MFCC、FBank、LPC总结
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MFCC、FBank、LPC总结相关的知识,希望对你有一定的参考价值。
参考技术A 几乎照搬 语音特征参数MFCC提取过程详解
参考CSDN 语音信号处理之(四)梅尔频率倒谱系数(MFCC)
1.定义
MFCCs(Mel Frequency Cepstral Coefficents):是在Mel标度频率域提取出来的倒谱参数,是一种在自动语音和说话人识别中广泛使用的特征。Mel标度描述了人耳频率的非线性特性,它与频率的关系可用下式近似表示:
2.流程图
3.预加重
预加重处理其实是将语音信号通过一个高通滤波器:
的取值介于0.9-1.0之间,通常取0.97。
4.分帧
语音信号在宏观上是不平稳的,在微观上是平稳的(傅里叶变换要求输入的信号的平稳的),具有短时平稳性(10---30ms内可以认为语音信号近似不变),因此我们要把语音信号分为一些短段来进行处理,每一个短段称为一帧(CHUNK)。
帧定义为:N个采样点集合成一个观测单位。
通常情况下N的值为256或512,涵盖的时间约为20~30ms左右。为了避免相邻两帧的变化过大,因此会让两相邻帧之间有一段重叠区域,此重叠区域包含了M个取样点,通常M的值约为N的1/2或1/3。通常语音识别所采用语音信号的采样频率为8KHz或16KHz,以8KHz来说,若帧长度为256个采样点,则对应的时间长度是256/8000×1000=32ms。
上面的说法是用采样点来描述的,也有直接用帧长进行描述的,比如:帧长20ms,帧移10ms。
5.加窗
将每一帧乘以汉明窗,以增加帧左端和右端的连续性。
之后我们会对汉明窗中的数据进行FFT,它假设一个窗内的信号是代表一个周期的信号(也就是说窗的左端和右端应该大致能连在一起)。而通常一小段音频数据没有明显的周期性,加上汉明窗后,数据形状就有点周期的感觉了。
汉明窗的公式如下:
通常情况下, 取0.46。
6.FFT
FFT是快速傅里叶变换的缩写。
由于信号在时域上的变换通常很难看出信号的特性,所以通常将它转换为频域上的能量分布来观察,不同的能量分布,就能代表不同语音的特性。所以在乘上汉明窗后,每帧还必须再经过快速傅里叶变换以得到在频谱上的能量分布。对分帧加窗后的各帧信号进行快速傅里叶变换得到各帧的频谱。并对语音信号的频谱 取模平方 得到语音信号的 功率谱 。设语音信号的DFT为:
式中x(n)为输入的语音信号,N表示傅里叶变换的点数。
7.三角带通滤波器
将能量谱通过一组Mel尺度的三角形滤波器组,定义一个有M个滤波器的滤波器组(滤波器的个数和临界 带的个数相近),采用的滤波器为三角滤波器,中心频率为f(m),m=1,2,...,M。M通常取22-26。各f(m)之间的间隔随着m值的减小而缩小,随着m值的增大而增宽,如图所示:
8.每个滤波器组输出
计算每个滤波器组输出的对数能量为:
9.经离散余弦变换(DCT)得到MFCC系数:
10.对数能量
此外,一帧的音量(即能量),也是语音的重要特征,而且非常容易计算。因此,通常再加上一帧的对数能量(定义:一帧内信号的平方和,再取以10为底的对数值,再乘以10)使得每一帧基本的语音特征就多了一维,包括一个对数能量和剩下的倒频谱参数。
因此,MFCC的维度常用的是13(12+1)加上一阶差分和二阶差分,一共39。
11.动态差分参数的提取(包括一阶差分和二阶差分)
标准的倒谱参数MFCC只反映了语音参数的静态特性,语音的动态特性可以用这些静态特征的差分谱来描述。实验证明:把动、静态特征结合起来才能有效提高系统的识别性能。差分参数的计算可以采用下面的公式:
参考 语音识别(五)——Mel-Frequency Analysis, FBank, 语音识别的评价指标, 声学模型进阶
Filter bank和MFCC的计算步骤基本一致,只是没有做IDFT而已。
FBank与MFCC对比:
1.计算量:MFCC是在FBank的基础上进行的,所以MFCC的计算量更大
2.特征区分度:FBank特征相关性较高(相邻滤波器组有重叠),MFCC具有更好的判别度,这也是在大多数语音识别论文中用的是MFCC,而不是FBank的原因
3.使用对角协方差矩阵的GMM由于忽略了不同特征维度的相关性,MFCC更适合用来做特征。
4.DNN/CNN可以更好的利用这些相关性,使用fbank特征可以更多地降低WER。
参考知乎的答案: 语音识别,语谱图对比MFCC、Fbank等特征,在识别方面有哪些优势?
DNN做声学模型时,一般用filterbank feature,不用mfcc,因为fbank信息更多 (mfcc是由mel fbank有损变换得到的)。mfcc一般是GMM做声学模型时用的,因为通常GMM假设是diagonal协方差矩阵,而cepstral coefficient更符合这种假设。linear spectrogram里面冗余信息太多了,维度也高,所以一般也不用。
LPC:Linear Prediction Coefficient线性预测系数。
对语音信号进行线性预测分析的基本思想是:一个语音的采样能够用过去若干个语音采样的线性组合来逼近,通过线性预测到的采样在最小均方误差意义上逼近实际语音采样,可以求取一组唯一的预测系数。预测系数就是线性组合中所用的加权系数,这种线性预测分析最早是用于语音编码中。
MFCC
本总结是是个人为防止遗忘而作,不得转载和商用。
MFCC的分析着眼于人儿的听觉特征,因为人耳所听到的声音的高低与声音的频率不成线性正比关系,而用Mel频率尺度则更符合人耳的听觉特征。
Mel频率尺度:它的值大体上对应于实际频率的对数分布关系,Mel频率与实际频率的具体关系如下:
Mel(f)= 2595lg(1 + f/700),f的单位是Hz。
临界频率带宽随着频率的变化而变化,并与Mel频率的增长一致,在1000Hz下大致呈线性分布,带宽为100Hz左右;在1000Hz以上成对数增长。
类似于临界频带的划分,可以将语音频率划分为一系列三角形的滤波器序列,即Mel滤波器组,如下图:
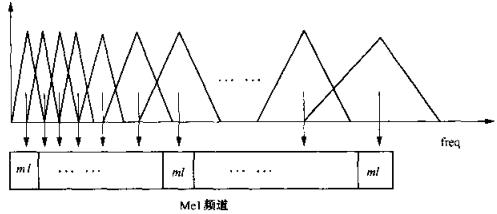
取每个三角形的滤波器频率带宽内所有信号幅度加权和作为某个带通滤波器的输出,然后对所有滤波器输出做对数运算,再进一步做离散余弦变换(DCT)即得到MFCC。
MFCC参数的计算过程的具体步骤如下:
1,根据式Mel(f) =2595lg(1 + f/700),将实际频率尺度转换为Mel频率尺度。
2,在Mel频率轴上配置L个通道的三角形滤波器组,L的个数由信号的截止频率决定。每个三角形滤波器的中心频率c(l)在Mel频率轴上等间隔分配。设o(l)、c(l)、h(l)分别是第l个三角形滤波器的下线、中心和上线频率,则相邻三角形滤波器之间的下限、中心和上线频率有如下图所示

的该关系:c(l) = h(l-1) =o(l+1)
3,根据语音信号幅度谱|Xn(k)|求每个三角形滤波器的输出:

4,对所有滤波器输出做对数运算,再进一步做离散余弦变换(DCT)即可得到MFCC:

PS1:MEL滤波器组也可以其他形状,如正弦形的滤波组等等。
PS2:MEL倒谱提取过程中要进行FFT运算,不过需要注意:若FFT的点数选取过大,则运算复杂度会增大,系统响应时间会变慢,无法满足实时性;反之,可能造成频率分辨率过低,使得提取的参数误差过大。
以上是关于MFCC、FBank、LPC总结的主要内容,如果未能解决你的问题,请参考以下文章