花书笔记 之 Chapter01 引言
Posted 风信子的猫Redamancy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了花书笔记 之 Chapter01 引言相关的知识,希望对你有一定的参考价值。
【花书笔记】 之 Chapter01 引言
让计算机从经验中学习,并根据层次化概念来理解世界。从经验中获取知识,可避免由人类来给计算机形式化地指定所需知识。
层次化的概念让计算机构建简单的概念来学习复杂概念。
这些概念建立在彼此之上的图,很“深”,称为 AI 深度学习 deep learning
一些时间线
IBM的Deep Blue 1997年国际象棋打败世界冠军 Garry Kasparov
抽象和形式化任务对人类而言最为困难,对计算机却很容易
人工智能的挑战 如何将这些非形式化的知识传达给计算机
知识库方法(knowledge base) 将世界的知识用形式化的语言进行硬编码(hard code),计算机使用逻辑推理规则来自动理解形式化语言中的声明
最著名的项目是_Cyc(1989)_ Cyc包含了一个推理引擎和一个使用CycL语言描述的声明数据库。声明是人类监督的
缺点:这是一个笨拙的过程,无法设计出足够复杂的形式化规则来精确描述世界。它的推理引擎可能会有不一致性
机器学习 machine learning 依靠硬编码只是体系面对的困难表明,AI系统需要具有自身获取知识的能力
从原始数据提取模式的能力
引入机器学习使计算机能够解决涉及现实世界知识的问题并能做出看似主观的判断
逻辑回归 logistic regression 决定做不做某事
朴素贝叶斯 native Bayes 可区分垃圾及合法邮件
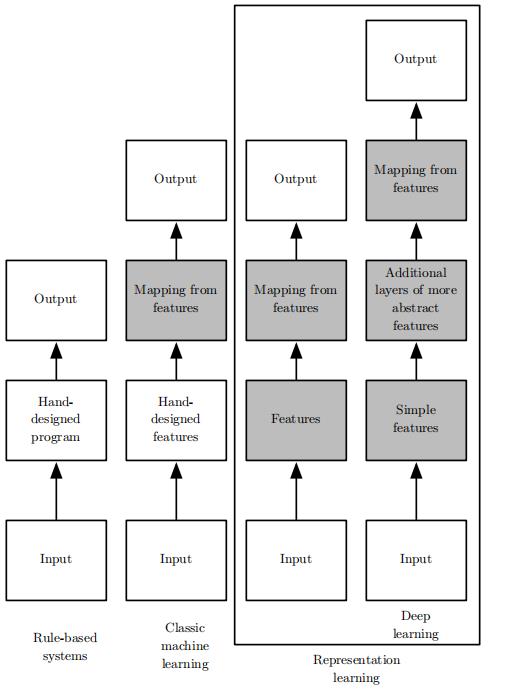
简单的机器学习算法的性能很大程度上依赖于数据的表示representation表示representation
不同的表示方法将会影响算法方式性能
许多人工智能任务可通过以下方式解决先取一个会合适的特征集,将这些特征提供给简单的机器学习算法
然而对于许多任务而言,很难知道应该提取哪些特征
比如车辆可能受光阴影的影响不好表示出提取特征
表示学习 representation learning使用机器学习来发掘表示本身,而不仅仅把表示映射到输出,学习到的表示往往比手动设计表现得更好
典型例子:自编码器 autoencoder
自编码器由一个编码器encoder和一个解码器decoder组成
当设计特征或设计用于学习特征的算法时,目标通常是分离出能解释观察数据的变差因素变差因素 factor of variation
许多现实任务中,困难在于可能多个变差因素同时影响一个观察数据
显然从原始数据中提取高层次、抽象的特征非常困难
深度学习deeplearning通过其他简单的表示来表达复杂表达,解决了表示学习中的核心问题深度学习
深度学习模式典型的例子是前馈深度网络或多层感知机
多层感知机仅仅是将一组输入值映射到输出值的数学函数,该函数由许多简单函数复合而成
学习数据的正确表达的想法是解释深度学习的一个视角,另一个视角是深度促使计算机学习一个多步骤的计算机程序
目前主要有两种度量模型深度的方式目前主要有两种度量模型深度的方式第一种是基于评估架构所需执行的顺序指令的数目,将流程图最长路径视为深度
取决于计算步骤的定义
使用加法乘法和logistic sigmoid作为元素模型深度为3
将逻辑回归视为元素本身模型深度为1
另一种是在深度概率模型中使用的方法,将描述概念彼此如何关联的图的深度视为模型深度
本书面向的读者
- 数学工具和机器学习概念
- 最成熟的深度学习算法
- 展望性的想法
深度学习的历史趋势
神经网络的众多名称和命运变迁
深度学习经历三次发展浪潮
- 20世纪40~60年代 雏形 控制论 cybernetics
- 20世纪80~90年代 联结主义 connectionism
- 2006年 才真正以深度学习之名复兴
最早的一些学习算法,旨在模拟生物学习计算模型即人工神经网络人工神经网络
深度学习的神经观点受两个主要思想启发
- 大脑作为例子证明智能行为是可能的
- 理解大脑和人类智能背后的原理非常有趣
现代术语“深度学习”超越了目前机器学习模型的神经科学观点。它诉诸于学习多层次组合这一更普遍的原理
现代深度学习最早的前身是从神经科学角度出发的简单线性模型
20世纪50年代感知机为第一个能根据每个类别的输入样本来学习权重模型
自适应线性单元简单地返回函数本身的值来预测一个实数,并且它还可以学习从数据预测这些数
用于调节ADALINE权重的训练算法被称为随机梯度下降的一种特例
线性模型的局限性线性模型的局限性无法学习异或函数
联结主义并行处理
联结主义中心思想当网络将大量简单的计算单元连接在一起时可实现的智能行为当网络将大量简单的计算单元连接在一起时可实现的智能行为
分布式表示
思想:系统每一个输入都应该由多个特征表示,并且每一个特征都应该参与到多个可能输入的表示
联结主义潮流的另一个重要成果:反向传播
引入长短期记忆网络
深度信念网络的神经网络可使用一种称为贪婪逐层与训练的策略
与日俱增的数据量
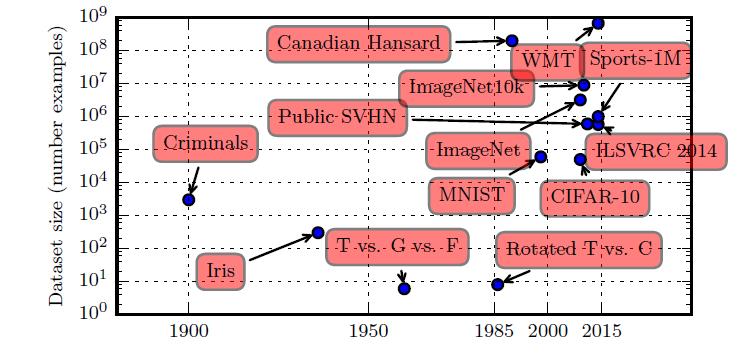
20 世纪初,统计学家使用数百或数千的手动制作的度量来研究数据集(Garson, 1900; Gosset, 1908; Anderson, 1935; Fisher, 1936)。20 世纪50 年代到80 年代,受生物启发的机器学习开拓者通常使用小的合成数据集,如低分辨率的字母位图,设计为在低计算成本下表明神经网络能够学习特定功能(Widrow and Hoff, 1960; Rumelhart et al., 1986b)。
20 世纪80年代和90 年代,机器学习变得更加统计,并开始利用包含成千上万个样本的更大数据集,如手写扫描数字的MNIST 数据集(如图1.9 )所示(LeCun et al., 1998c)。
在21 世纪初的第一个十年,相同大小更复杂的数据集持续出现,如CIFAR-10 数据集(Krizhevsky and Hinton, 2009) 。
在这十年结束和下五年,明显更大的数据集(包含数万到数千万的样例)完全改变了深度学习的可能实现的事。这些数据集包括公共Street View House Numbers 数据集(Netzer et al., 2011)、各种版本的ImageNet 数据集(Deng et al., 2009, 2010a; Russakovsky et al., 2014a) 以及Sports-1M数据集(Karpathy et al., 2014)。在图顶部,我们看到翻译句子的数据集通常远大于其他数据集,如根据Canadian Hansard 制作的IBM 数据集(Brown et al., 1990) 和WMT 2014 英法数据集(Schwenk, 2014) 。
与日俱增的模型规模
最初,人工神经网络中神经元之间的连接数受限于硬件能力。而现在,神经元之间的连接数大多是出于设计考虑。一些人工神经网络中每个神经元的连接数与猫一样多,并且对于其他神经网络来说,每个神经元的连接与较小哺乳动物(如小鼠)一样多是非常普遍的。甚至人类大脑每个神经元的连接也没有过高的数量。
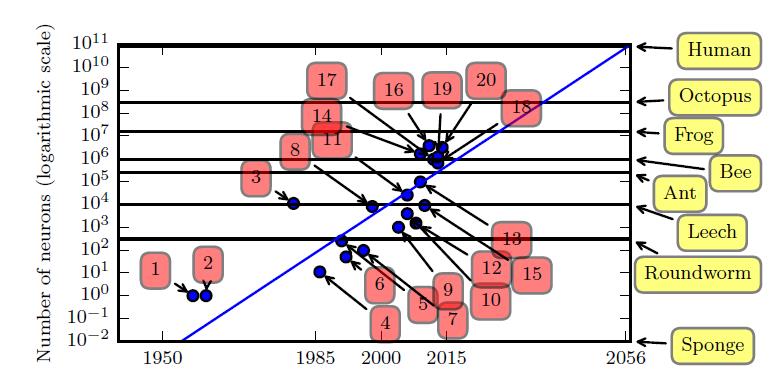
自从引入隐藏单元,人工神经网络的大小大约每2.4 年翻一倍。
- 感知机(Rosenblatt, 1958, 1962)
- 自适应线性单元(Widrow and Hoff, 1960)
- 神经认知机(Fukushima, 1980)
- 早期后向传播网络(Rumelhart et al., 1986b)
- 用于语音识别的循环神经网络(Robinson and Fallside, 1991)
- 用于语音识别的多层感知机(Bengio et al., 1991)
- 均匀场sigmoid信念网络(Saul et al., 1996)
- LeNet-5 (LeCun et al., 1998c)
- 回声状态网络(Jaeger and Haas, 2004)
- 深度信念网络(Hinton et al., 2006a)
- GPU-加速卷积网络(Chellapilla et al., 2006)
- 深度玻尔兹曼机(Salakhutdinov and Hinton, 2009a)
- GPU-加速深度信念网络(Raina et al., 2009a)
- 无监督卷积网络(Jarrett et al., 2009b)
- GPU-加速多层感知机(Ciresan et al., 2010)
- OMP-1 网络(Coates and Ng, 2011)
- 分布式自编码器(Le et al., 2012)
- Multi-GPU卷积网络(Krizhevsky et al., 2012a)
- COTS HPC 无监督卷积网络(Coates et al., 2013)
- GoogLeNet (Szegedy et al., 2014a)
与日俱增的精度、复杂度和对现实世界的冲击
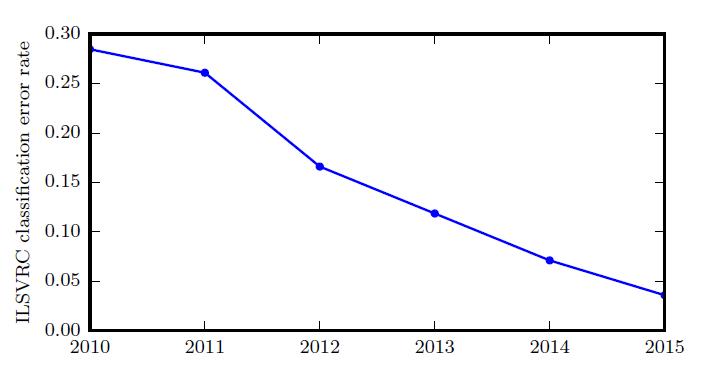
由于深度网络达到了在ImageNet 大规模视觉识别挑战中竞争所必需的规模,它们每年都能赢得胜利,并且产生越来越低的错误率。
以上是关于花书笔记 之 Chapter01 引言的主要内容,如果未能解决你的问题,请参考以下文章