ClickHouse 分布式原理:Distributed引擎
Posted 凌桓丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ClickHouse 分布式原理:Distributed引擎相关的知识,希望对你有一定的参考价值。
文章目录
Distributed引擎
Distributed表引擎是分布式表的代名词,它自身不存储任何数据,而是作为数据分片的透明代理,能够自动路由数据至集群中的各个节点,所以Distributed表引擎需要和其他数据表引擎一起协同工作。
ClickHouse并不像其他分布式系统那样,拥有高度自动化的分片功能。ClickHouse提供了本地表(Local Table) 与 分布式表(Distributed Table) 的概念
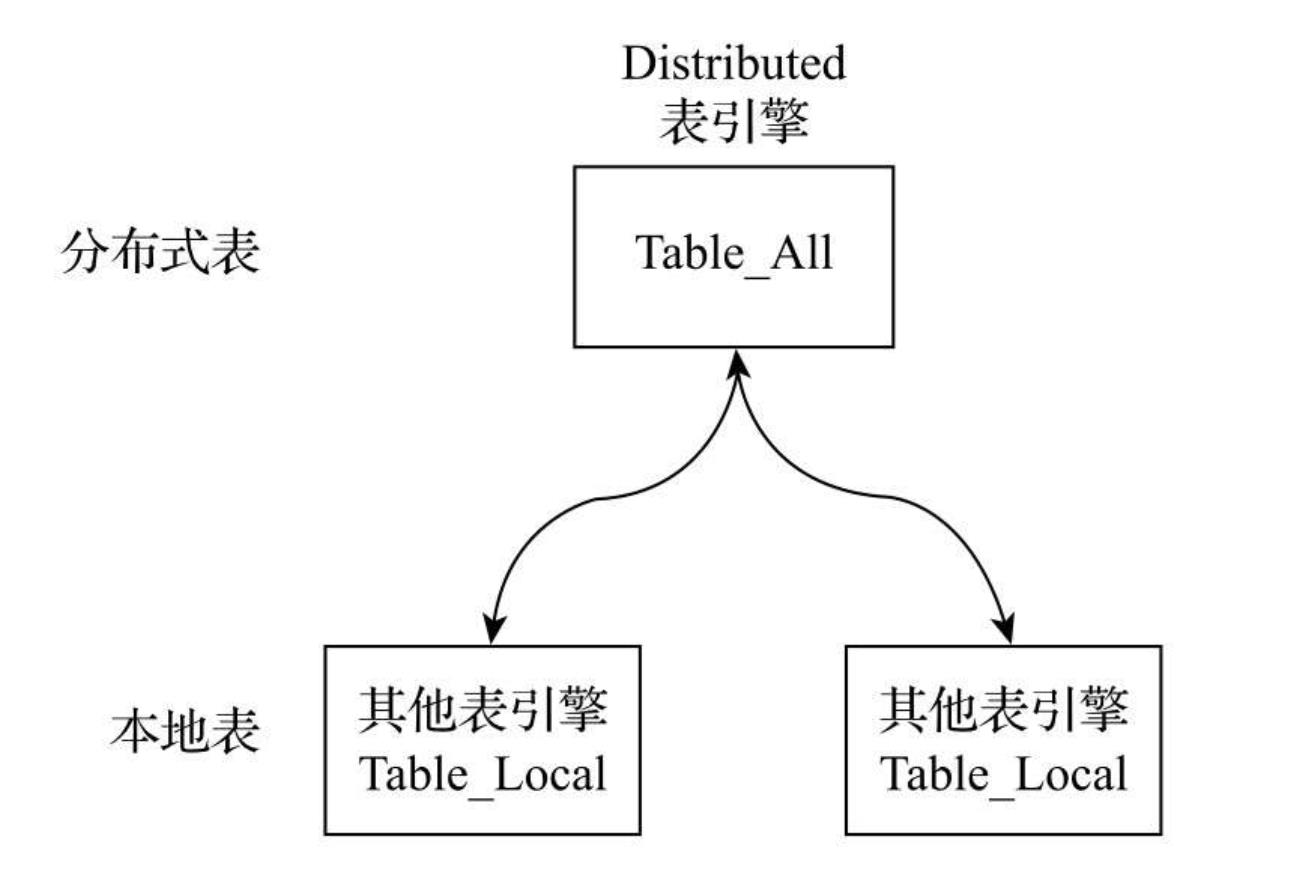
- 本地表:通常以_local为后缀进行命名。本地表是承接数据的载体,可以使用非Distributed的任意表引擎,一张本地表对应了一个数据分片。
- 分布式表:通常以_all为后缀进行命名。分布式表只能使用Distributed表引擎,它与本地表形成一对多的映射关系,日后将通过分布式表代理操作多张本地表。
分布式写入流程
在向集群内的分片写入数据时,通常有两种思路
- 借助外部计算系统,事先将数据均匀分片,再借由计算系统直接将数据写入ClickHouse集群的各个本地表。
- 通过Distributed表引擎代理写入分片数据。
第一种方案通常拥有更好的写入性能,因为分片数据是被并行点对点写入的。但是这种方案的实现主要依赖于外部系统,而不在于ClickHouse自身,所以这里主要会介绍第二种思路。为了便于理解整个过程,这里会将分片写入、副本复制拆分成两个部分进行讲解。
数据写入分片
-
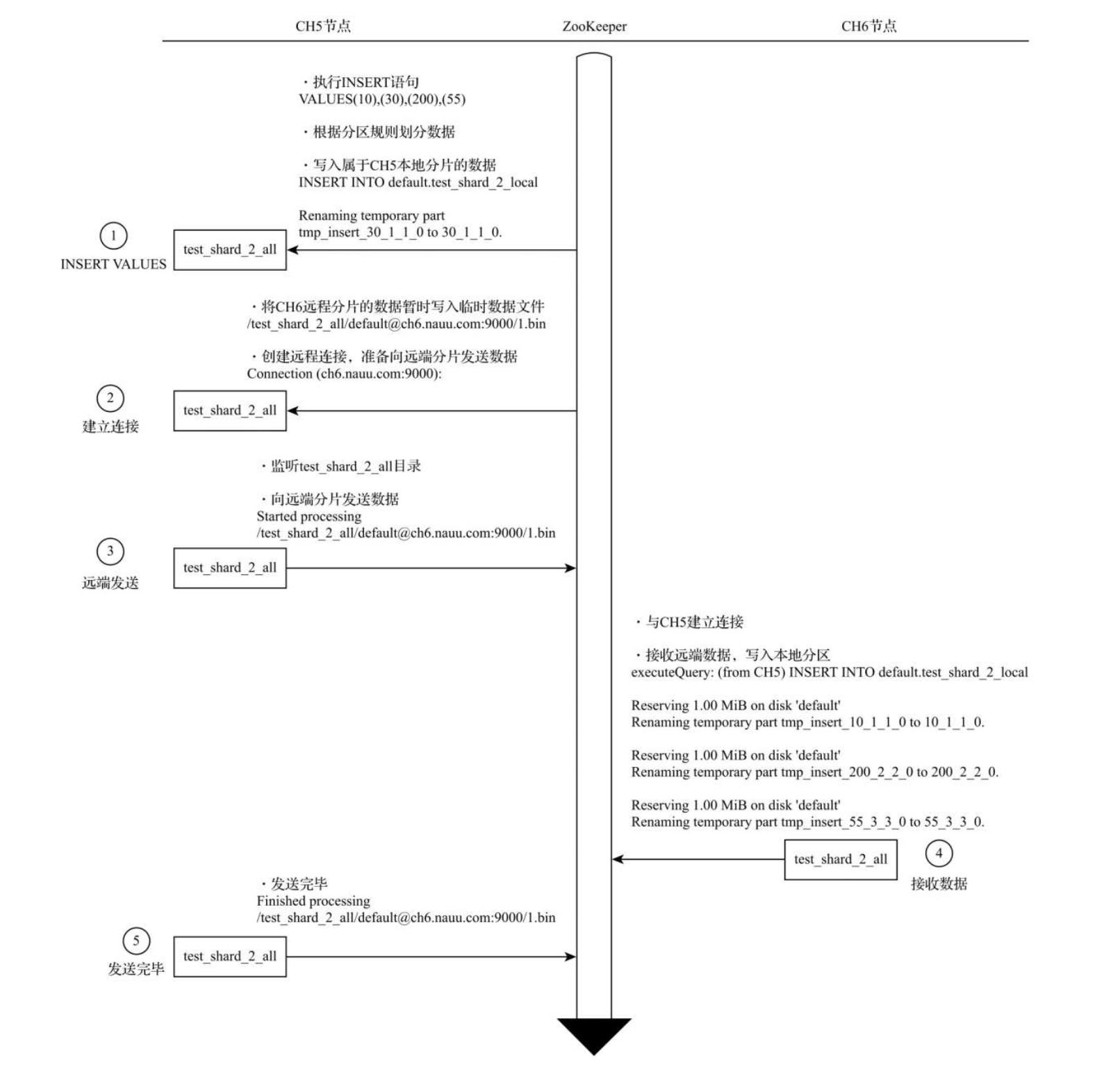
在第一个分片节点写入本地分片数据:首先在CH5节点,对分布式表test_shard_2_all执行
INSERT查询,尝试写入10、30、200和55四行数据。执行之后分布式表主要会做两件事情:-
根据分片规则划分数据
-
将属于当前分片的数据直接写入本地表test_shard_2_local。
-
-
第一个分片建立远端连接,准备发送远端分片数据:将归至远端分片的数据以分区为单位,分别写入/test_shard_2_all存储目录下的临时bin文件,接着,会尝试与远端分片节点建立连接。
-
第一个分片向远端分片发送数据:此时,会有另一组监听任务负责监听/test_shard_2_all目录下的文件变化,这些任务负责将目录数据发送至远端分片,其中,每份目录将会由独立的线程负责发送,数据在传输之前会被压缩。
-
第二个分片接收数据并写入本地:CH6分片节点确认建立与CH5的连接,在接收到来自CH5发送的数据后,将它们写入本地表。
-
由第一个分片确认完成写入:最后,还是由CH5分片确认所有的数据发送完毕。
可以看到,在整个过程中,Distributed表负责所有分片的写入工作。本着谁执行谁负责的原则,在这个示例中,由CH5节点的分布式表负责切分数据,并向所有其他分片节点发送数据。
在由Distributed表负责向远端分片发送数据时,有异步写和同步写两种模式:
- 如果是异步写,则在Distributed表写完本地分片之后,
INSERT查询就会返回成功写入的信息; - 如果是同步写,则在执行
INSERT查询之后,会等待所有分片完成写入。
副本复制数据
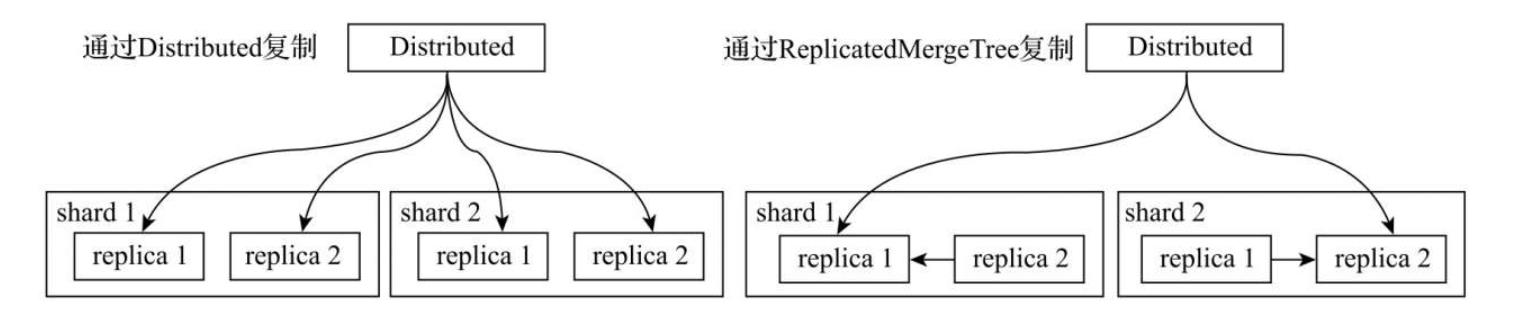
如果在集群的配置中包含了副本,那么除了刚才的分片写入流程之外,还会触发副本数据的复制流程。数据在多个副本之间,有两种复制实现方式:
-
Distributed表引擎:副本数据的写入流程与分片逻辑相同,所以Distributed会同时负责分片和副本的数据写入工作。但在这种实现方案下,它很有可能会成为写入的单点瓶颈,所以就有了接下来将要说明的第二种方案。
-
ReplicatedMergeTree表引擎:如果使用ReplicatedMergeTree作为本地表的引擎,则在该分片内,多个副本之间的数据复制会交由ReplicatedMergeTree自己处理,不再由Distributed负责,从而为其减负。
分布式查询流程
与数据写入有所不同,在面向集群查询数据的时候,只能通过Distributed表引擎实现。当Distributed表接收到SELECT查询的时候,它会依次查询每个分片的数据,再合并汇总返回,流程如下:
多副本的路由规则
在查询数据的时候,如果集群中的某一个分片有多个副本,此时Distributed引擎就会通过负载均衡算法从众多的副本中选取一个,负载均衡算法有以下四种。
在ClickHouse的服务节点中,拥有一个全局计数器errors_count,当服务发生任何异常时,该计数累积加1。
- random(默认):random算法会选择
errors_count错误数量最少的副本,如果多个副本的errors_count计数相同,则在它们之中随机选择一个。 - nearest_hostname:nearest_hostname可以看作random算法的变种,首先它会选择
errors_count错误数量最少的副本,如果多个副本的errors_count计数相同,则选择集群配置中host名称与当前host最相似的一个。而相似的规则是以当前host名称为基准按字节逐位比较,找出不同字节数最少的一个。 - in_order:in_order同样可以看作random算法的变种,首先它会选择
errors_count错误数量最少的副本,如果多个副本的errors_count计数相同,则按照集群配置中replica的定义顺序逐个选择。 - first_or_random:first_or_random可以看作in_order算法的变种,首先它会选择
errors_count错误数量最少的副本,如果多个副本的errors_count计数相同,它首先会选择集群配置中第一个定义的副本,如果该副本不可用,则进一步随机选择一个其他的副本。
多分片查询的流程
分布式查询与分布式写入类似,同样本着谁执行谁负责的原则,它会由接收SELECT查询的Distributed表,并负责串联起整个过程。
首先它会将针对分布式表的SQL语句,按照分片数量将查询拆分成若干个针对本地表的子查询,然后向各个分片发起查询,最后再汇总各个分片的返回结果。
--查询分布式表
SELECT * FROM distributor_table
--转换为查询本地表,并将该命令推送到各个分片节点上执行
SELECT * FROM local_table
如下图
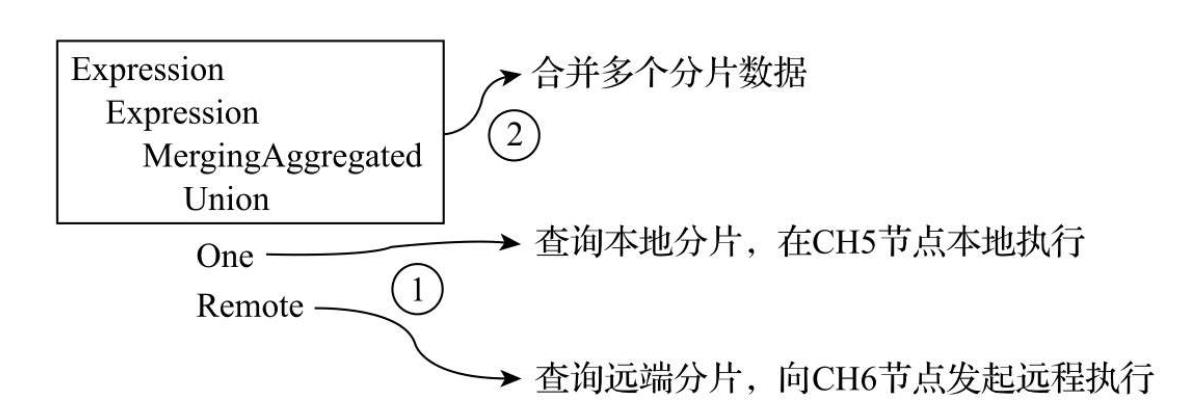
- 查询各个分片数据:One和Remote步骤是并行执行的,它们分别负责了本地和远端分片的查询动作。
- 合并返回结果:多个分片数据均查询返回后,在执行节点将所有数据
union合并
使用Global优化分布式子查询
如果现在有一项查询需求,例如要求找到同时拥有两个仓库的用户,应该如何实现?对于这类交集查询的需求,可以使用IN子查询,此时你会面临两难的选择:IN查询的子句应该使用本地表还是分布式表?(使用JOIN面临的情形与IN类似)。
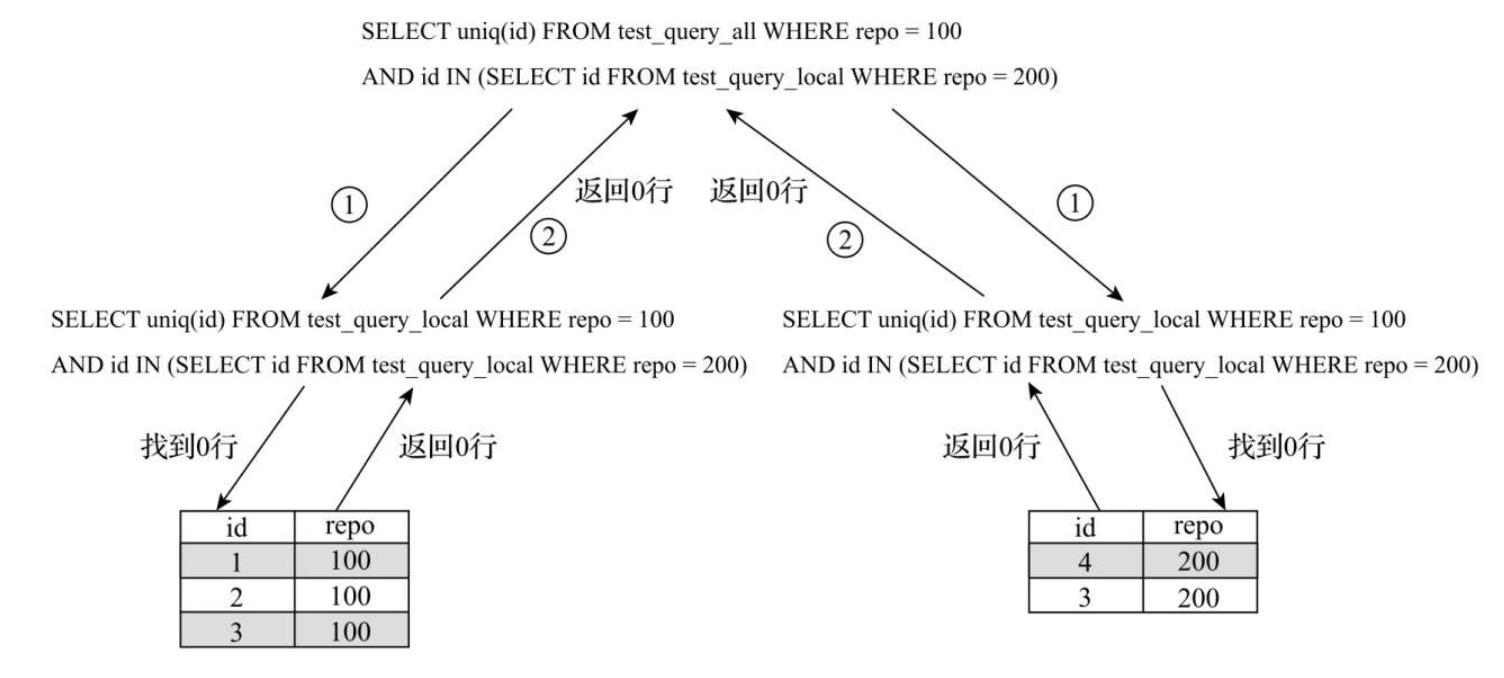
使用本地表的问题(可能查询不到结果)
如果在IN查询中使用本地表时,如下列语句
SELECT
uniq(id)
FROM
distributed_table
WHERE
repo = 100 AND id IN (SELECT id FROM local_table WHERE repo = 200)
在实际执行时,分布式表在接收到查询后会将上述SQL替换成本地表的形式,再发送到每个分片进行执行,此时,每个分片上实际执行的是以下语句
SELECT
uniq(id)
FROM
local_table
WHERE
repo = 100 AND id IN (SELECT id FROM local_table WHERE repo = 200)
那么此时查询的最终结果就有可能是错误的,因为在单个分片上只保存了部分的数据,这就导致该SQL语句可能没有匹配到任何数据,如下图
使用分布式表的问题(查询请求被放大N^2倍,N为节点数量)
如果在IN查询中使用本地表时,如下列语句
SELECT
uniq(id)
FROM
distributed_table
WHERE
repo = 100 AND id IN (SELECT id FROM distributed_table WHERE repo = 200)
对于此次查询,每个分片节点不仅需要查询本地表,还需要再次向其他的分片节点再次发起远端查询,如下图
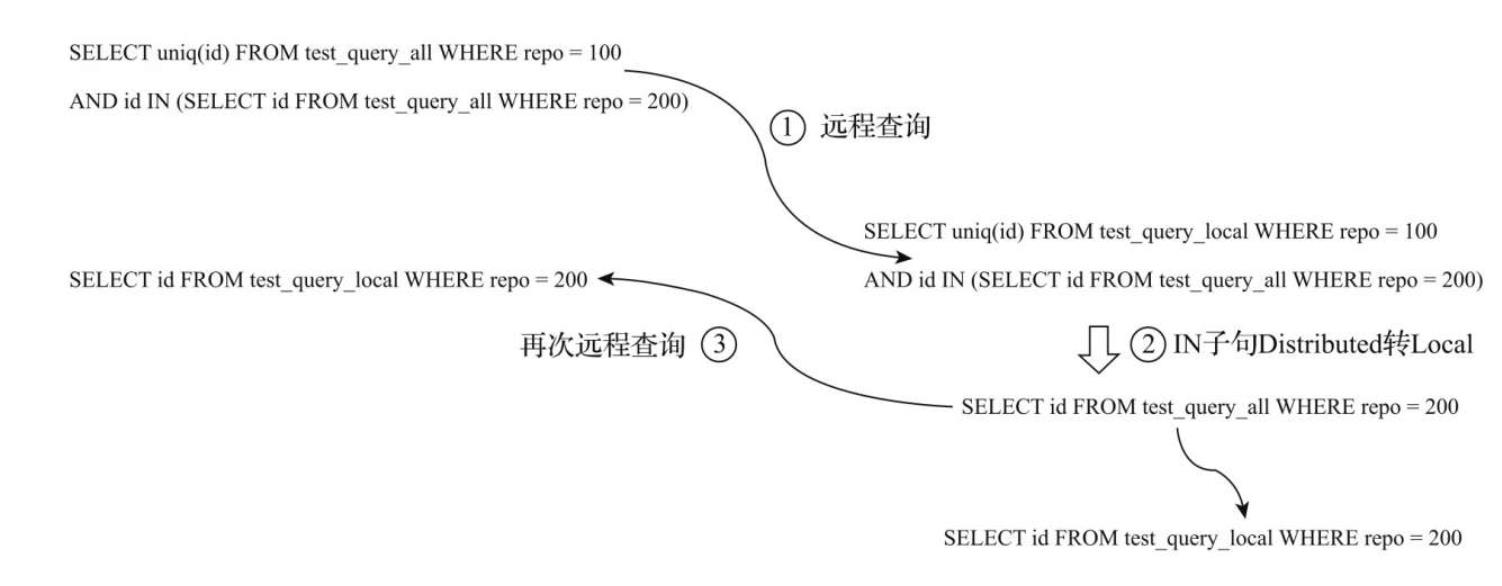
因此可以得出结论,在IN查询子句使用分布式表的时候,虽然查询的结果得到了保证,但是查询请求会被放大N的平方倍,其中N等于集群内分片节点的数量,假如集群内有10个分片节点,则在一次查询的过程中,会最终导致100次的查询请求,这显然是不可接受的。
使用GLOBAL优化查询
为了解决查询放大的问题,我们可以使用GLOBAL IN或GLOBAL JOIN进行优化,下面就简单介绍一下GLOBAL的执行流程
SELECT
uniq(id)
FROM
distributed_table
WHERE
repo = 100 AND id GLOBAL IN (SELECT id FROM distributed_table WHERE repo = 200)
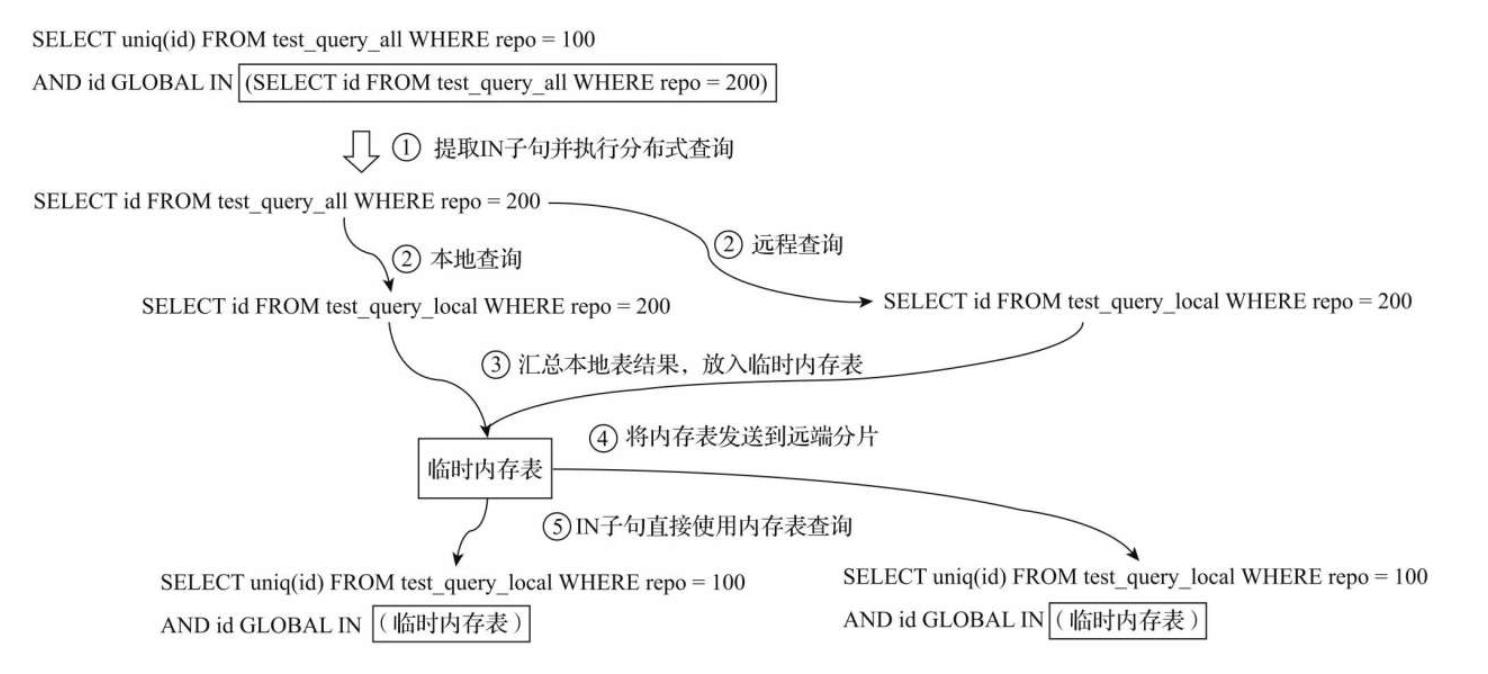
如上图,主要有以下五个步骤
- 将
IN子句单独提出,发起了一次分布式查询。 - 将分布式表转local本地表后,分别在本地和远端分片执行查询。
- 将
IN子句查询的结果进行汇总,并放入一张临时的内存表进行保存。 - 将内存表发送到远端分片节点。
- 将分布式表转为本地表后,开始执行完整的SQL语句,
IN子句直接使用临时内存表的数据。
在使用GLOBAL修饰符之后,ClickHouse使用内存表临时保存了IN子句查询到的数据,并将其发送到远端分片节点,以此到达了数据共享的目的,从而避免了查询放大的问题。由于数据会在网络间分发,所以需要特别注意临时表的大小,IN或者JOIN子句返回的数据不宜过大。如果表内存在重复数据,也可以事先在子句SQL中增加DISTINCT以实现去重。
以上是关于ClickHouse 分布式原理:Distributed引擎的主要内容,如果未能解决你的问题,请参考以下文章
ClickHouse 分布式原理:Distributed引擎
ClickHouse 副本协同原理:ReplicatedMergeTree引擎
ClickHouse 副本协同原理:ReplicatedMergeTree引擎
Colocate Join :ClickHouse的一种高性能分布式join查询模型