2020年第一篇, 比预计的时间延迟半个月, 突如其来的疫情让人不知所措, 应该没有哪个春节像今年一样了吧, 但愿疫情能够尽快过去, 一切早日恢复正常!
重新整理和复习mysql相关知识, 其实主要是重新看之前记录的思维导图, 然后通过<<MySQL实战45讲>>和<<架构师之路>>来补充和温习, 所以以下很多都以截图的形式放上来了.
buffer pool
InnoDB的缓冲池缓存什么?有什么用?
缓存表数据与索引数据,把磁盘上的数据加载到缓冲池,避免每次访问都进行磁盘IO,起到加速访问的作用
总结:
- 缓冲池(buffer pool)是一种常见的降低磁盘访问的机制;
- 缓冲池通常以页(page)为单位缓存数据;
- 缓冲池的常见管理算法是LRU,memcache,OS,InnoDB都使用了这种算法;
- InnoDB对普通LRU进行了优化:
- 将缓冲池分为老生代和新生代,入缓冲池的页,优先进入老生代,页被访问,才进入新生代,以解决预读失效的问题
- 页被访问,且在老生代停留时间超过配置阈值的,才进入新生代,以解决批量数据访问,大量热数据淘汰的问题
change buffer
change buffer是InnoDB的写缓冲, 目的是降低写操作的磁盘IO
使用场景
- 适合
对于写多读少的业务来说,页面在写完以后马上被访问到的概率比较小,此时 change buffer 的使用效果最好。这种业务模型常见的就是账单类、日志类的系统 - 不适合
假设一个业务的更新模式是写入之后马上会做查询,那么即使满足了条件,将更新先记录在 change buffer,但之后由于马上要访问这个数据页,会立即触发 merge 过程。这样随机访问 IO 的次数不会减少,反而增加了 change buffer 的维护代价。所以,对于这种业务模式来说,change buffer 反而起到了副作用
样例
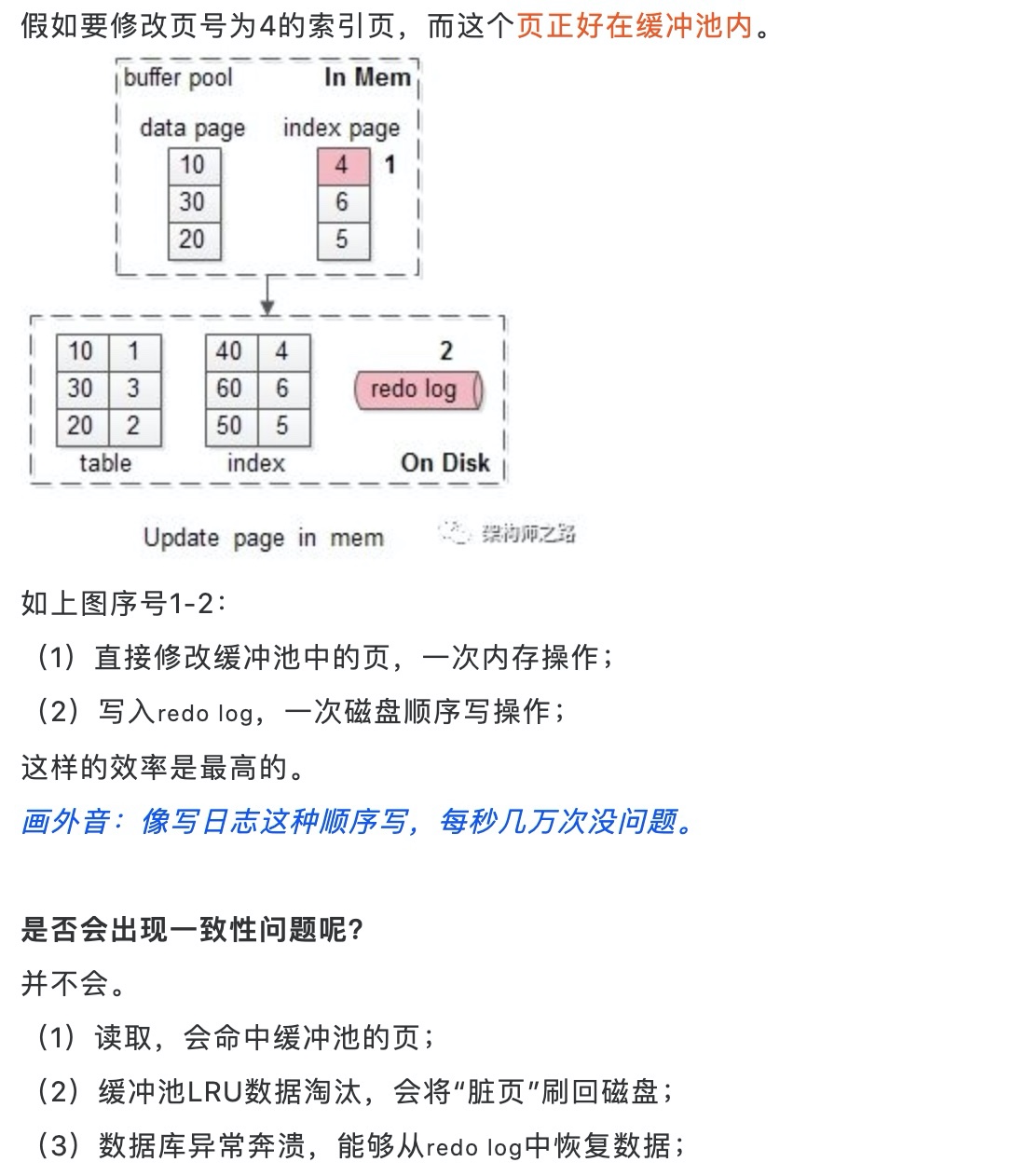
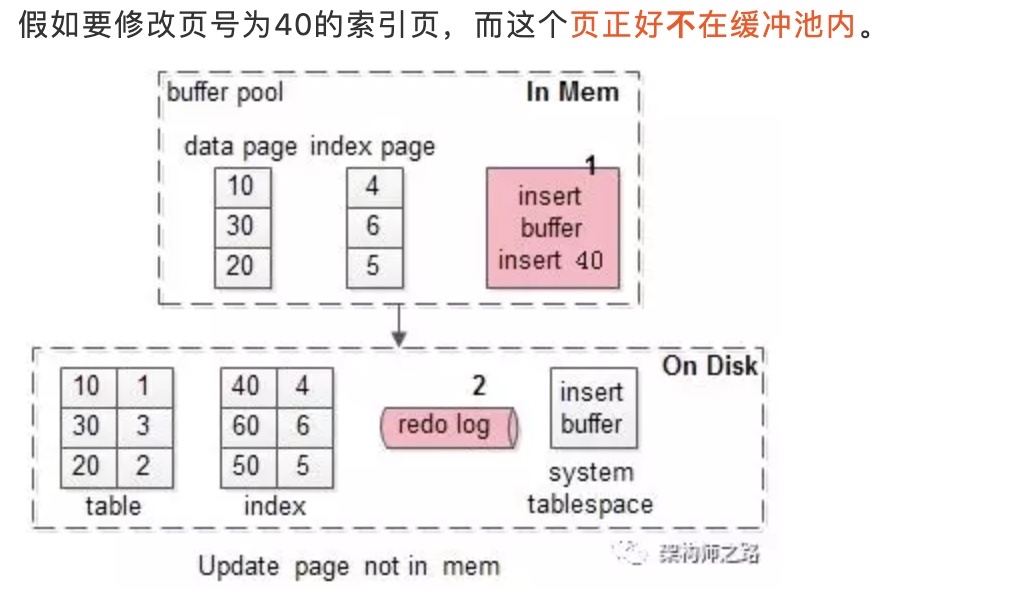
比如要修改页号为40的索引页
1.这个页在buffer pool(缓冲池)中
2.这个页不在buffer pool(缓冲池)中
以上步骤是
- 在change buffer中记录这个操作, 一次内存操作
- 写入redo log, 一次顺序写磁盘操作
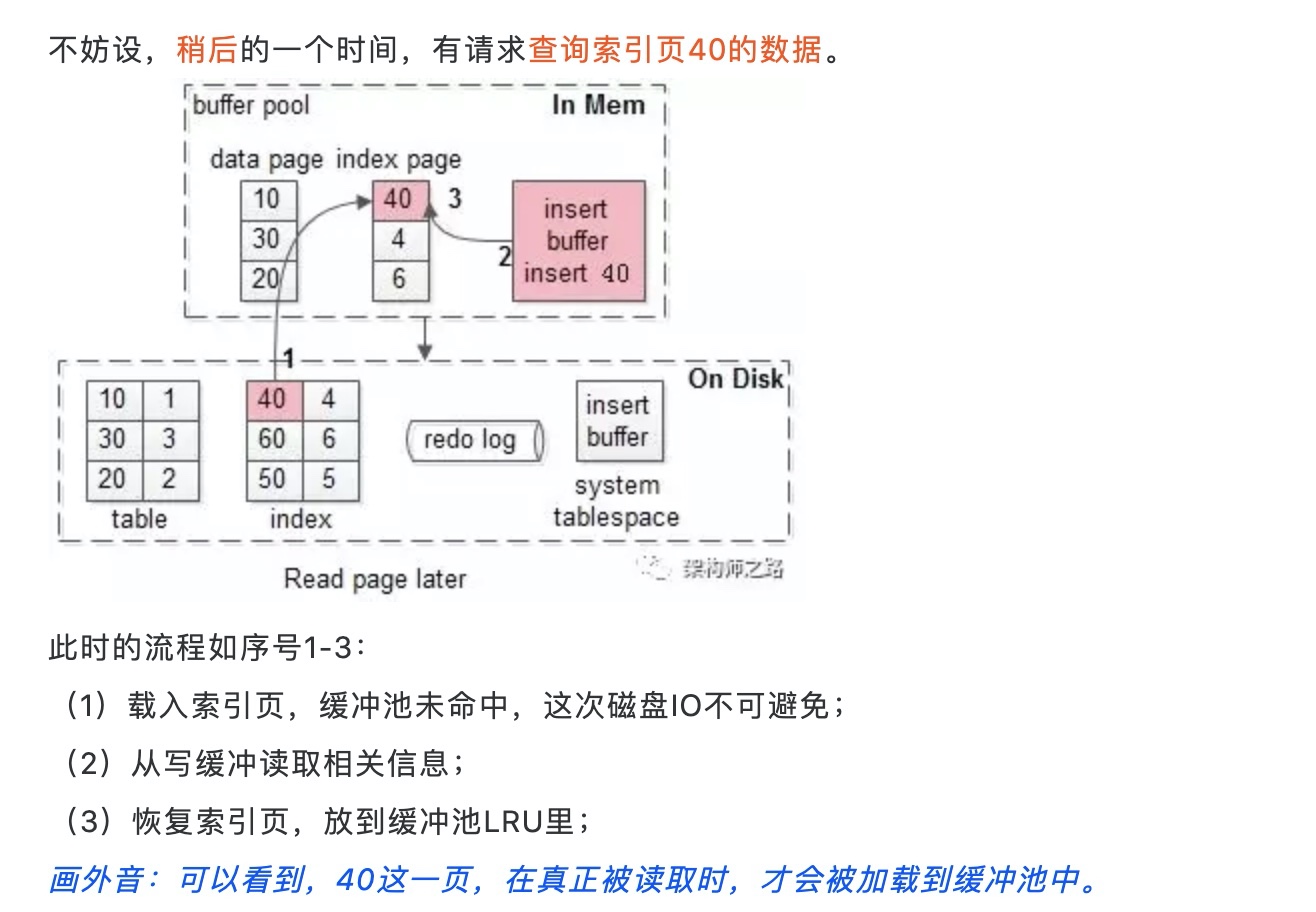
注意以上读取流程, 之前的操作记录只是在change buffer中, buffer poll中并没有, 所以需要从磁盘读取, 然后再从change buffer中读取做merge操作, 再放回去到buffer pool中
change buffer为什么唯一索引不能用?
针对更新操作
- 唯一索引(不能使用)
- 在内存: 直接判断有没有冲突, 没有冲突直接更新到内存. 不使用change buuffer
- 不在内存: 将数据页读入内存(需要从磁盘读出数据来判断),判断到没有冲突. 不使用change buffer
- 普通索引(可以使用)
- 在内存: 直接更新, 不使用change buffer
- 不在内存: 直接将更新记录在change buffer中结束. 使用 change buffer
相关资料
- <<架构师之路>>
- <<MySQL实战45将>>
- 缓冲池(buffer pool),这次彻底懂了!!!
- 写缓冲(change buffer),这次彻底懂了!!!
