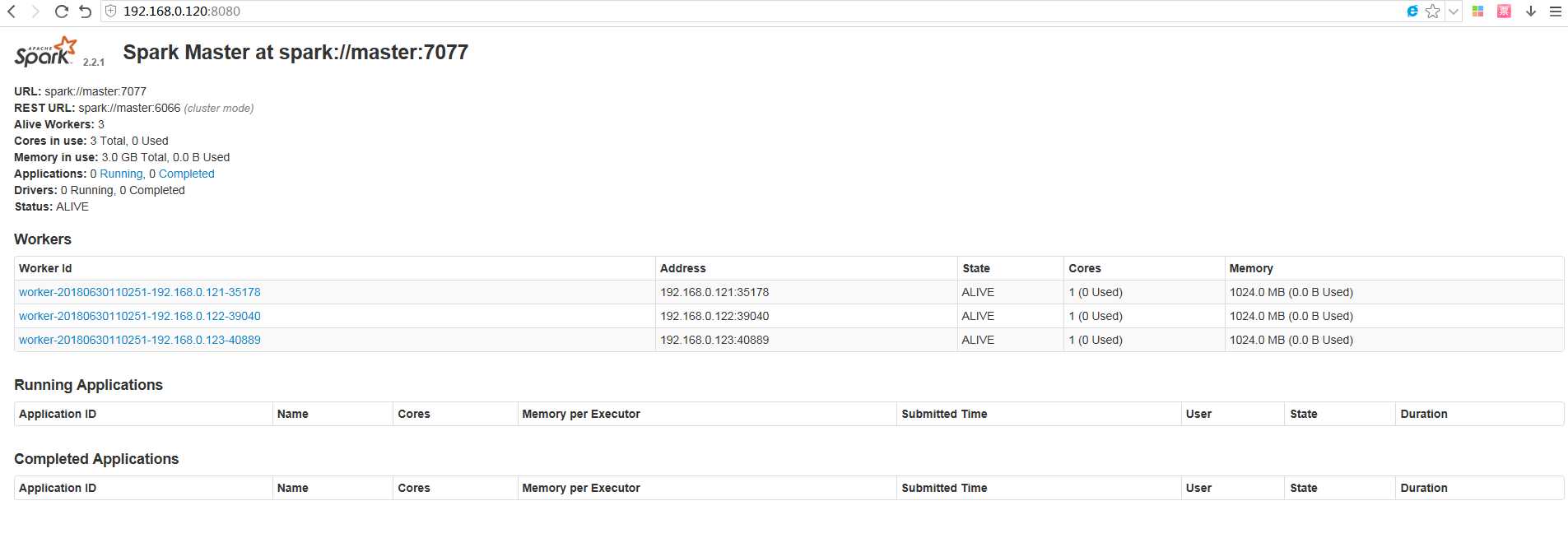
运行示例
本地方式两线程运行测试:
[[email protected] spark-2.2.1-bin-hadoop2.7]$ cd /opt/spark-2.2.1-bin-hadoop2.7 [[email protected] spark-2.2.1-bin-hadoop2.7]$ ./bin/run-example SparkPi 10 --master local[2]

Spark Standalone 集群模式运行
[[email protected] spark-2.2.1-bin-hadoop2.7]$ cd /opt/spark-2.2.1-bin-hadoop2.7 [[email protected] spark-2.2.1-bin-hadoop2.7]$ ./bin/spark-submit > --class org.apache.spark.examples.SparkPi > --master spark://master:7077 > examples/jars/spark-examples_2.11-2.2.1.jar > 100
此时是可以从spark监控界面查看到运行状况:
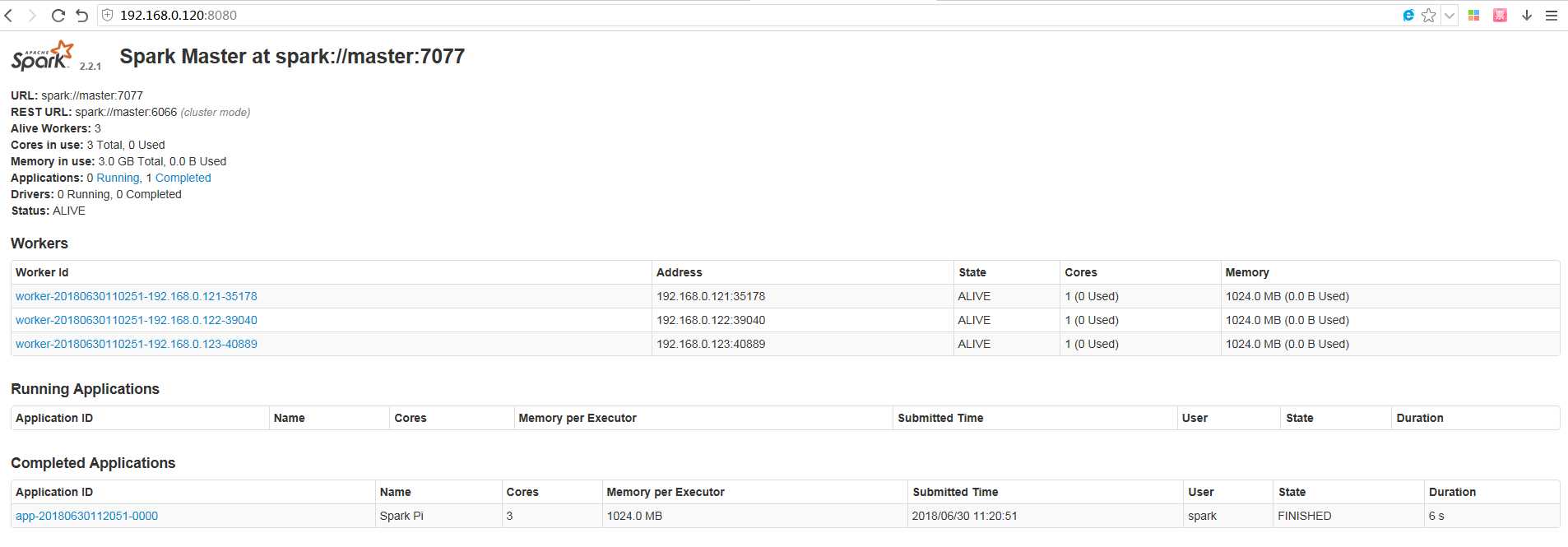
Spark on YARN 集群上 yarn-cluster 模式运行
[[email protected] spark-2.2.1-bin-hadoop2.7]$ cd /opt/spark-2.2.1-bin-hadoop2.7 [[email protected] spark-2.2.1-bin-hadoop2.7]$ ./bin/spark-submit > --class org.apache.spark.examples.SparkPi > --master yarn-cluster > /opt/spark-2.2.1-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.2.1.jar > 10
注意:Spark on YARN 支持两种运行模式,分别为yarn-cluster和yarn-client,具体的区别可以看这篇博文,从广义上讲,yarn-cluster适用于生产环境;而yarn-client适用于交互和调试,也就是希望快速地看到application的输出。
以上是关于Kafka:ZK+Kafka+Spark Streaming集群环境搭建安装spark2.2.1的主要内容,如果未能解决你的问题,请参考以下文章
Kafka:ZK+Kafka+Spark Streaming集群环境搭建安装zookeeper-3.4.12
Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十七)待整理
Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十九)待整理
Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十一)NIFI1.7.1安装
Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十三)kafka+spark streaming打包好的程序提交时提示虚拟内存不足(Container is running
Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十二)Spark Streaming接收流数据及使用窗口函数