凝聚型层次聚类算法对数据集进行分类时,如何对合并的新簇计算簇间距离?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了凝聚型层次聚类算法对数据集进行分类时,如何对合并的新簇计算簇间距离?相关的知识,希望对你有一定的参考价值。
如图,合并了{1,2}之后如何计算呀,网上的例题没看懂

中心距离:每两簇中心点(每簇内各点在各维度的平均数)之间的距离(这道题你用这个就好了)
最短距离:每两簇最近点的距离
最长距离:每两簇最远点距离
另外聚类时的距离算法也有很多种,常用的有两种:
曼哈顿距离:绝对差之和
欧几里得距离:平方差开根,也就是你截图的这种 参考技术A 取x1,x3中点,继续按上面的操作
机器学习——层次聚类算法
层次聚类方法(我们做算法的用的很少)对给定的数据集进行层次的分解或者合并,直到满足某种条件
为止,传统的层次聚类算法主要分为两大类算法:
●凝聚的层次聚类: AGNES算法(AGglomerative NESting)==>采用自底向.上的策略。
最初将每个对象作为一个簇,然后这些簇根据某些准则被一步一步合并, 两个簇间的
距离可以由这两个不同簇中距离最近的数据点的相似度来确定;聚类的合并过程反复
进行直到所有的对象满足簇数目。凝聚类的用的比较多一些
●分裂的层次聚类: DIANA算法(DIvisive ANALysis)== >采用自顶向下的策略。首先将
所有对象置于一个簇中, 然后按照某种既定的规则逐渐细分为越来越小的簇(比如最大
的欧式距离),直到达到某个终结条件(簇数目或者簇距离达到阈值)。
优缺点:
简单,理解容易.
合并点/分裂点选择不太容易
合并/分裂的操作不能进行撤销
大数据集不太适合(数据量大到内存中放不下)
执行效率较低O(t*n2),t为迭代次数, n为样本点数
簇间距离:不止是层次聚类可以做簇的合并

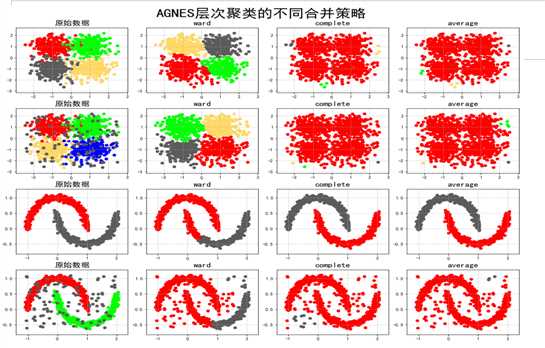
层次聚类合并策略:ward为最小距离,complete为最大距离,average为平均距离
其中,上两行为凸形数据。游离在凸形数据边缘的异常点检测用最大距离比较好
聚类的话用最小距离比较好
非凸形数据异常点检测的话,层次聚类不合适。
层次聚类优化算法(说实话,没什么用):
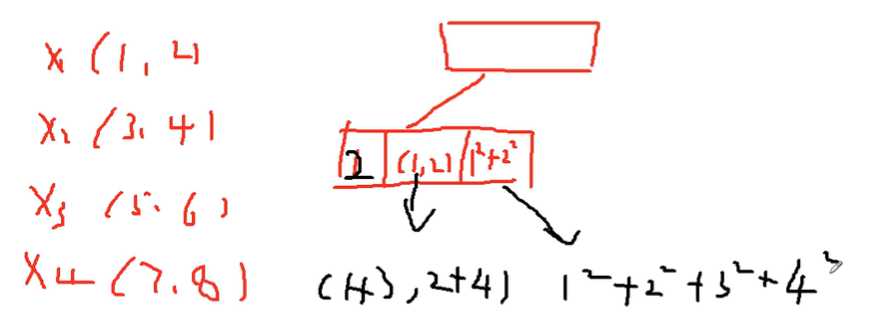
假设有x1,x2,x3,x4四个数据,给定一个阈值为5,随机拿一个样本,比如是x1,,那么左子树上分为三个组,第一个组是样本个数,1个样本,第二个组是x1的坐标,第三个组是横纵坐标平方和。
再随机取个样本,比如x2,计算和x1的距离,小于阈值5的话,那么在一个簇上,第一个组是2个样本,第二个组是横纵坐标分别相加,第三个组是所有横纵坐标的平方和。
目的:求均值时方便,不就是第二个组除以第一个组么。第三个维度是为了计算下一个样本点到簇中心的距离
以上是关于凝聚型层次聚类算法对数据集进行分类时,如何对合并的新簇计算簇间距离?的主要内容,如果未能解决你的问题,请参考以下文章