从.WAV文件中提取语音的fbank特征
Posted My heart will go ~~
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从.WAV文件中提取语音的fbank特征相关的知识,希望对你有一定的参考价值。
本文的代码的主要作用:截取声音文件的前3.5s,预加重(增大高频部分幅度),分帧(帧长25ms,步长10ms),加窗(汉明窗),FFT(计算的512点的),梅尔滤波器(32维的)最后画图显示代码效果。
每部分的参数都可以进行修改,按照自己的需求进行即可。
import numpy as np
from scipy.io import wavfile
from scipy.fftpack import dct
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
# 绘制时域图
def plot_time(signal, sample_rate):
time = np.arange(0, len(signal)) * (1.0 / sample_rate)
plt.figure(figsize=(20, 5))
plt.plot(time, signal)
plt.xlabel('Time(s)')
plt.ylabel('Amplitude')
plt.grid()
# 绘制频域图
def plot_freq(signal, sample_rate, fft_size=512):
xf = np.fft.rfft(signal, fft_size) / fft_size
freqs = np.linspace(0, int(sample_rate/2), int(fft_size/2 + 1))
xfp = 20 * np.log10(np.clip(np.abs(xf), 1e-20, 1e100))
plt.figure(figsize=(20, 5))
plt.plot(freqs, xfp)
plt.xlabel('Freq(hz)')
plt.ylabel('dB')
plt.grid()
# 绘制频谱图
def plot_spectrogram(spec, note):
fig = plt.figure(figsize=(20, 5))
heatmap = plt.pcolor(spec)
fig.colorbar(mappable=heatmap)
plt.xlabel('Time(s)')
plt.ylabel(note)
plt.tight_layout()
#读取信号
sample_rate, signal = wavfile.read('./李达康.wav')
signal = signal[0: int(3.5 * sample_rate)] # Keep the first 3.5 seconds
#预加重,频谱平衡,增大高频部分的幅度
pre_emphasis = 0.97
emphasized_signal = np.append(signal[0], signal[1:] - pre_emphasis * signal[:-1])
#分帧直接改时间参数就可以
frame_size, frame_stride = 0.025, 0.01
frame_length, frame_step = int(round(frame_size * sample_rate)), int(round(frame_stride * sample_rate))
signal_length = len(emphasized_signal)
num_frames = int(np.ceil(np.abs(signal_length - frame_length) / frame_step)) + 1 #帧数
#处理一下语音方便分帧(后面补上0
pad_signal_length = (num_frames - 1) * frame_step + frame_length
z = np.zeros((pad_signal_length - signal_length))
pad_signal = np.append(emphasized_signal, z) #效果是后面补了80个0
indices = np.arange(0, frame_length).reshape(1, -1) + np.arange(0, num_frames * frame_step, frame_step).reshape(-1, 1)
frames = pad_signal[indices]#在这里完成分帧
#加窗
hamming = np.hamming(frame_length)
# hamming = 0.54 - 0.46 * np.cos(2 * np.pi * np.arange(0, frame_length) / (frame_length - 1))
frames *= hamming
#进行FFT,然后计算能量
NFFT = 512
mag_frames = np.absolute(np.fft.rfft(frames, NFFT))#相当于是进行傅里叶变化。没帧从400个点变成257个点
pow_frames = ((1.0 / NFFT) * (mag_frames ** 2))
#获取fbank特征
low_freq_mel = 0
high_freq_mel = 2595 * np.log10(1 + (sample_rate / 2) / 700)
nfilt = 32 #fbank特征数
mel_points = np.linspace(low_freq_mel, high_freq_mel, nfilt + 2) # 所有的mel中心点,为了方便后面计算mel滤波器组,左右两边各补一个中心点
hz_points = 700 * (10 ** (mel_points / 2595) - 1) #反推计算的频率
fbank = np.zeros((nfilt, int(NFFT / 2 + 1))) # 各个mel滤波器在能量谱对应点的取值
bin = (hz_points / (sample_rate / 2)) * (NFFT / 2) # 各个mel滤波器中心点对应FFT的区域编码,找到有值的位置
for i in range(1, nfilt + 1):
left = int(bin[i-1])
center = int(bin[i])
right = int(bin[i+1])
for j in range(left, center):
fbank[i-1, j+1] = (j + 1 - bin[i-1]) / (bin[i] - bin[i-1])
for j in range(center, right):
fbank[i-1, j+1] = (bin[i+1] - (j + 1)) / (bin[i+1] - bin[i])
filter_banks = np.dot(pow_frames, fbank.T) #数组的点积
filter_banks = np.where(filter_banks == 0, np.finfo(float).eps, filter_banks)#满足条件==0,输出前面的,不满足的输出filter_banks
filter_banks = 20 * np.log10(filter_banks) # dB 取对数,转换成对数fbank特征
plot_spectrogram(filter_banks.T, 'Filter Banks')
实验效果:
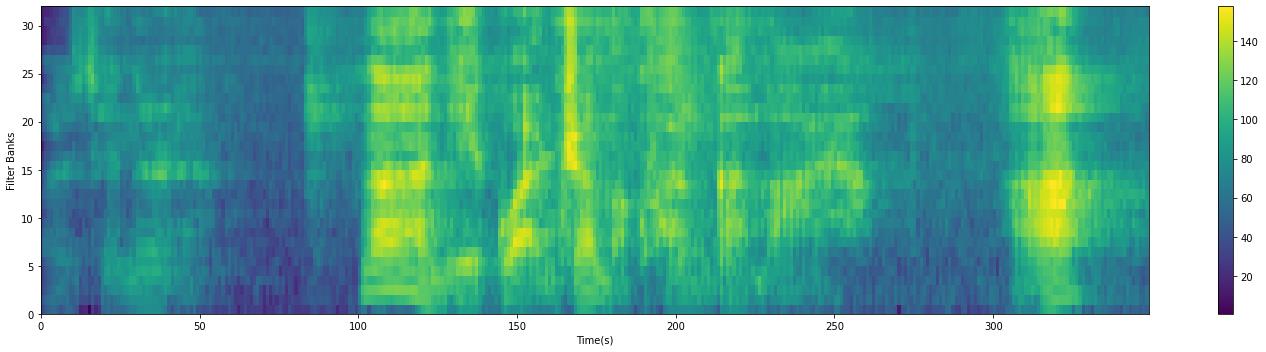
以上是关于从.WAV文件中提取语音的fbank特征的主要内容,如果未能解决你的问题,请参考以下文章