Buffer Pool 为了让 MySQL 变快都做了什么?
Posted 程序猿阿星
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Buffer Pool 为了让 MySQL 变快都做了什么?相关的知识,希望对你有一定的参考价值。
前言
大家好,我是阿星,又跟大家见面了。
相信很多小伙伴在面试中都被问过「为什么要用缓存?」,大部分人都是回答:「减少数据库的磁盘IO压力」。
但是mysql真的有如此不堪吗?
每次增删改查都要去走磁盘IO吗?
今天就聊聊InnoDB对Buffer Pool的奇思妙想。
Buffer Pool
先梳理出问题,再思考如何解决问题。
假设我们就是InnoDB,我们要如何去解决磁盘IO问题?
这个简单,做缓存就好了,所以MySQL需要申请一块内存空间,这块内存空间称为Buffer Pool。

Buffer Pool是申请下来了,但是Buffer Pool里面放什么,要怎么规划?
缓存页
MySQL数据是以页为单位,每页默认16KB,称为数据页,在Buffer Pool里面会划分出若干个缓存页与数据页对应。

感觉还少了点什么,我们如何知道缓存页对应那个数据页呢?
描述数据
所有还需要缓存页的元数据信息,可以称为描述数据,它与缓存页一一对应,包含一些所属表空间、数据页的编号、Buffer Pool中的地址等等。

后续对数据的增删改查都是在Buffer Pool里操作
- 查询:从磁盘加载到缓存,后续直接查缓存
- 插入:直接写入缓存
- 更新删除:缓存中存在直接更新,不存在加载数据页到缓存更新
可能有小伙伴担心,MySQL宕机了,数据不就全丢了吗?
这个不用担心,因为InnoDB提供了WAL技术(Write-Ahead Logging),通过redo log让MySQL拥有了崩溃恢复能力。
再配合空闲时,会有异步线程做缓存页刷盘,保证数据的持久性与完整性。

如果不能理解redo log是如何恢复数据的,可以看看阿星前面两篇文章
另外,直接更新数据的缓存页称为脏页,缓存页刷盘后称为干净页
Free链表
MySQL数据库启动时,按照设置的Buffer Pool大小,去找操作系统申请一块内存区域,作为Buffer Pool(假设申请了512MB)。
申请完毕后,会按照默认缓存页的16KB以及对应的800Byte的描述数据,在Buffer Pool中划分出来一个一个的缓存页和它们对应的描述数据。

MySQL运行起来后,会不停的执行增删改查,需要从磁盘读取一个一个的数据页放入Buffer Pool对应的缓存页里,把数据缓存起来,以后就可以在内存里执行增删改查。

但是这个过程必然涉及一个问题,哪些缓存页是空闲的?
为了解决这个问题,我们使用链表结构,把空闲缓存页的描述数据放入链表中,这个链表称为free链表。
针对free链表我们要做如下设计

- 新增
free基础节点 - 描述数据添加
free节点指针
最终呈现出来的,是由空闲缓存页的描述数据组成的free链表。
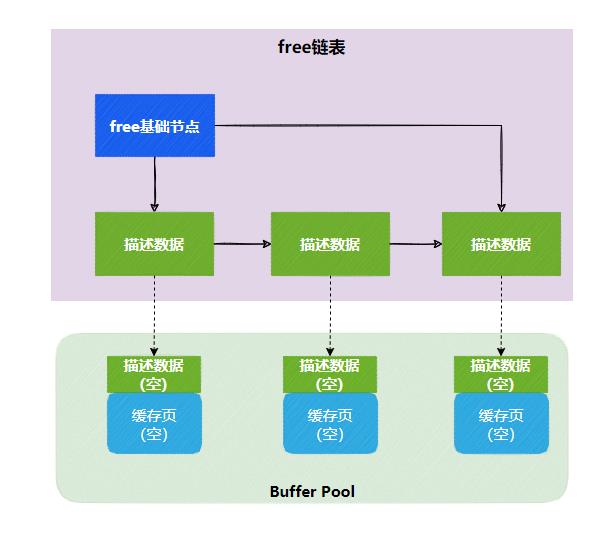
有了free链表之后,我们只需要从free链表获取一个描述数据,就可以获取到对应的缓存页。

往描述数据与缓存页写入数据后,就将该描述数据移出free链表。
缓存页哈希表
数据页是缓存进去了,但是又一个问题来了。
下次查询数据时,如何在Buffer Pool里快速定位到对应的缓存页呢?
难道需要一个非空闲的描述数据链表,再通过表空间号+数据页编号遍历查找吗?
这样做也可以实现,但是效率不太高,时间复杂度是O(N)。

所以我们可以换一个结构,使用哈希表来缓存它们间的映射关系,时间复杂度是O(1)。

表空间号+数据页号,作为一个key,然后缓存页的地址作为value。
每次加载数据页到空闲缓存页时,就写入一条映射关系到缓存页哈希表中。

后续的查询,就可以通过缓存页哈希表路由定位了。
Flush链表
还记得之前有说过「空闲时会有异步线程做缓存页刷盘,保证数据的持久性与完整性」吗?
新问题来了,难道每次把Buffer Pool里所有的缓存页都刷入磁盘吗?
当然不能这样做,磁盘IO开销太大了,应该把脏页刷入磁盘才对(更新过的缓存页)。
可是我们怎么知道,那些缓存页是脏页?
很简单,参照free链表,弄个flush链表出来就好了,只要缓存页被更新,就将它的描述数据加入flush链表。
针对flush链表我们要做如下设计
- 新增
flush基础节点 - 描述数据添加
flush节点指针

最终呈现出来的,是由更新过数据的缓存页描述数据组成的flush链表。

后续异步线程都从flush链表刷缓存页,当Buffer Pool内存不足时,也会优先刷flush链表里的缓存页。
LRU链表
目前看来Buffer Pool的功能已经比较完善了。

但是仔细思考下,发现还有一个问题没处理。
MySQL数据库随着系统的运行会不停的把磁盘上的数据页加载到空闲的缓存页里去,因此free链表中的空闲缓存页会越来越少,直到没有,最后磁盘的数据页无法加载。

为了解决这个问题,我们需要淘汰缓存页,腾出空闲缓存页。
可是我们要优先淘汰那些缓存页? 总不能一股脑直接全部淘汰吧?
这里就要借鉴LRU算法思想,把最少使用的缓存页淘汰(命中率低),提供LRU链表出来。
针对LRU链表我们要做如下设计
- 新增
LRU基础节点 - 描述数据添加
LRU节点指针

实现思路也很简单,只要是查询或修改过缓存页,就把该缓存页的描述数据放入链表头部,也就说近期访问的数据一定在链表头部。

当free链表为空的时候,直接淘汰LRU链表尾部缓存页即可。
LRU链表优化
麻雀虽小五脏俱全,基本Buffer Pool里与缓存页相关的组件齐全了。

但是缓存页淘汰这里还有点问题,如果仅仅只是使用LRU链表的机制,有两个场景会让热点数据被淘汰。
- 预读机制
- 全表扫描
预读机制是指MySQL加载数据页时,可能会把它相邻的数据页一并加载进来(局部性原理)。
这样会带来一个问题,预读进来的数据页,其实我们没有访问,但是它却排在前面。
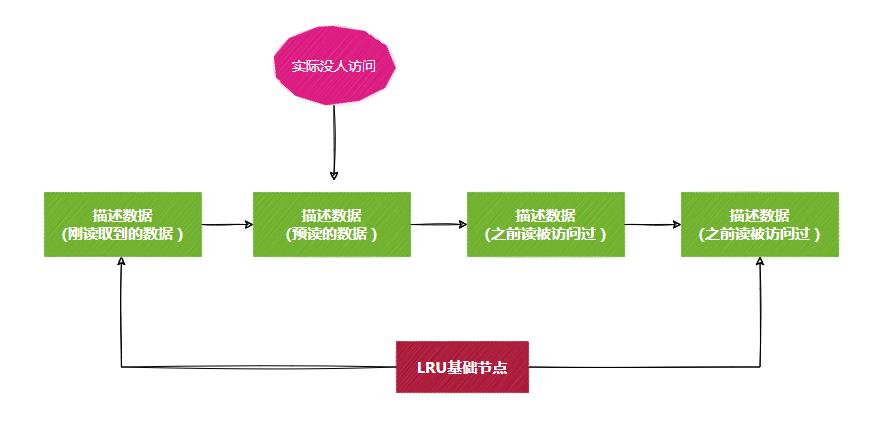
正常来说,淘汰缓存页时,应该把这个预读的淘汰,结果却把尾部的淘汰了,这是不合理的。
我们接着来看第二个场景全表扫描,如果表数据量大,大量的数据页会把空闲缓存页用完。
最终LRU链表前面都是全表扫描的数据,之前频繁访问的热点数据全部到队尾了,淘汰缓存页时就把热点数据页给淘汰了。
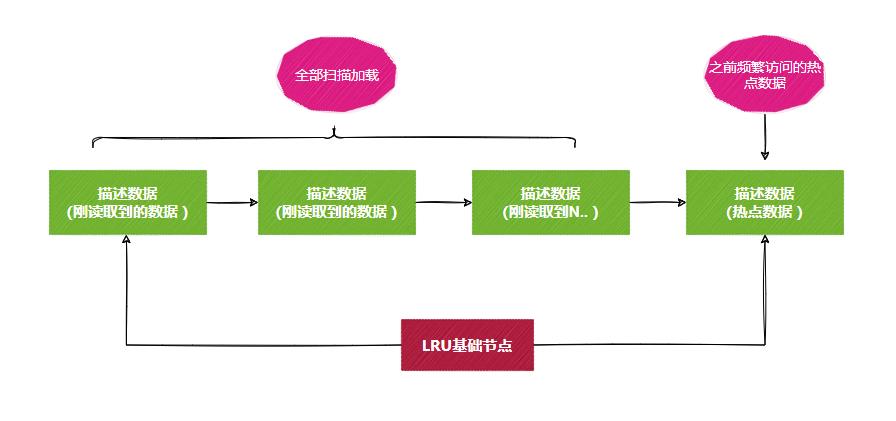
为了解决上述的问题。
我们需要给LRU链表做冷热数据分离设计,把LRU链表按一定比例,分为冷热区域,热区域称为young区域,冷区域称为old区域。
以7:3为例,young区域70%,old`区域30%

如上图所示,数据页第一次加载进缓存页的时候,是先放入冷数据区域的头部,如果1秒后再次访问缓存页,则会移动到热区域的头部。
这样就保证了预读机制与全表扫描加载的数据都在链表队尾。
young区域其实还可以做一个小优化,为了防止young区域节点频繁移动到表头。
young区域前面1/4被访问不会移动到链表头部,只有后面的3/4被访问了才会。
记住是按照某个比例将
LRU链表分成两部分,不是某些节点固定是young区域的,某些节点固定是old区域的,随着程序的运行,某个节点所属的区域也可能发生变化。
小结
其实MySQL就是这样实现Buffer Pool缓存页的,只不过它里面的链表全是双向链表,阿星这里偷个懒,但是不影响理解思路。
读到这里,我相信大家对Buffer Pool缓存页有了深刻的认知,也知道从一个增删改查时如何缓存数据、定位缓存、缓存刷盘、缓存淘汰。
这里留问题给大家思考,Free、Flush、LRU这三个链表之间的联系,随着MySQL一直在运行,它们会产生怎样的联动。
MySQL好文推荐
- 1-CURD这么多年,你有了解过MySQL的架构设计吗?
- 2-浅谈 MySQL InnoDB 的内存组件
- 3-聊聊redo log是什么?
- 4-不会吧,不会吧,还有人不知道 binlog ?
- 5-redo log与binlog间的破事
福利
以上是关于Buffer Pool 为了让 MySQL 变快都做了什么?的主要内容,如果未能解决你的问题,请参考以下文章
Buffer Pool 为了让 MySQL 变快都做了什么?
Buffer Pool 为了让 MySQL 变快都做了什么?
MySql 缓冲池(buffer pool) 和 写缓存(change buffer) 转