利用jieba库进行词频统计
Posted 算法与编程之美
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了利用jieba库进行词频统计相关的知识,希望对你有一定的参考价值。
0 引言
在读一篇文章和读一本经典名著时,我们常常想统计出来每个词汇出现的次数及该词汇的出现频率,其实我们可以利用Python中的第三方库jieba库来实现。
1 问题
通过对一篇文章和一本书中的词频统计,我们可以知道什么事物或是谁在该文章或该著作作者用了更多的文笔来提到和描述它,
2 方法
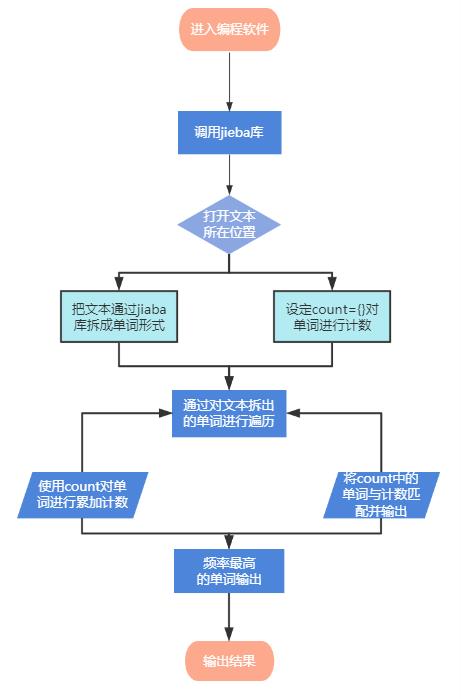
- encoding=’ANSI’:将打开的文本格式设为ANSI形式
- read(size):方法从文件当前位置起读取size个字节,若无参数size,则表示读取至文件结束为止,它范围为字符串对象。
- items = list(counts.items):将counts中的元素存入items表格中。
- key = lambda x:x[1]:等价于 def func(x):
return x[1] - reverse = True:列表反转排序,不写reverse = True 就是列表升序排列,括号里面加上reverse =True 就是降序排列!
- 0:<101:>5: <表示左对齐,>表示右对齐,数字表示宽度,<10表示左对齐,并占10个位置,>5表示右对齐,占5个位置。
3 实验结果与讨论
通过实验、实践等证明提出的方法是有效的,是能够解决开头提出的问题。
代码清单 1
| import jieba txt = open("三国演义.txt", "r", encoding='ANSI').read() words = jieba.lcut(txt) counts = for word in words: if len(word) == 1: continue else: counts[word] = counts.get(word,0) + 1 items = list(counts.items()) items.sort(key=lambda x:x[1], reverse=True) for i in range(15): word, count = items[i] print ("0:<101:>5".format(word, count)) |
4 结语
使用jieba库对一段文本进行词频的统计是一件非常有意思的事,我们只需要使用这第三方库,就可以在不阅读文本的情况下,得到该文本的高频率词汇。但jieba库的作用远远不止于此,它更多的作用等着我们去挖掘。
以上是关于利用jieba库进行词频统计的主要内容,如果未能解决你的问题,请参考以下文章